HBase写流程
假如说我们要插入一条数据到某个表里面,会经历的过程如下图:
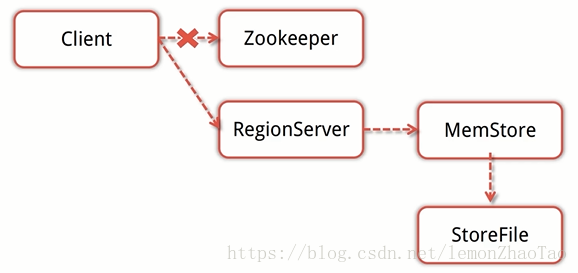
概述
-
Client会先访问zookeeper,得到对应的RegionServer地址
-
Client对RegionServer发起写请求,RegionServer接受数据写入内存
-
当MemStore的大小达到一定的值后,flush到StoreFile并存储到HDFS
详细流程
-
Client首先会去访问Zookeeper,从Zookeeper里面去获取表的相关信息以及表的region的相关信息,根据我们要插入的RowKey去获取指定的RegionServer的信息(如果是批量提交的话,会把RowKey根据HRegionLocation进行分组)
-
当我们得到了需要访问的RegionServer之后,Client就会向对应的RegionServer发起写请求;RegionServer收到请求之后,会执行各种的检查操作:比如会看下对应的Region是否处于只读状态、MemoryStore大小是否超过了BlockingMemoryStoreSize等等
-
检查完成之后进行真正的数据写入操作,RegionServer依次将数据写入到MemStore和HLog,只有这两者都写入成功之后,此次写入才算成功
-
整个过程比较复杂,需要去获取到相关的锁,写入到MemStore和HLog是事务型操作,要么全部写入成功要么就是失败
-
当MemStore达到我们设定的阈值之后,会将MemStore中的数据flush成StoreFile文件;当StoreFile文件增加到一定数量的时候,会触发compact合并机制,将多个StoreFile文件合并成一个大的StoreFile文件;如果单个StoreFile文件达到一定的阈值,会触发spilt机制,将Region一分为二,然后HMaster给2个region分配相应的RegionServer进行管理,从而分担压力
剖析RegionServer内部
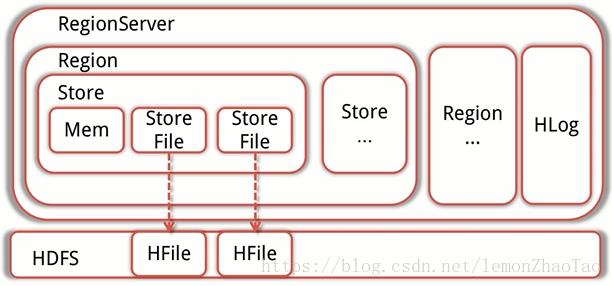
-
RegionServer处理数据的输入输出请求,同时每个RegionServer管理着多个Region
每个RegionServer都有对应的HLog实例 -
Region是HBase存储的基本单元,数据都存储在Region当中
每一个Region只存储一个ColumnFamily的数据,且只是这个ColumnFamily的一部分
当Region的大小达到某个阈值之后,会根据RowKey的排序划分为多个Region -
而每个Region里面又包含了多个Store
每一个Store里面包含了1个MemStore和1个或是多个StoreFile
MemStore便是数据在内存中的实体,而且有序 -
当有数据写入的时候,会先写入到MemStore,当MemStore的大小达到上限之后
Store会去创建StoreFile(这里的StoreFile是HFile的一层封装;HBase依赖于HDFS,HFile存储在HDFS上)
因此MemStore的数据最终会写入到HFile之中 -
那么HBase如何保证MemStore中的数据不会丢失呢?
HLog就是WAL的一种实现,WAL是预写日志,是事务机制中常见的一致性的实现方式对于每个RegionServer,都会有一个HLog的实例,RegionServer会将更新操作记录到MemStore,然后再更新到HLog当中,只有当HLog更新完成之后,这条记录才算真正成功的写入;这样,即使MemStore中的数据丢失了,还是可以通过HLog找回来 -
一般的WAL是先写入日志,再写入内存的
而对于HBase是先写入内存再写入日志,依托于MVCC模式确保一致性 -
如果HFile丢失了怎么办?
HFile是存储在HDFS上的,默认的备份是3份,所以这里并不考虑HFile丢失的可能性
HBase读流程
概述
-
Client会先访问zookeeper,得到对应的RegionServer地址
-
Client对RegionServer发起读请求
-
当RegionServer收到client的读请求后,先扫描自己的Memstore,再扫描BlockCache(加速内容缓存区)如果还没找到则StoreFile中读取数据,然后将数据返回给Client
详细流程
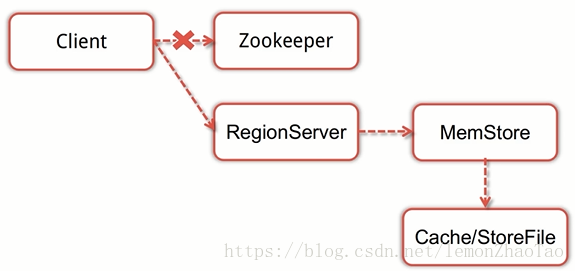
-
Client与Zookeeper建立连接
-
然后通过Zookeeper访问meta,将HBase的meta表缓存到本地
-
通过缓存的meta表,获取要访问的表所对应的RegionServer的信息
-
当Client知道要访问的表在哪个RegionServer之后,Client就向对应的RegionServer发起读请求,RegionServer获取到请求并进行复杂的处理之后,就会将数据返回给客户端
-
那么RegionServer具体做哪些事情呢?
首先RegionServer先扫描自己的MemStore
如果没有找到数据再扫描BlockCache
如果还没有找到的话,就去StoreFile里面查找数据,最后将这条数据返回给Client
关于HBase读写流程的注意点
通过读和写的流程我们可以发现与HMaster没有一点关系,Client请求数据的时候只需要知道Zookeeper的地址就可以了(这部分与HMaster没有关系,也不需要提前知道RegionServer的IP)
那么为什么Client只需要访问Zookeeper就可以了呢?
因为HMaster在启动的时候会将meta的信息加载到Zookeeper,这个表里面存储了HBase里面所有的表、所有的Region的详细信息
比如说:Region开始的key、结束的key;所在的RegionServer的地址等等
HBase的meta表此刻就相当于是一个目录,通过它可以快速的定位到数据的实际位置
因此读写操作只需要与Zookeeper、以及对应的RegionServer交互就可以了,而HMaster只需要维护table和region的元数据信息、协调各个RegionServer就行了,所以它的负载就小了很多
HBase模块协作
HBase启动时发生了什么
-
HMaster启动,注册到Zookeeper,等待RegionServer汇报
注册的时候首先将自己注册到backup mater节点
这样做的原因是,因为我们可能有很多个master,最终的active master是要看它们抢占的速度的,所以说它们默认的会先写入到backup master节点,如果它们抢占到锁之后,成为active状态,然后将自己从backup master中去删除;只有在成为active master之后,才会去实例化一些相关的类;当master节点成功的转变成为active状态之后,这时候它就会去等待RegionServer节点向他进行报告 -
RegionServer注册到Zookeeper,并向HMaster汇报
-
HMaster对各个RegionServer(包括失效的)的数据进行整理,分配Region和meta信息
当所有的数据整理完全之后,整理的是一张meta表(表里记录的是所有表相关的region信息、各个RegionServer负责的是哪些数据等等),之后就将meta表交给Zookeeper -
Backup master会定期地从active master处保持数据的更新,从而保障自己的meta表是最新的
-
RegionServer在启动之后,且正式的注册进集群之后,有很多工作要做,比如:设置WAL预写日志相关的一些信息、定期的去刷新MemStore保证最终的数据写入到HFile文件等等
当RegionServer失效后发生什么
-
Zookeeper感知到后会向HMaster汇报,然后HMaster会将失效的RegionServer从meta表中删除,同时将RegionServer上的Region分配到其它节点
-
HMaster更新hbase:meta表以保证数据正常访问
当HMaster失效后会发生什么
-
配置了HA:
处于Backup状态的其它HMaster节点推选出一个转为Active状态 -
没有配置HA:
该读取数据还是需要读取,该写入数据还是需要写入
但是像新建表、修改表结构,是不能操作的,会抛出异常
数据能正常读写,但是不能创建删除表,也不能更改表结构(因为这些操作会涉及到meta表的更新,而HMaster是处于失效的状态,因此是不能操作的)