1880-2010年间全美婴儿姓名数据
美国社会保障总署(SSA)提供了一份从1880年到2010年的婴儿名字频率数据,
由于这是一个非常标准的以逗号隔开的格式,所以可以用pandas.read_csv将
其加载到DataFrame中:
import pandas as pd
names1880 = pd.read_csv('names/yob1880.txt',names=['name','sex','births'])
print(names1880)运行结果:
name sex births
0 Mary F 7065
1 Anna F 2604
2 Emma F 2003
3 Elizabeth F 1939
4 Minnie F 1746
5 Margaret F 1578
6 Ida F 1472
7 Alice F 1414
8 Bertha F 1320
9 Sarah F 1288
10 Annie F 1258
11 Clara F 1226
12 Ella F 1156
13 Florence F 1063
14 Cora F 1045
15 Martha F 1040
16 Laura F 1012
17 Nellie F 995
18 Grace F 982
19 Carrie F 949
20 Maude F 858
21 Mabel F 808
22 Bessie F 796
23 Jennie F 793
24 Gertrude F 787
25 Julia F 783
26 Hattie F 769
27 Edith F 768
28 Mattie F 704
29 Rose F 700
... ... .. ...
1970 Philo M 5
1971 Phineas M 5
1972 Presley M 5
1973 Ransom M 5
1974 Reece M 5
1975 Rene M 5
1976 Roswell M 5
1977 Rowland M 5
1978 Sampson M 5
1979 Samual M 5
1980 Santos M 5
1981 Schuyler M 5
1982 Sheppard M 5
1983 Spurgeon M 5
1984 Starling M 5
1985 Sylvanus M 5
1986 Theadore M 5
1987 Theophile M 5
1988 Tilmon M 5
1989 Tommy M 5
1990 Unknown M 5
1991 Vann M 5
1992 Wes M 5
1993 Winston M 5
1994 Wood M 5
1995 Woodie M 5
1996 Worthy M 5
1997 Wright M 5
1998 York M 5
1999 Zachariah M 5
[2000 rows x 3 columns]这些文件中仅含有当年出现超过5次的名字,为了简单起见,我们可以用births列的sex分组小计表示该年度的births总计:
print(names1880.groupby('sex').births.sum())运行结果是:
sex
F 90993
M 110491
Name: births, dtype: int64由于该数据集按年度被分隔成了多个文件,所以第一件事件就是要将所有数据都组装到一个DataFrame里面,并加上一个year字段,使用pandas.concat即可达到这个目的:
#2010年是目前最后一个有效统计年度
years = range(1880,2011)
pieces = []
columns = ['name','sex','births']
for year in years:
path = 'names/yob%d.txt'%year
frame = pd.read_csv(path,names=columns)
frame['year'] = year
pieces.append(frame)
#将所有数据集合到单个DataFrame中
names = pd.concat(pieces,ignore_index=True)
print(names)运行结果是:
name sex births year
0 Mary F 7065 1880
1 Anna F 2604 1880
2 Emma F 2003 1880
3 Elizabeth F 1939 1880
4 Minnie F 1746 1880
5 Margaret F 1578 1880
6 Ida F 1472 1880
7 Alice F 1414 1880
8 Bertha F 1320 1880
9 Sarah F 1288 1880
10 Annie F 1258 1880
11 Clara F 1226 1880
12 Ella F 1156 1880
13 Florence F 1063 1880
14 Cora F 1045 1880
15 Martha F 1040 1880
16 Laura F 1012 1880
17 Nellie F 995 1880
18 Grace F 982 1880
19 Carrie F 949 1880
20 Maude F 858 1880
21 Mabel F 808 1880
22 Bessie F 796 1880
23 Jennie F 793 1880
24 Gertrude F 787 1880
25 Julia F 783 1880
26 Hattie F 769 1880
27 Edith F 768 1880
28 Mattie F 704 1880
29 Rose F 700 1880
... ... .. ... ...
1691957 Zayshawn M 5 2010
1691958 Zayyan M 5 2010
1691959 Zeal M 5 2010
1691960 Zealan M 5 2010
1691961 Zecharia M 5 2010
1691962 Zeferino M 5 2010
1691963 Zekariah M 5 2010
1691964 Zeriah M 5 2010
1691965 Zeshan M 5 2010
1691966 Zhyier M 5 2010
1691967 Zierre M 5 2010
1691968 Zildjian M 5 2010
1691969 Zimere M 5 2010
1691970 Zinn M 5 2010
1691971 Zishan M 5 2010
1691972 Ziven M 5 2010
1691973 Zmari M 5 2010
1691974 Zoran M 5 2010
1691975 Zoren M 5 2010
1691976 Zuhaib M 5 2010
1691977 Zyeire M 5 2010
1691978 Zygmunt M 5 2010
1691979 Zykerion M 5 2010
1691980 Zylar M 5 2010
1691981 Zylin M 5 2010
1691982 Zymaire M 5 2010
1691983 Zyonne M 5 2010
1691984 Zyquarius M 5 2010
1691985 Zyran M 5 2010
1691986 Zzyzx M 5 2010
[1691987 rows x 4 columns]这里需要注意几件事,第一,concat默认是按行将DataFrame组合到一起的,第二,必须指定ignore_index=True,因为我们不希望保留read_csv所返回的原始行号。现在我们得到了一个非常大的DataFrame,它含有全部的名字数据。
有了这些数据之后,我们就可以利用groupby和pivot_table在year和sex级别上对其进行聚合了
total_births = names.pivot_table('births',index='year',columns='sex',aggfunc=sum)
#tail返回对象的最后n行,默认5行
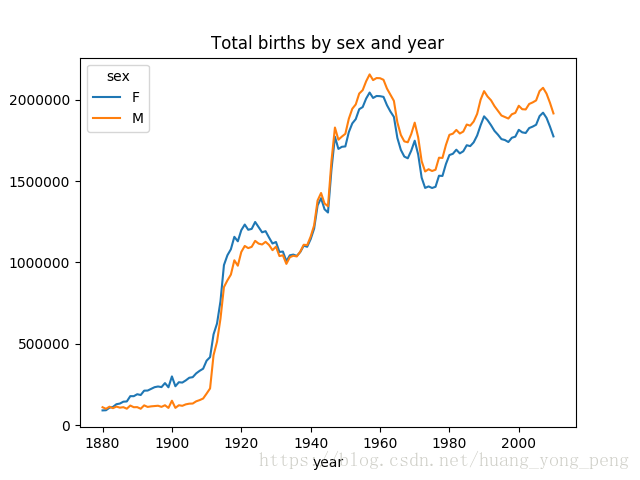
print(total_births.tail())运行结果是:
sex F M
year
2006 1899526 2053406
2007 1920619 2073388
2008 1888607 2037751
2009 1834599 1981039
2010 1774758 1915942import matplotlib.pyplot as plt
total_births.plot(title='Total births by sex and year')
# pandas 数据可以直接观看其可视化形式
plt.show()运行结果是:
下面我们来插入一个prop列,用于存放指定名字的婴儿数相对于总出生数的比例。prop值为0.02表示每100名婴儿中有2名取了当前这个名字。因此,我们先按year和sex分组,然后再讲新列加到各个分组上:
def add_prop(group):
#由于births是整数,所以我们在计算分式时必须将分子或分母转换成浮点数,astype是强转
births = group.births.astype(float)
group['prop'] = births/births.sum()
return group
#apply相当于在原来分组的基础上对其进行了一层函数功能
names = names.groupby(['year','sex']).apply(add_prop)
print(names)运行结果是:
name sex births year prop
0 Mary F 7065 1880 0.077643
1 Anna F 2604 1880 0.028618
2 Emma F 2003 1880 0.022013
3 Elizabeth F 1939 1880 0.021309
4 Minnie F 1746 1880 0.019188
5 Margaret F 1578 1880 0.017342
6 Ida F 1472 1880 0.016177
7 Alice F 1414 1880 0.015540
8 Bertha F 1320 1880 0.014507
9 Sarah F 1288 1880 0.014155
10 Annie F 1258 1880 0.013825
11 Clara F 1226 1880 0.013474
12 Ella F 1156 1880 0.012704
13 Florence F 1063 1880 0.011682
14 Cora F 1045 1880 0.011484
15 Martha F 1040 1880 0.011429
16 Laura F 1012 1880 0.011122
17 Nellie F 995 1880 0.010935
18 Grace F 982 1880 0.010792
19 Carrie F 949 1880 0.010429
20 Maude F 858 1880 0.009429
21 Mabel F 808 1880 0.008880
22 Bessie F 796 1880 0.008748
23 Jennie F 793 1880 0.008715
24 Gertrude F 787 1880 0.008649
25 Julia F 783 1880 0.008605
26 Hattie F 769 1880 0.008451
27 Edith F 768 1880 0.008440
28 Mattie F 704 1880 0.007737
29 Rose F 700 1880 0.007693
... ... .. ... ... ...
1691957 Zayshawn M 5 2010 0.000003
1691958 Zayyan M 5 2010 0.000003
1691959 Zeal M 5 2010 0.000003
1691960 Zealan M 5 2010 0.000003
1691961 Zecharia M 5 2010 0.000003
1691962 Zeferino M 5 2010 0.000003
1691963 Zekariah M 5 2010 0.000003
1691964 Zeriah M 5 2010 0.000003
1691965 Zeshan M 5 2010 0.000003
1691966 Zhyier M 5 2010 0.000003
1691967 Zierre M 5 2010 0.000003
1691968 Zildjian M 5 2010 0.000003
1691969 Zimere M 5 2010 0.000003
1691970 Zinn M 5 2010 0.000003
1691971 Zishan M 5 2010 0.000003
1691972 Ziven M 5 2010 0.000003
1691973 Zmari M 5 2010 0.000003
1691974 Zoran M 5 2010 0.000003
1691975 Zoren M 5 2010 0.000003
1691976 Zuhaib M 5 2010 0.000003
1691977 Zyeire M 5 2010 0.000003
1691978 Zygmunt M 5 2010 0.000003
1691979 Zykerion M 5 2010 0.000003
1691980 Zylar M 5 2010 0.000003
1691981 Zylin M 5 2010 0.000003
1691982 Zymaire M 5 2010 0.000003
1691983 Zyonne M 5 2010 0.000003
1691984 Zyquarius M 5 2010 0.000003
1691985 Zyran M 5 2010 0.000003
1691986 Zzyzx M 5 2010 0.000003
[1691987 rows x 5 columns]按性别和年度统计的总出生数
在执行这样的分组处理时,一般都应该做一些有效性检查,比如验证所有分组的prop总和是否为1。由于这是一个浮点型数据,所以我们应该用np.allclose来检查这个分组总计值是否足够近似于(可能不会精准等于)1:
import numpy as np
#allclose如果两个数组在容差范围内在元素方面相等,则返回True。
k = np.allclose(names.groupby(['year','sex']).prop.sum(),1)
print(k)运行结果是:
True
这样就算完活了。为了便于实现更进异步的分析,我需要取出该数据的一个子集:每队sex/year组合的前1000个名字,这又是一个分组操作:
def get_top1000(group):
return group.sort_values(by='births',ascending=False)[:1000]
top1000 = names.groupby(['year','sex']).apply(get_top1000)
print(top1000)运行结果是:
name sex births year prop
year sex
1880 F 0 Mary F 7065 1880 0.077643
1 Anna F 2604 1880 0.028618
2 Emma F 2003 1880 0.022013
3 Elizabeth F 1939 1880 0.021309
4 Minnie F 1746 1880 0.019188
5 Margaret F 1578 1880 0.017342
6 Ida F 1472 1880 0.016177
7 Alice F 1414 1880 0.015540
8 Bertha F 1320 1880 0.014507
9 Sarah F 1288 1880 0.014155
10 Annie F 1258 1880 0.013825
11 Clara F 1226 1880 0.013474
12 Ella F 1156 1880 0.012704
13 Florence F 1063 1880 0.011682
14 Cora F 1045 1880 0.011484
15 Martha F 1040 1880 0.011429
16 Laura F 1012 1880 0.011122
17 Nellie F 995 1880 0.010935
18 Grace F 982 1880 0.010792
19 Carrie F 949 1880 0.010429
20 Maude F 858 1880 0.009429
21 Mabel F 808 1880 0.008880
22 Bessie F 796 1880 0.008748
23 Jennie F 793 1880 0.008715
24 Gertrude F 787 1880 0.008649
25 Julia F 783 1880 0.008605
26 Hattie F 769 1880 0.008451
27 Edith F 768 1880 0.008440
28 Mattie F 704 1880 0.007737
29 Rose F 700 1880 0.007693
... ... .. ... ... ...
2010 M 1678701 Lathan M 203 2010 0.000106
1678702 Ronaldo M 203 2010 0.000106
1678703 Yair M 203 2010 0.000106
1678705 Keyon M 202 2010 0.000105
1678706 Reagan M 202 2010 0.000105
1678704 Gibson M 202 2010 0.000105
1678710 Yehuda M 201 2010 0.000105
1678709 Talan M 201 2010 0.000105
1678708 Kingsley M 201 2010 0.000105
1678707 Daylen M 201 2010 0.000105
1678711 Cristofer M 200 2010 0.000104
1678712 Dashawn M 200 2010 0.000104
1678713 Jordon M 200 2010 0.000104
1678714 Sheldon M 200 2010 0.000104
1678715 Slade M 200 2010 0.000104
1678716 Clarence M 199 2010 0.000104
1678717 Dillan M 199 2010 0.000104
1678718 Kadin M 199 2010 0.000104
1678719 Masen M 199 2010 0.000104
1678720 Rowen M 199 2010 0.000104
1678723 Yousef M 198 2010 0.000103
1678722 Thaddeus M 198 2010 0.000103
1678721 Clinton M 198 2010 0.000103
1678724 Truman M 197 2010 0.000103
1678725 Bailey M 196 2010 0.000102
1678726 Destin M 196 2010 0.000102
1678727 Eliezer M 196 2010 0.000102
1678728 Enoch M 196 2010 0.000102
1678729 Joziah M 196 2010 0.000102
1678730 Keshawn M 196 2010 0.000102
[261877 rows x 5 columns]分析命名趋势
y有了完整的数据集和刚才生成的top1000数据集,我们就可以开始分析命名趋势了。首先将前1000个名字分为男女俩部分:
boys = top1000[top1000.sex == 'M']
girls = top1000[top1000.sex == 'F']这是两个简单的时间序列,只需稍作整理即可绘制出相应的图表。我们先生成一张按year和name统计的总出生数透视表:
total_births = top1000.pivot_table('births',index = 'year',columns='name',aggfunc=sum)
print(total_births)现在,我们用DataFrame的plot方法绘制几个名字的曲线图:
subset = total_births[['John','Harry','Mary','Marilyn']]
#subplots boolean, default False,为每一列单独画一个子图
#grid boolean,默认为None,使用matlab样式
subset.plot(subplots = True,figsize = (12,10),grid=False,title = 'Number of births per year')
plt.show()运行结果是:
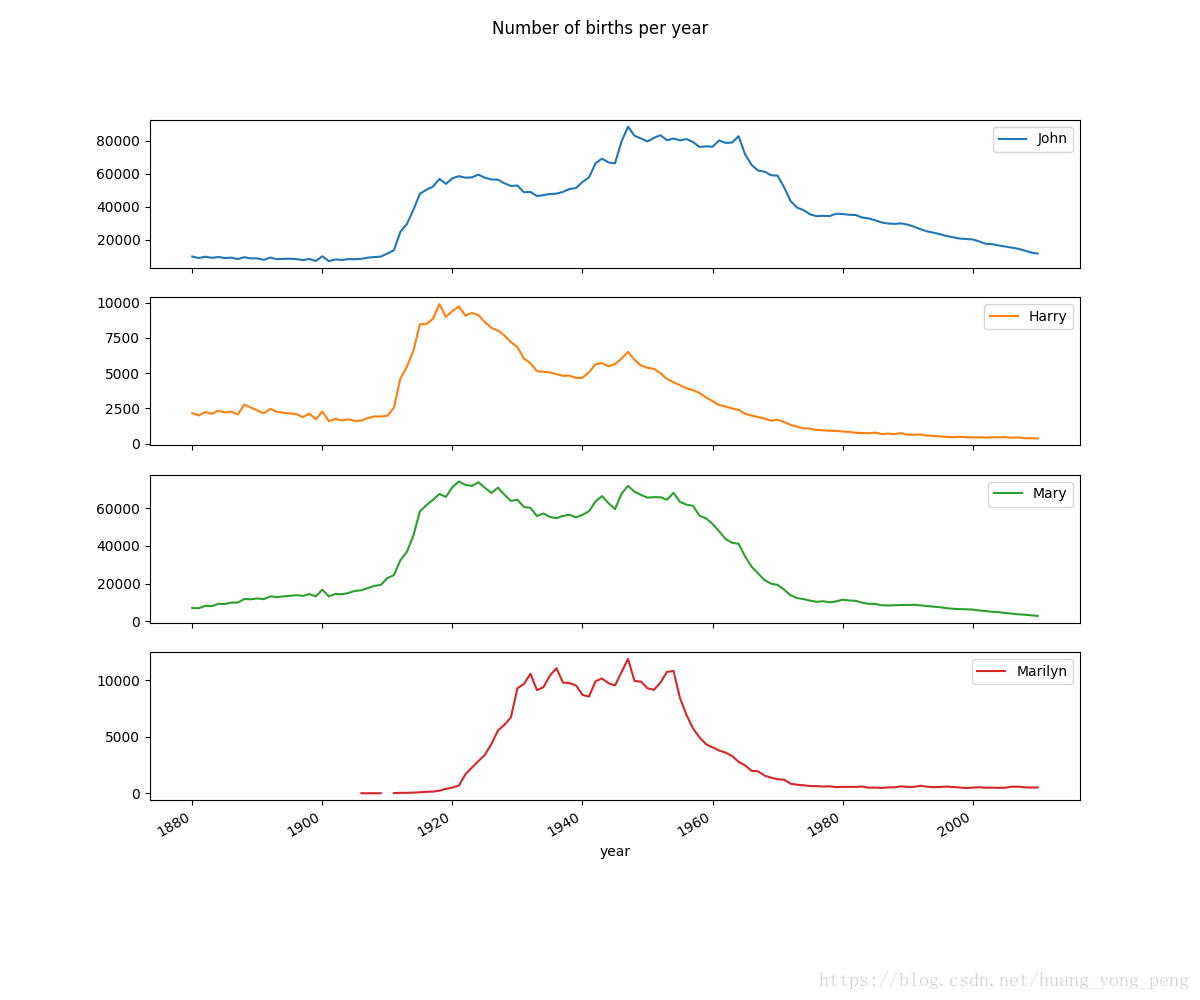
从图中可以看出,这几个名字在美国人民心目中风光不在了。但事实并非如此简单
评估命名多样性的增长
上图反映的降低情况可能意味着父母愿意给小孩起常见的名字越来越少,这个假设可以从数据中得到验证。一个办法是计算最流行的1000个名字所占的比例,我按year和sex进行聚合并绘图:
table = top1000.pivot_table('prop',index='year',columns='sex',aggfunc=sum)
#yticks sequence,y轴刻度标签
#linspace()后面三个参数分别是开始,结束,个数
table.plot(title='Sum of top1000.prop by year and sex',yticks=np.linspace(0,1.2,13),xticks=range(1880,2020,10))
plt.show()运行结果如图所示:
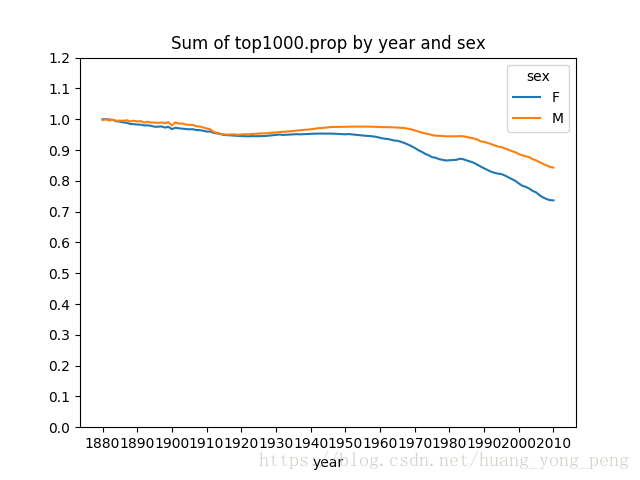
从图中可以看出,名字的多样性确实出现了增长。
分性别统计的前1000个名字在总出生人数中的比例
在对prop降序排列之后,我们想知道前面多少个名字的人数加起来才够50%.虽然编写一个for循环确实也能达到目的,但NumPy有一种更聪明的矢量方式,先计算prop的累计和cumsum,然后通过searchsorted方法找出0.5应该被插入在哪个位置才能保证不破坏顺序:
df = boys[boys.year==2010]
#cumsum方法是用来累加的
prop_cumsum = df.sort_values(by='prop',ascending=False).prop.cumsum()
print(prop_cumsum.searchsorted(0.5))运行结果是:
[116]
由于数组索引是从0开始的,因此结果要加1,所有是117
现在就可以对所有year/sex组合执行这个计算了,按这两个字段进行groupby处理,然后用一个函数计算各分组的这个 值:
def get_quantile_count(group,q=0.5):
group = group.sort_values(by='prop',ascending=False)
return group.prop.cumsum().searchsorted(q)+1
diversity = top1000.groupby(['year','sex']).apply(get_quantile_count)
diversity = diversity.unstack('sex')
print(diversity)运行结果是:
sex F M
year
1880 [38] [14]
1881 [38] [14]
1882 [38] [15]
1883 [39] [15]
1884 [39] [16]
1885 [40] [16]
1886 [41] [16]
1887 [41] [17]
1888 [42] [17]
1889 [43] [18]
1890 [44] [19]
1891 [44] [20]
1892 [44] [20]
1893 [44] [21]
1894 [45] [22]
1895 [46] [22]
1896 [46] [23]
1897 [46] [23]
1898 [47] [24]
1899 [47] [25]
1900 [49] [25]
1901 [49] [25]
1902 [49] [26]
1903 [49] [27]
1904 [50] [28]
1905 [50] [28]
1906 [49] [28]
1907 [50] [30]
1908 [49] [30]
1909 [49] [30]
... ... ...
1981 [78] [35]
1982 [75] [35]
1983 [71] [34]
1984 [71] [35]
1985 [72] [36]
1986 [74] [38]
1987 [75] [39]
1988 [78] [40]
1989 [83] [43]
1990 [90] [45]
1991 [95] [48]
1992 [102] [51]
1993 [107] [54]
1994 [112] [57]
1995 [115] [60]
1996 [122] [64]
1997 [129] [67]
1998 [138] [70]
1999 [146] [73]
2000 [155] [77]
2001 [165] [81]
2002 [170] [83]
2003 [179] [87]
2004 [191] [92]
2005 [199] [96]
2006 [209] [99]
2007 [223] [103]
2008 [234] [109]
2009 [241] [114]
2010 [246] [117]
[131 rows x 2 columns]
现在,diversity这个DataFrame拥有两个时间序列(每个性别各一个,按年度索引)。我们还可以通过像之前那样绘制图表:
diversity.plot(title='Number of popular names in top 50%')
plt.show()运行结果如图所示:
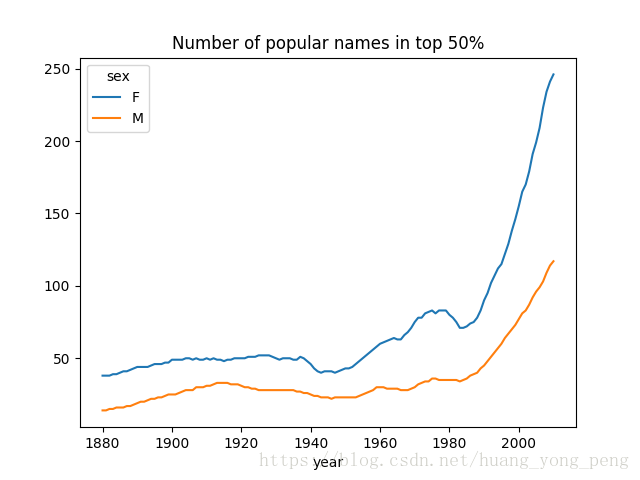
从图中可以看出,女孩子名字的多样性总是比男孩的高,而且还是变得越来越高
“最后一个字母”的变革
有人指出:
近百年来,男孩名字在最后一个字母上的分布发生了显著的变化。为了了解具体的情况,首先将全部出生数据在年度,性别以及末字母上进行了聚合:
#从name列取出最后一个字母
get_last_letter = lambda x:x[-1]
last_letters = names.name.map(get_last_letter)
last_letters.name = 'last_letter'
table = names.pivot_table('births',index=last_letters,columns=['sex','year'],aggfunc=sum)
subtable = table.reindex(columns=[1910,1960,2010],level='year')
print(subtable.head())运行结果是:
sex F M
year 1910 1960 2010 1910 1960 2010
last_letter
a 108397.0 691250.0 676646.0 977.0 5212.0 28859.0
b NaN 694.0 455.0 411.0 3914.0 39264.0
c 5.0 49.0 955.0 482.0 15460.0 23341.0
d 6751.0 3730.0 2640.0 22113.0 262136.0 44817.0
e 133600.0 435043.0 316665.0 28665.0 178785.0 130228.0
接下来我们需要按总出生数对该表进行规范化处理,以便计算出各性别各末字母占总出生人数的比例:
letter_prop = subtable/subtable.sum().astype(float)
print(letter_prop)有了这个字母比例数据之后,就可以生成一张各年度各性别的条形图:
#可以产生2x1个子窗口,数据以数组形式保存在axes中,fig依然是一个图像对象
fig,axes = plt.subplots(2,1,figsize=(10,8))
letter_prop['M'].plot(kind='bar',rot=0,ax=axes[0],title='Male')
letter_prop['F'].plot(kind='bar',rot=0,ax=axes[1],title='Female',legend=False)
plt.savefig('shuju5')
plt.show()运行结果如图所示:
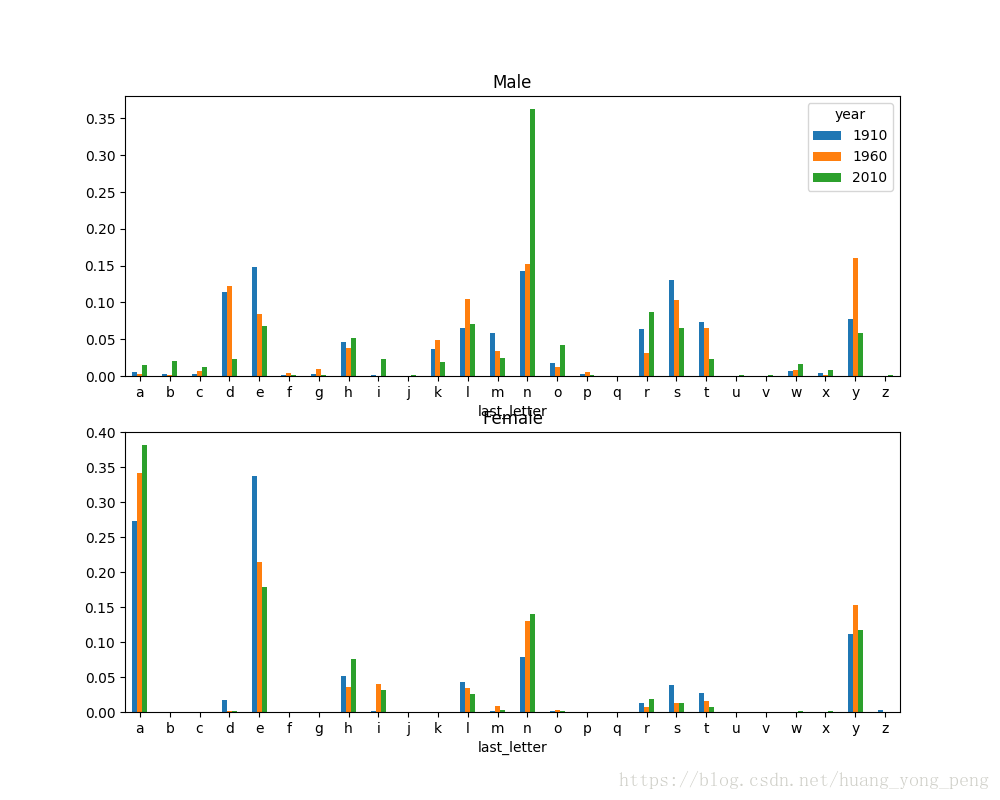
从图中可以看出,从20世纪60年代开始,以字母‘n’结尾的男孩名字出现了显著的增长。回到之前创建的那个完整表,按年度和性别对其进行规范化处理,并在男孩名字中选取几个字母,最后进行转置以便将各个列做成一个时间序列:
#T装置索引和列
dny_ts = letter_prop.ix[['d','n','y'],'M'].T
print(dny_ts.head())运行结果是:
last_letter d n y
year
1910 0.113860 0.143384 0.077343
1960 0.122932 0.152525 0.160976
2010 0.023392 0.362438 0.058182有了这个时间序列的DataFrame之后,就可以通过其plot方法绘制处一张趋势图了:
dny_ts.plot()
plt.savefig('shuju6')
plt.show()如图所示:
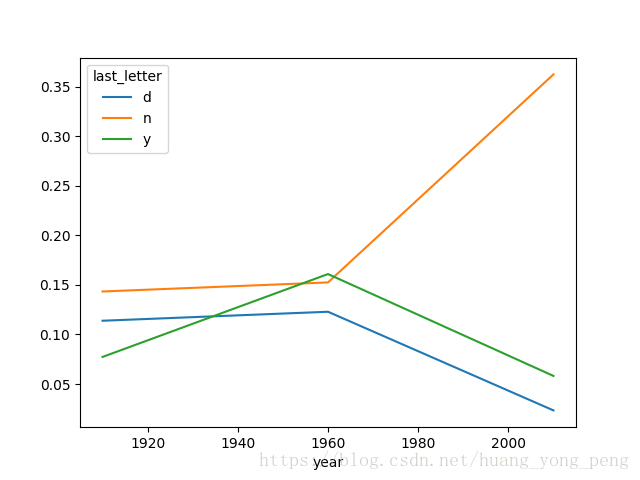
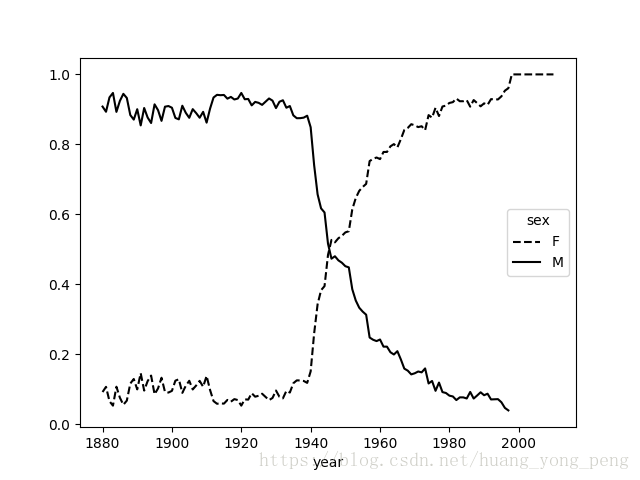
变成女孩名字的男孩名字(以及相反的情况)
另一个更有趣的趋势是,早年流行于男孩的名字今年来‘变形了’,例如Lesley或Leslie回到top1000数据集,找出其中以”lesl“开头的一组名字:
all_name = top1000.name.unique()
mask = np.array(['lesl' in x.lower() for x in all_name])
lesley_like = all_name[mask]
print(lesley_like)运行结果如下:
[‘Leslie’ ‘Lesley’ ‘Leslee’ ‘Lesli’ ‘Lesly’]
然后利用这个结果过滤其他的名字,并按名字分组计算出生数以查看相对频率:
filtered = top1000[top1000.name.isin(lesley_like)]
print(filtered.groupby('name').births.sum())运行结果是:
name
Leslee 993
Lesley 35032
Lesli 929
Leslie 370560
Lesly 10072
Name: births, dtype: int64接下来,我们按性别和年度进行聚合,并按年度进行规范化处理:
table = filtered.pivot_table('births',index='year',columns='sex',aggfunc=sum)
table = table.div(table.sum(1),axis=0)
print(table.tail())
运行结果:
sex F M
year
2006 1.0 NaN
2007 1.0 NaN
2008 1.0 NaN
2009 1.0 NaN
2010 1.0 NaN现在,我们就可以轻松绘制一张分性别的年度曲线图:
table.plot(style={'M':'k-','F':'k--'})
plt.savefig('shuju7')
plt.show()如图所示: