写在前面:
刚才在写这篇文章之前,一直在思考,一个数据库为什么会有不同的存储引擎。
世界上没有一种东西是完美的,否则也不会出现那么多相近却又不同的产品了,
举个栗子,好比动态语言和静态语言,又如一句古话“鱼和熊掌不可兼得”。
所以MySQL为了满足不同业务的,不同场景,不同使用者,推出了不同的存储引擎,在现在这个“百花齐放”的年代,我只对MySQL最常用的存储引擎进行介绍:
结构
从存储文件查看数据表的物理结构:(演示在Mac OS X 下进行)
1. 先查看mysql的位置:
which mysql
2. 进入mysql的目录:
cd /usr/local/mysql/ 可以看到mysql目录下有以下文件

3. 查看当前mysql数据库下游那些数据库,那些表
mysql -uroot -p
show databases;
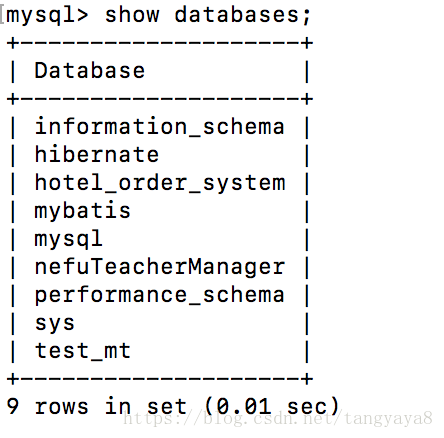
进入mybatis这个数据库:
use mybatis

查看当前表的存储引擎:
show create table User:
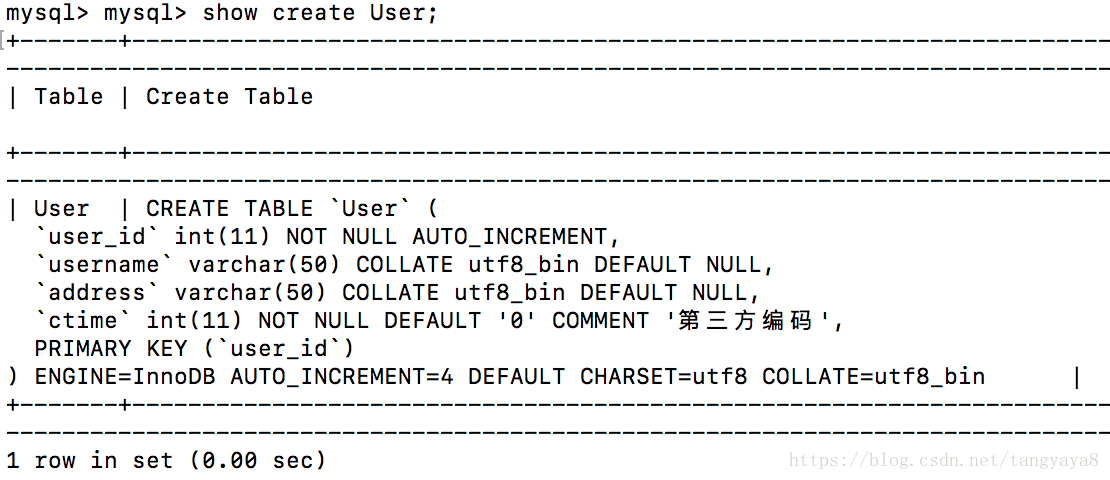
可以看出User表的存储引擎为InnoDB
show create table myisam_test
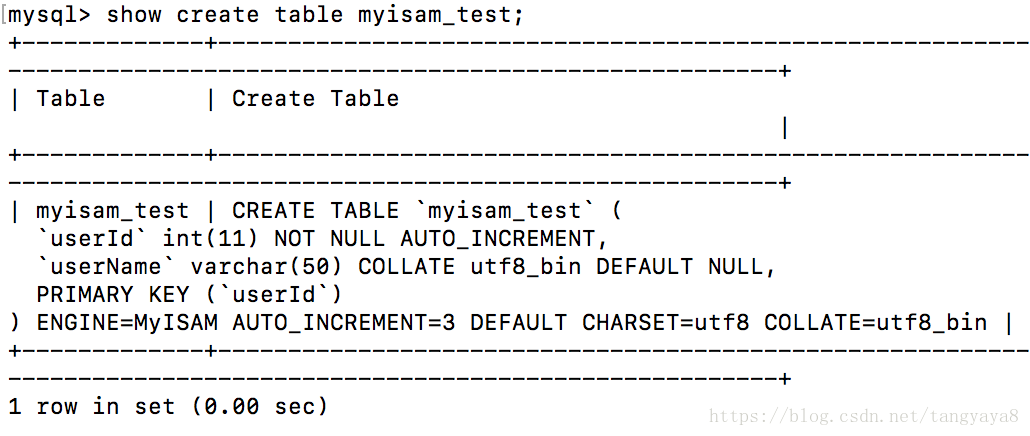
myisam_test的存储引擎为MyISAM
3.进入data目录:
cd data
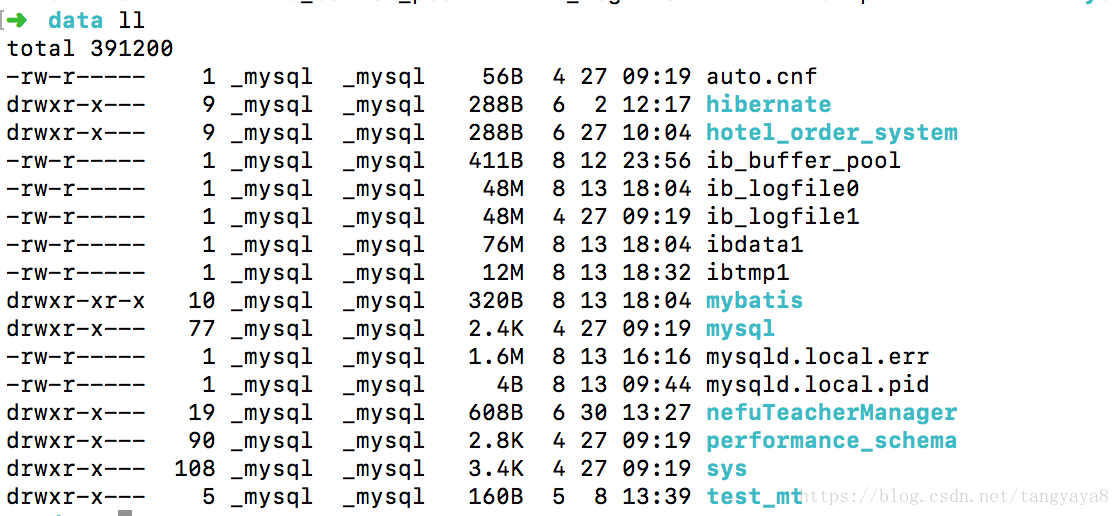
这是当前连接中的所有数据库
进入mybatis

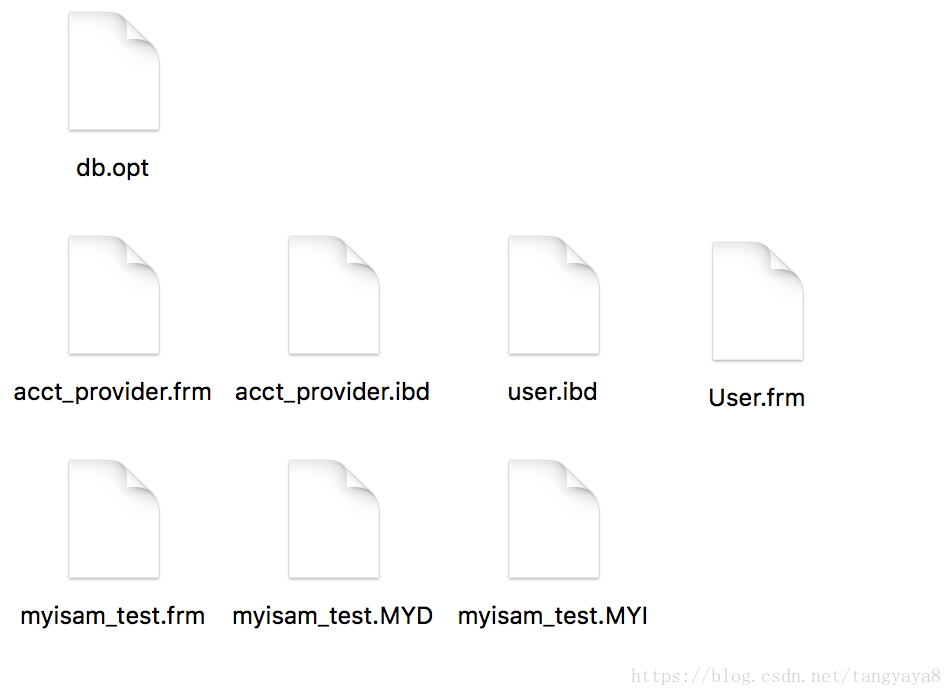
在这几个表中,acct_provider,user这两个表的引擎为innoDB,myisam_test为MyISAM引擎
db.opt文件:
default-character-set=utf8 //当前数据库的字符集
default-collation=utf8_bin //排序规则MySQL常用的数据库引擎
InnoDB
物理存储结构:
新建一个InnoDB引擎的表,会生成两个类型的文件:
1. *.frm:用来存储当前表结构
2. *.idb:用来存储表中的数据
逻辑存储结构:
将数据存储在硬盘上,当用户使用时要从硬盘上读出来放到内存或者从内存写入硬盘,MySQL的每次查找或者写入的时间可分为两个阶段:
1.将文件从硬盘读到内存中
2.从内存中加载的数据中查到所需要的数据
我们又知道内存的读取速度是硬盘的百分之一,所以MySQL读取数据的时间主要话费在第一阶段。而第一阶段和第二阶段又是相互联系的,所以我们来分析一下mysql的存储引擎内部数据结构:
当小数据量的时候,用二分查找,二叉树查找都没有什么问题,但是当数据量大的时候,这两种数据结构表现的就不是那么好了,
在常用的数据结构中,MySQL的InnoDB引擎采用了B+Tree的数据结构,首先来看一下B-tree(平衡多路查找树(B-Tree))的结构:
一棵m阶的B-Tree有如下特性:
1. 每个节点最多有m个孩子。
2. 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
3. 若根节点不是叶子节点,则至少有2个孩子
4. 所有叶子节点都在同一层,且不包含其它关键字信息
5. 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
6. 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
7. ki(i=1,…n)为关键字,且关键字升序排序。
8. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
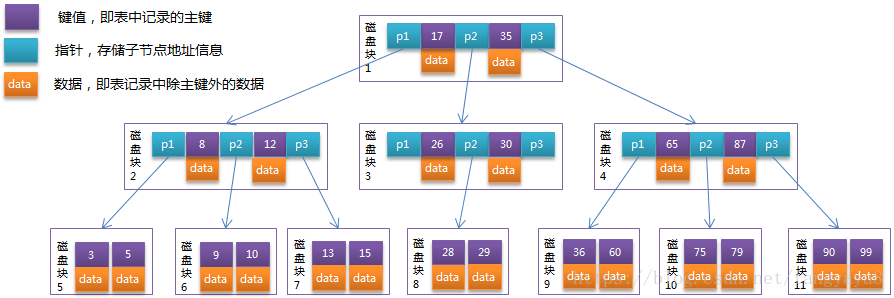
B+Tree
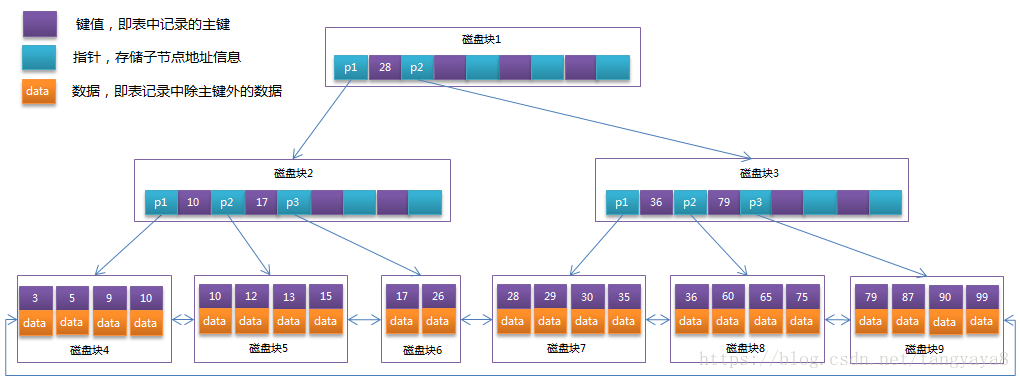
MyISAM
新建一个MyISAM引擎的表,会生成三个类型的文件:
1. *.frm:存储当前表结构
2. *.MYD:存储表中数据
3. *.MYI:存储索引