为什么要将服务或者数据部署多份?
1. 分布数据的理由
- 单机无法承受负载,请写请求太大,一台机处理不过来,为了可扩展性
- 避免单点故障,一台机挂了,整个服务就挂了。为了容错和高可用
- 降低服务的延迟,用户分布在各个地区,服务器部署在各个机房,将服务部署到离用户近的地方
2. 垂直扩容方案
- 一台机器内存不够了,那就加内存;CPU不够了,那就加CPU。
- 在一台机器上,内存加一倍、CPU加一倍,但是硬件配置所需要花的钱,却是多倍。
- 单机的硬件配置翻了一倍,该机器所能承受的负载却并不能翻一倍,因为有瓶颈问题。
- 这是一种 share-memory 结构
3. 水平扩容
- 加一台单独的机器,每台机器称为一个节点,组成所谓的集群
- 节点之间的协调由 软件层面(用户程序) 来实现
- 这是一种share-nothing 结构
4. 数据的分布方式
副本,Replication
将数据复制成多份,每份放在不同的节点上。复制产生了冗余,一台节点挂了,数据可从其他节点上拿到。
分片,Partition
将量级很大的数据分布多个小块,每个节点上存储一小块。因此,分片(Partition)是指:比如说,一台机器无法存下10T的数据,那我把这10T的数据,分成10个小份,每小份1T,放在10台机器上。这样,每台机器只存储1T数据。
副本
注意,是Replication,不是Partition。
为什么要将数据复制成多份呢?
- 我有一个关键词过滤服务部署在三个机房,如果每个机房都有一份词库,这样部署在本机房的过滤服务只需要读取自己机房的词库即可,从而降低延迟。
- 如果只有一份词库,这些词库所在的机器挂了,部署在三个机房的关键词过滤服务都不能用了。
- 分散读压力。如果只有一份词库,所有的关键词过滤服务程序都要来读取该词库,读请求吞吐量太大,响应不过来。
因此,每个机房有一份关键词(三个副本)。因此,我这里采用多副本的原因是:让数据更靠近用户,以降低延迟。
副本带来的难点是,当数据修改的时候,如何保持各个副本的一致性?
保证副本一致性的解决方案
Leader-based replication
以上面的关键词服务为例,三个副本中有一个副本是Leader,当需要添加新关键词时(网络上又出现了新的骂人的话^>^),向Leader发起写请求,将新词添加到词库中。
其他两个副本称为Follower。当Leader将新添加的词持久化到本地磁盘后,开始将新词同步到其他两个Follower。这里还有更深入一点的讨论,比如:同步操作是不是要保证以相同的顺序进行?比如Leader先将 词A 持久化,再将 词B 持久化,那两个副本是不是也应该以相同的顺序,先写入关键词A,再写入关键词B?
为了分担Leader压力,当客户端需要读取关键词时,可以从Follower读取,但是从Follower读取能不能读取到最新的数据呢?
这种主从式的副本方案,Mysql实现了、MongoDB也实现了,哈哈。我们就是这样干的。
同步复制还是异步复制?
这是一个权衡。在客户端写请求的响应性和数据的可靠性二者之间权衡
完全异步复制,客户端发写请求给Leader,Leader写入成功后,立即返回响应给客户端,然后Leader再将新写入的数据同步给其他Follower。这种方式的特点:
- 客户端响应快,因为只需要Leader写入成功就返回”写成功“响应给客户端
- 如果Leader写入数据后,还未来得及同步到Follower,就宕机了,就数据就丢失了。
- 客户端向Follower发起读请求时,有可能读取不到最新的数据。Leader给客户端返回的结果是写入成功了,但Leader还未同步到Follower,这里客户端就会看到:明明 已经写入成功的数据,却读取不到。
半同步复制。客户端发请求给Leader,Leader将数据同步给Follower,当其中一部分Follower同步成功后,立即给Leader回复成功。比如下图,Follower1同步成功给Leader响应,Leader再向客户端响应 写入成功。
- 如果Leader挂了,Follower1马上可以充当Leader,因为Follower1与Leader之间数据是一致的。如果Follower1挂了,Follower2可以充当Follower1的角色,并从Leader处同步最新的数据。总之,可以实现一定的容错。
- 在响应性和一致性、还有可靠性之间有一个较好的折衷。不需要等待所有的副本都写入成功,才向Client返回写入成功的响应,因此有着较好的响应性;在Client看来,Leader和Follower1 的数据是强一致的,如果Leader挂了,Follower1中保存着Client最近写入成功的数据,因此能容忍单机挂掉。
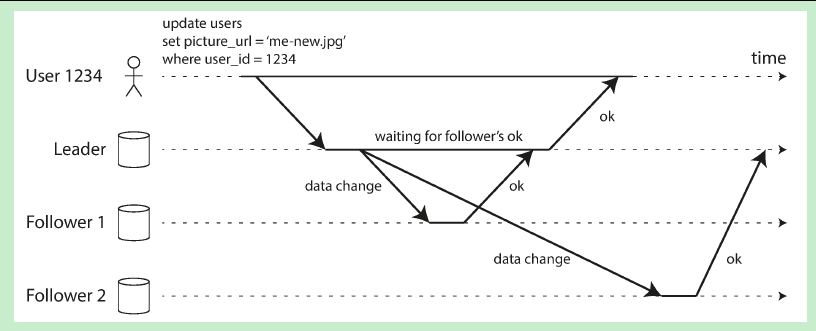
同步复制。客户端发写请求给Leader,Leader向Follower发同步请求,当所有的Follower都将 写请求 持久化成功后,给Leader响应,然后Leader再向客户端响应写请求成功。这种方式的特点是:
- 写操作吞吐量受到限制,因为一个写请求要等到所有的副本都持久化成功后,才算成功,只要有一台机器挂了,那客户端写请求就一直阻塞在那里,得不到响应。
- 客户端不管读哪个副本 ,每次都能读到最新写入成功的数据,因为对于写入成功的数据,肯定都已经成功同步到各个副本了。
总结一下这种主从副本的同步方案:当要更新数据时,都是向Leader发起请求。
如果采用完全异步复制,会存在数据一致性问题,Client读Follower不一定能读到最新的数据,要想读最新的数据,可以向Leader发起读请求,但这样可能造成Leader所在节点的负载过大,而Leader一旦挂掉,那些还未来得及同步到Follower的数据就都挂失了,导致Client看到的结果是:明明你给我返回的响应是数据写入成功了,但是我的数据却丢失了
如果采用完全同步复制,响应性就得不到很好的保证,毕竟网络分区、网络抖动不可避免。只要有一个Follower出现故障,无法响应,那Client就得不到 写入成功的响应了。当然好处是,在Client看来,数据的一致性有保证,随便读哪台Follower,都能读取到已经写入成功的数据
瞎扯了这么多理论,后面有时间再了解下一个具体的用到的产品ElasticSearch中的Shard和Replica同步的原理。囧。