版权声明: https://blog.csdn.net/pbrlovejava/article/details/82495146
目录
所谓子句,就是在一条查询sql中起到特定功能的关键字段,子句在复杂查询中占据了很重要的位置,比如说分组查询,聚合函数使用后的条件筛选等,都需要用到特定的子句,本篇将介绍常用的MySql子句以及子句分析。
一、常用的MySql子句
常用的MySql子句有四条,分别是WHERE、GROUP BY、ORDER BY 、HAVING
扫描二维码关注公众号,回复:
3085547 查看本文章

二、建表语句
-- /创建雇员表/
CREATE TABLE emp(
empno INT PRIMARY KEY,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
COMM DECIMAL(7,2),
deptno INT,
CONSTRAINT fk_emp FOREIGN KEY(mgr) REFERENCES emp(empno)
);
-- /插入emp表数据/
INSERT INTO emp VALUES (1009, '曾阿牛', '董事长', NULL, '2001-11-17', 50000, NULL, 10);
INSERT INTO emp VALUES (1004, '刘备', '经理', 1009, '2001-04-02', 29750, NULL, 20);
INSERT INTO emp VALUES (1006, '关羽', '经理', 1009, '2001-05-01', 28500, NULL, 30);
INSERT INTO emp VALUES (1007, '张飞', '经理', 1009, '2001-09-01', 24500, NULL, 10);
INSERT INTO emp VALUES (1008, '诸葛亮', '分析师', 1004, '2007-04-19', 30000, NULL, 20);
INSERT INTO emp VALUES (1013, '庞统', '分析师', 1004, '2001-12-03', 30000, NULL, 20);
INSERT INTO emp VALUES (1002, '黛绮丝', '销售员', 1006, '2001-02-20', 16000, 3000, 30);
INSERT INTO emp VALUES (1003, '殷天正', '销售员', 1006, '2001-02-22', 12500, 5000, 30);
INSERT INTO emp VALUES (1005, '谢逊', '销售员', 1006, '2001-09-28', 12500, 14000, 30);
INSERT INTO emp VALUES (1010, '韦一笑', '销售员', 1006, '2001-09-08', 15000, 0, 30);
INSERT INTO emp VALUES (1012, '程普', '文员', 1006, '2001-12-03', 9500, NULL, 30);
INSERT INTO emp VALUES (1014, '黄盖', '文员', 1007, '2002-01-23', 13000, NULL, 10);
INSERT INTO emp VALUES (1011, '周泰', '文员', 1008, '2007-05-23', 11000, NULL, 20);
INSERT INTO emp VALUES (1001, '甘宁', '文员', 1013, '2000-12-17', 8000, NULL, 20);
三、子句使用
1、WHERE子句
使用示例
这是一个很常见的子句了,几乎每天sql都会用来做条件筛选,这里就不再演示。
注意
在一条Sql执行时,数据库系统会首先找到WHERE子句,并判断条件是否成立,并将查询到的结果存储到内存中,成立就返回1,不成立就返回0,当返回1时,才会继续执行WHERE之前的语句,这和后面要说到的HAVING语句有很大不同
2、GROUP BY语句
使用示例
这是用于分组的语句,常常和聚合函数使用(MySql的函数)它在执行完一段查询后将数据分组,必须放在发挥作用的查询语句之后
-- 查询出每个部门中员工编号大于1005的员工数和部门编号
SELECT e.`deptno` 部门号,COUNT(*) 部门人数
FROM emp e
WHERE e.`empno` > 1005
GROUP BY e.`deptno`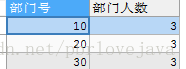
如果将GROUP BY放在WHERE语句之前,即在没查出来数据之前就进行分组,则会报错
SELECT e.`deptno` 部门号,COUNT(*) 部门人数
FROM emp e
GROUP BY e.`deptno`
WHERE e.`empno` > 1005 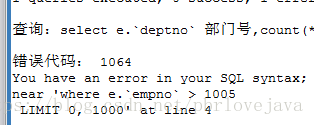
3、ORDER BY 子句
使用示例
该子句常常和聚集函数使用,在查询出结果之后,针对某个字段进行排序,默认为升序,在后面加上DESC后为降序
-- 查询出部门号和其员工数量,按部门号降序排列
SELECT e.`deptno` ,COUNT(*)
FROM emp e
GROUP BY e.`deptno`
ORDER BY e.`deptno`
DESC注意,ORDER BY 语句常常放在Sql的最后面,在没有分组完成前就通过部门号排序,会出现错误
SELECT e.`deptno` ,COUNT(*)
FROM emp e
ORDER BY e.`deptno`
GROUP BY e.`deptno`
DESC
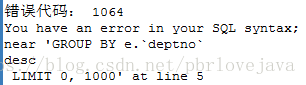
4、HAVING子句
使用示例
HAVING子句和WHERE子句十分相似,两者的作用都是用来判断和筛选结果,但是HAVING常常和聚集函数一起使用,但是HAVING子句是在整个主要查询执行完了之后才进行筛选的,而WHERE是在查询前进行筛选判断
-- 查询出员工的平均工资大于8000的部门通过平均工资升序
SELECT e.`deptno` ,AVG(e.`sal`) avgsal
FROM emp e
GROUP BY e.`deptno`
HAVING avgsal > 8000
ORDER BY avgsal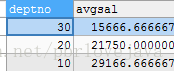
这条语句就是先查询出了部门号和部门平均工资后再筛选出平均工资大于8000的部门
而这条语句就是先筛选出员工编号大于1005的记录后用于分组
SELECT e.`deptno` 部门号,COUNT(*) 部门人数
FROM emp e
WHERE e.`empno` > 1005
GROUP BY e.`deptno`
ORDER BY e.`deptno`
DESC