一 序
上一篇介绍了《事务隔离》,本文继续整理MVCC实现原理。
二 锁
读锁:也叫共享锁、S锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
写锁:又称排他锁、X锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
表锁:操作对象是数据表。Mysql大多数锁策略都支持(常见mysql innodb),是系统开销最低但并发性最低的一个锁策略。事务t对整个表加读锁,则其他事务可读不可写,若加写锁,则其他事务增删改都不行。
行级锁:操作对象是数据表中的一行。是MVCC技术用的比较多的,但在MYISAM用不了,行级锁用mysql的储存引擎实现而不是mysql服务器。但行级锁对系统开销较大,处理高并发较好。
三 MVCC
3.1 原理
《高性能MySQL》第三版介绍这里1.4节:
可以认为MVCC是行锁的一个变种,大都实现了非阻塞的读操作,写操作也只锁定了必要的行。
MVCC的实现,是通过保存数据在某个时间点的快照来实现的,根据事务开始时间的不同,每个事务对于同一张表,同一时刻看到的数据可能是不同的。
上面是大概介绍,对于具体实现缺比较模糊,下面是原理介绍。
InnoDB的 MVCC ,是通过在每行记录的后面保存两个隐藏的列来实现的。这两个列, 一个保存了行的创建时间,一个保存了行的过期时间(或删除时间), 当然存储的并不是实际的时间值,而是系统版本号。
网上搜了下,说是3个字段的多一些。看下官网的介绍:
InnoDB is a multi-versioned storage engine: it keeps information about old versions of changed rows, to support transactional features such as concurrency and rollback. This information is stored in the tablespace in a data structure called a rollback segment(after an analogous data structure in Oracle). InnoDB uses the information in the rollback segment to perform the undo operations needed in a transaction rollback. It also uses the information to build earlier versions of a row for a consistent read.
Internally, InnoDB adds three fields to each row stored in the database. A 6-byte DB_TRX_ID field indicates the transaction identifier for the last transaction that inserted or updated the row. Also, a deletion is treated internally as an update where a special bit in the row is set to mark it as deleted. Each row also contains a 7-byte DB_ROLL_PTR field called the roll pointer. The roll pointer points to an undo log record written to the rollback segment. If the row was updated, the undo log record contains the information necessary to rebuild the content of the row before it was updated. A 6-byte DB_ROW_ID field contains a row ID that increases monotonically as new rows are inserted. If InnoDB generates a clustered index automatically, the index contains row ID values. Otherwise, the DB_ROW_IDcolumn does not appear in any index.
第一段介绍innodb是支持mvcc的引擎。靠的就是undo日志的rollback segment。
下面介绍了是三个字段:
6字节的事务ID(DB_TRX_ID) 表示最后一个事务的更新和插入,(每处理一个事务,其值自动+1)
7字节的回滚指针(DB_ROLL_PTR)指向当前记录项的rollback segment的undo log记录,找之前版本的数据就是通过这个指针
6字节的DB_ROW_ID 标识插入的新的数据行的id
当然还有个删除位,DELETE BIT位用于标识该记录是否被删除,这里的不是真正的删除数据,而是标志出来的删除。真正意义的删除是在commit的时候。
具体源码在dict_table_add_system_columns。
MVCC 在mysql 中的实现依赖的是 undo log 与 read view。
3.2 undo
undo log是为回滚而用,具体内容就是copy事务前的数据库内容(行)到undo buffer,在适合的时间把undo buffer中的内容刷新到磁盘.
行的更新过程
1 初始数据行
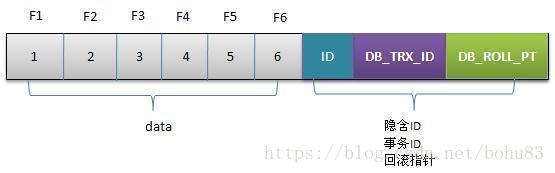
F1~F6是某行列的名字,1~6是其对应的数据。后面三个隐含字段分别对应该行的事务号和回滚指针,假如这条数据是刚INSERT的,可以认为ID为1,其他两个字段为空。
2. 事务1更改该行的各字段的值
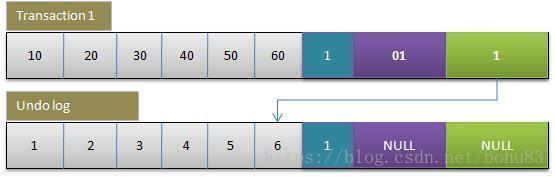
当事务1更改该行的值时,会进行如下操作:
用排他锁锁定该行
记录redo log
把该行修改前的值Copy到undo log,即上图中下面的行
修改当前行的值,填写事务编号,使回滚指针指向undo log中的修改前的行。
3 事务2修改改行的值
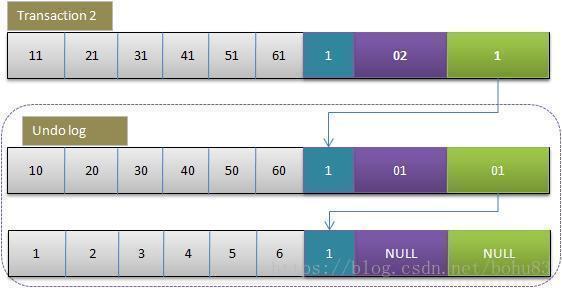
与事务1相同,此时undo log,中有有两行记录,并且通过回滚指针连在一起。
因此,如果undo log一直不删除,则会通过当前记录的回滚指针回溯到该行创建时的初始内容,所幸的时在Innodb中存在purge线程,它会查询那些比现在最老的活动事务还早的undo log,并删除它们,从而保证undo log文件不至于无限增长。
上述过程确切地说是描述了UPDATE的事务过程,其实undo log分insert和update undo log,因为insert时,原始的数据并不存在,所以回滚时把insert undo log丢弃即可,而update undo log则必须遵守上述过程。
当然也有人顺序有所调整,主要的没变,就是有行锁。
3.3 事务链表
MySQL中的事务在开始到提交这段过程中,都会被保存到一个叫trx_sys的事务链表中,这是一个基本的链表结构:
事务链表中保存的都是还未提交的事务,事务一旦被提交,则会被从事务链表中摘除。
RR隔离级别下,在每个事务开始的时候,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view)
RC隔离级别下,在每个语句开始的时候,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view)
这里在客户端执行命令:show engine innodb status
就能看到事务的list.
3.4 readview
read view是干什么的呢?上面可知MVCC实现了多个并发事务更新同一行记录会时产生多个记录版本,那问题来了,新开始的事务如果要查询这行记录,应该获取到哪个版本呢?就需要read view来解决行的可见性问题。
Read View是事务开启时当前所有事务的一个集合,这个类中存储了当前Read View中最大事务ID及最小事务ID。祥见read_view_struct这个结构体
/** The read should not see any transaction with trx id >= this
value. In other words, this is the "high water mark". */
trx_id_t m_low_limit_id;
/** The read should see all trx ids which are strictly
smaller (<) than this value. In other words, this is the
low water mark". */
trx_id_t m_up_limit_id;
/** trx id of creating transaction, set to TRX_ID_MAX for free
views. */
trx_id_t m_creator_trx_id;up_limit_id 后者表示事务id小于此值的行记录都可见.
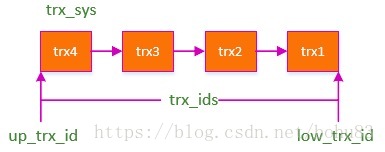
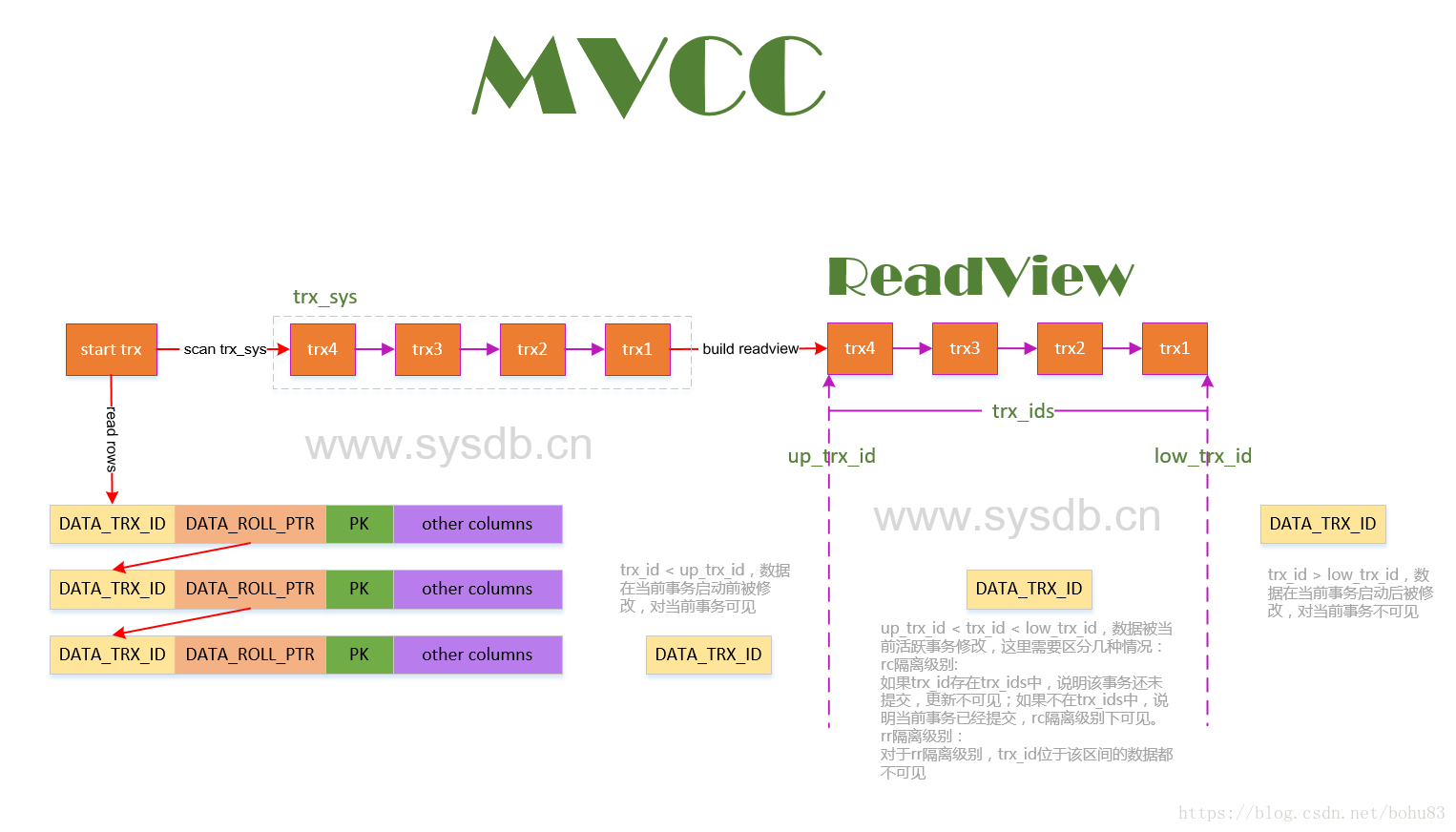
根据上图所示,所有数据行上DATA_TRX_ID小于up_trx_id的记录,说明修改该行的事务在当前事务开启之前都已经提交完成,所以对当前事务来说,都是可见的。而对于DATA_TRX_ID大于low_trx_id的记录,说明修改该行记录的事务在当前事务之后,所以对于当前事务来说是不可见的。至于位于(up_trx_id, low_trx_id)中间的事务是否可见,这个需要根据不同的事务隔离级别来确定。对于RC的事务隔离级别来说,对于事务执行过程中,已经提交的事务的数据,对当前事务是可见的,也就是说上述图中,当前事务运行过程中,trx1~4中任意一个事务提交,对当前事务来说都是可见的;而对于RR隔离级别来说,事务启动时,已经开始的事务链表中的事务的所有修改都是不可见的,所以在RR级别下,low_trx_id基本保持与up_trx_id相同的值即可。
没有自己读innodb源码,贴一下别人的。
row_search_mvcc->lock_clust_rec_cons_read_sees
bool
lock_clust_rec_cons_read_sees(
/*==========================*/
const rec_t* rec, /*!< in: user record which should be read or
passed over by a read cursor */
dict_index_t* index, /*!< in: clustered index */
const ulint* offsets,/*!< in: rec_get_offsets(rec, index) */
ReadView* view) /*!< in: consistent read view */
{
ut_ad(index->is_clustered());
ut_ad(page_rec_is_user_rec(rec));
ut_ad(rec_offs_validate(rec, index, offsets));
/* Temp-tables are not shared across connections and multiple
transactions from different connections cannot simultaneously
operate on same temp-table and so read of temp-table is
always consistent read. */
//只读事务或者临时表是不需要一致性读的判断
if (srv_read_only_mode || index->table->is_temporary()) {
ut_ad(view == 0 || index->table->is_temporary());
return(true);
}
/* NOTE that we call this function while holding the search
system latch. */
trx_id_t trx_id = row_get_rec_trx_id(rec, index, offsets); //获取记录上的TRX_ID这里需要解释下,我们一个查询可能满足的记录数有多个。那我们每读取一条记录的时候就要根据这条记录上的TRX_ID判断这条记录是否可见
return(view->changes_visible(trx_id, index->table->name)); //判断记录可见性
}下面是真正判断记录的看见性。
bool changes_visible(
trx_id_t id,
const table_name_t& name) const
MY_ATTRIBUTE((warn_unused_result))
{
ut_ad(id > 0);
//如果ID小于Read View中最小的, 则这条记录是可以看到。说明这条记录是在select这个事务开始之前就结束的
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
//如果比Read View中最大的还要大,则说明这条记录是在事务开始之后进行修改的,所以此条记录不应查看到
if (id >= m_low_limit_id) {
return(false);
} else if (m_ids.empty()) {
return(true);
}
const ids_t::value_type* p = m_ids.data();
return(!std::binary_search(p, p + m_ids.size(), id)); //判断是否在Read View中, 如果在说明在创建Read View时 此条记录还处于活跃状态则不应该查询到,否则说明创建Read View是此条记录已经是不活跃状态则可以查询到
}不同隔离级别ReadView实现方式
1. read-commited:
函数:ha_innobase::external_lock
if (trx->isolation_level <= TRX_ISO_READ_COMMITTED
&& trx->global_read_view) {
/ At low transaction isolation levels we let
each consistent read set its own snapshot /
read_view_close_for_mysql(trx);
即:在每次语句执行的过程中,都关闭read_view, 重新在row_search_for_mysql函数中创建当前的一份read_view。
这样就会产生不可重复读现象发生。
2. repeatable read:
在repeatable read的隔离级别下,创建事务trx结构的时候,就生成了当前的global read view。使用trx_assign_read_view函数创建,一直维持到事务结束。
在事务结束这段时间内 每一次查询都不会重新重建Read View , 从而实现了可重复读。
要是觉得不好理解,看看别人整理的图吧。
四 总结:
相信理解了上面的MVCC的原理,再来看书上1.4后面介绍MVCC的应用就会好多了。
SELECT
InnoDB检查每行,要确定它符合两个标准。
InnoDB必须知道行的版本号,这个行的版本号至少要和事物版本号一样的老。(也就是是说它的版本号可能少于或者和事物版本号相同)。这个既能确定事物开始之前行是存在的,也能确定事物创建或修改了这行。
行的删除操作的版本一定是未定义的或者大于事物的版本号。确定了事物开始之前,行没有被删除。
符合了以上两点。会返回查询结果。
INSERT
InnoDB记录了当前新增行的系统版本号。
DELETE
InnoDB记录的删除行的系统版本号作为行的删除ID。
UPDATE
InnoDB复制了一行。这个新行的版本号使用了系统版本号。它也把系统版本号作为了删除行的版本。
所有其他记录的结果保存是,从未获得锁的查询。这样它们查询的数据就会尽可能的快。要确定查询行要遵循这些标准。缺点是存储引擎要为每一行存储更多的数据,检查行的时候要做更多的处理以及其他内部的一些操作。
MVCC只能在可重复读和可提交读的隔离级别下生效。不可提交读不能使用它的原因是不能读取符合事物版本的行版本。它们总是读取最新的行版本。可序列化不能使用MVCC的原因是,它总是要锁定行。
看完这些与我之前印象中MVCC还是有较大区别的,以前一直以为不加锁实现了MVCC。就是每行都有版本号,保存时根据版本号决定是否成功,而innodb:
事务以排他锁的形式修改原始数据
把修改前的数据存放于undo log,通过回滚指针与主数据关联
修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
虽然不是真正意义的MVCC,MVCC对MySQL还有有作用的:
MVCC使得数据库读不会对数据加锁,select不会加锁,提高了数据库的并发处理能力;
借助MVCC,数据库可以实现RC,RR等隔离级别,用户可以查看当前数据的前一个或者前几个历史版本,保证了ACID中的I-隔离性。
还有很多不懂的,继续。。。。
参考:
https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html
https://blog.csdn.net/chen77716/article/details/6742128
https://blog.csdn.net/joy0921/article/details/80128857
http://www.ywnds.com/?p=10418