【HBase-读写流程】HBase的读写流程与内部执行机制
1)HBase 读取数据流程
1.1.文字描述
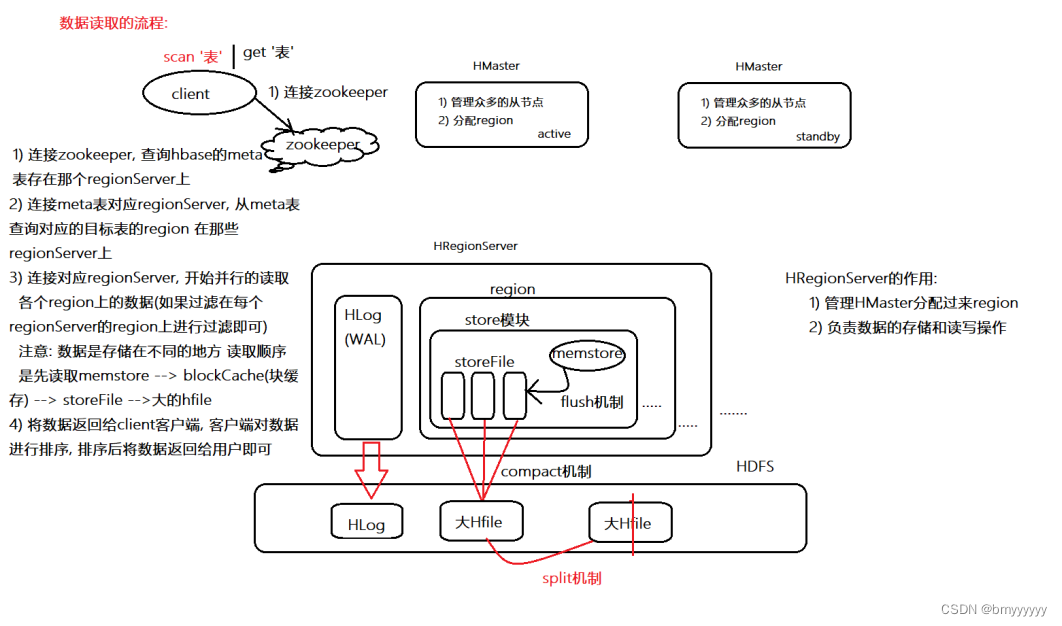
1、客户端发起读取数据的请求,然后首先要连接 zookeeper,通过 zookeeper 去找到 HBase 中的 meta 文件对应 region 所对应的 regionserver 的地址。
此时注意:
-
如果是用 scan 发起的全局扫描,那么就会在 meta 文件中找到表中所有数据对应的所有的 region,并且返回所有 region 对应的所有的 regionserver 的地址。
-
如果是用 get 发起的局部扫描,那么就会在 meta 文件中找到要搜索数据的 rowkey 对应的 region 所对应的 regionserver 的地址。
2、此时开始并发连接 regionserver,首先要读取 memstore 中的数据,然后读取块缓存中的数据,其次读取小的 storefile 中的数据,最后读取大的 HFile 中的数据。
3、客户端读取完数据后,将读取的数据进行排序,展示给用户。
注意:
如果在读取数据的时候,有过滤的信息,那么这些过滤条件会被分发到对应的region上,由各个region进行相关的过滤
1.2.流程图
2)HBase 写入数据流程
2.1.文字描述
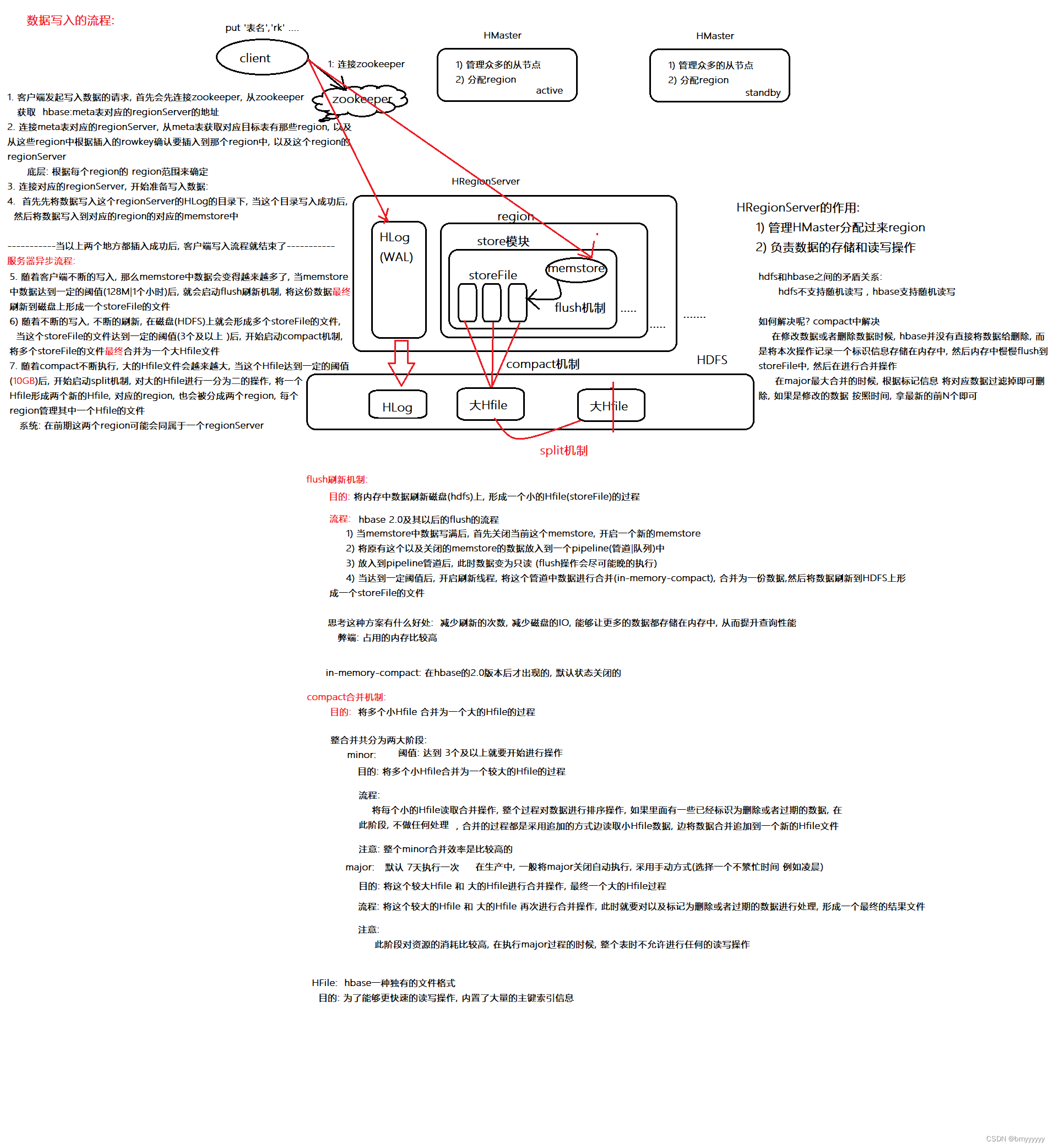
(1)客户端:
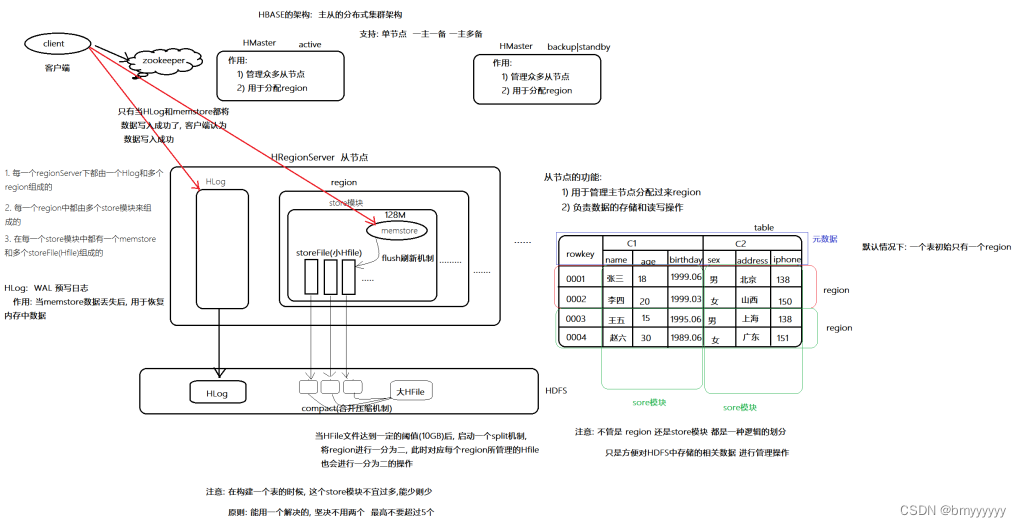
1、客户端发起写入数据的请求,然后首先要连接 zookeeper,通过 zookeeper 去找到 HBase 中的 meta 文件对应的 region 所对应的 regionserver 的地址,连接 meta 文件所在的 regionserver,通过要写入数据的 rowkey,找到 rowkey 对应的 region(底层是根据 region 的范围去寻找的),然后找到 region 对应的 regionserver 的地址。
2、客户端开始连接 regionserver,首先要把数据写入到 regionserver 中的 HLog 目录中,当数据在 HLog 目录中写完之后,开始写入到 region 下的 memstore 中,当写入完成后,此时客户端的写入工作就成功了。
(2)服务端:
3、不断的写入数据,当 memstore 内存中的数据达到一定的阈值之后(默认是128M),就会开启 flush 机制,把 memstore 中的数据刷新到磁盘上,形成一个 storeFile 文件,不断的写入,在磁盘上就会形成多个 storeFile 文件,当 storeFile 文件达到一定的阈值之后(默认是三个),就会开始 compact 机制,把 storeFile 文件合并成为一个大的 HFile 文件,不断地合并,当这个 HFile 文件达到一定的阈值之后(10G),就会开启一个 split 机制,将这个 HFile 文件进行切割,形成两个 HFile 文件。
注意:
HFile 对应的 region,也会一分为二,起初这两个 region 可能会被同一个 regionserver 所管理,但是随着时间的推移可能会被不同的 regionserver 所管理。
2.2.流程图
3)flush 机制与 compact 机制的原理
3.1.文字描述
(1)flush机制:
1、数据不断的写入,当 memstore 达到一定的阈值之后,就会将当前这个 memstore 关闭,然后开启一个新的memstore继续写入数据。
2、这个关闭的 memsotre 会被放置到一个 pipeline 管道中,也就是一个队列管道,管道中的 memstore 并不会直接进行 flush 刷新机制,而是会先等待,在等待的过程中,可能还会有 memstore 被放置在 pipeline 管道中,当达到一定的阈值后(这个阈值和服务器的内存有关),就会开启 flush 机制。
3、开启flush机制,将管道中的所有 memstore 进行一个 in-memory-compact,合并成为一个 storeFile 文件,放置到 HDFS 磁盘上。
注意:
这种 flush 的好处是,减少 flush 的次数,从而减少大量的磁盘 I/O 次数,并且让更多的数据存储在内存中,加快查询数据的效率。
(2)compact机制:
4、数据不断的写入形成多个 storeFile 文件,当达到一定的阈值之后(默认是3个),就会开启 compact 机制。
此时 compact 的机制会被分为两个部分:
① minor:
这个部分就是将多个 storeFile 文件合并成为一个较大的 HFile 文件的过程。
每小时都会对 storeFile 进行一个合并的操作,但是这个合并过程中只对数据进行一个排序,如果 storeFile 中有数据被删除,或者无效了,并不会在这个阶段进行处理,采用边读取 storeFile 文件边向 HFile 文件追加的方式,将数据合并起来(第一次执行的时候,这个 HFile 就是后面所提到的大的 HFile)
注意:
此过程中因为不做任何处理,所以这个过程的效率还是比较高的。
② major:
这个部分就是将这个较大的 HFile 和大的 HFile 进行合并,形成一个更大的 HFile 的过程,在合并的过程中,如果有的数据被删除了,或者被无效了,都要在这个阶段进行处理,合并成为一个最终的结果文件。
默认是七天执行一次此操作,但是在生产的过程中,一般把此操作的自动执行关闭,都是采用手动执行(选择服务器不繁忙的时候,例如凌晨)
注意:
此阶段对资源的消耗比较高,所以在执行的过程中,整个表不允许进行任何的读写操作。
3.2.流程图