17 类 和 方法
16 类 和 函数
16.1 时间
class Time(object):
"""Represents the time of day."""
time = Time()
time.hour = 11
time.minute = 59
time.second = 3016.3 纯函数
纯函数 和 修改器——原型 和 补丁(prototype and patch)
这是一种 应对复杂问题的方法,从一个简单的原型开始,并逐渐解决更多的问题。
# 纯函数:仅仅返回一个值,并不修改作为实参传入的任何对象,
# 也没有如显示值或获得用户输入之类的副作用
def add_time(t1,t2):
sum = time()
sum.hour = t1.hour+t2.hour
sum.minute = t1.minute+t2.minute
sum.second = t1.second+t2.second
return sum【注】:这个函数,并没能处理 时分秒 的进位问题。
16.3 修改器(modifier)
有时候,使用函数 修改传入的参数对象 是很有用的。
这种情况下,修改 对调用者 是可见的。这样工作的函数 称为 修改器。
def increment(time,seconds):
time.seconds += seconds任何 可以使用修改器做到的功能 都可以使用 纯函数实现。
事实上,有的编程语言 只允许使用 纯函数。(错误更少,开发更快,效率更高)
推荐:总的来说,尽量编写纯函数,只在 有绝对说服力的原因时 使用修改器,这种方法可以称作 函数式编程风格
16.4 原型和计划
原型和计划 VS 有规划开发
- 原型和计划方法 在你对问题的理解并不深入时尤为有效。
(我编写一个可以进行基本计算的原型,再测试它,从中发现错误并打补丁) - 有规划开发方法——对应你对问题有了更高阶的理解
例如:时间对象实际上是 六十进制的3位数,
秒:个位数;分:60位数;时:360位数
于是,考虑整个问题的另一种解决方法是:时间对象与整数的转换(计算机本身知道如何做整数的运算(进位等))
def time_to_int(time):
minutes = time.hour*60+time.minute
seconds = minutes*60+time.second
return seconds
def int_to_time(seconds):
time = Time()
minutes,time.second = divmod(seconds,60)
time.hour,time.minute = sivmod(minutes,60)
return time
def add_time(t1,t2)
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)有意思的是,有时候 把一个问题弄得更难(或者更通用),反而会让它简单(因为会有更少的特殊情况和更少的出错机会)
16.5 调试
不变式:总是为真的条件
如:三个值都大于0,且 minute 和 hour 应当是整数,minute 和 second 的值应当在 0 到 60 之间
编写代码来检查 不变式 可以帮助我们探测错误并寻找错误根源:例如
def valid_time(time): # 不合法 时间对象
if tiem.hour<0 or time.minute<0 or time.second<0
return False
if time.minute>=60 or time.second>=60
return False
return True
# 方法一 使用 raise 检查参数(在函数开头)
def add_time(t1,t2)
if not valid_time(t1) and not valid_time(t2):
raise ValueError, 'invalid Time object'
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)
# 方法二 使用 assert 检查参数
def add_time(t1,t2)
assert valid_time(t1) and valid_time(t2)
seconds = time_to_int(t1)+time_to_int(t2)
return int_to_time(seeconds)assert 语句很有用,它会检查一个给定的不变式,并当检查失败时 抛出异常。
它 区分了 处理普通条件的代码 和 检查错误的代码
15 类 和 对象
15.1 用户定义类型
我们已经使用了很多 python 的 内置类型,现在我们要定义一个 新类型。
类型 类(class)
class Point(object) # 定义头,新的类:point,是内置类型object的一种
"""Represents a point in 2-D space.""" # 定义体,解释文档字符串
blank = Point() # 实例化实例化(Instantiation):新建一个对象的过程 称为实例化。
扫描二维码关注公众号,回复: 3074307 查看本文章
关于python中的object的理解
当我们自己去定个一个类及实例化它的时候,和上面的对象们又是什么关系呢?
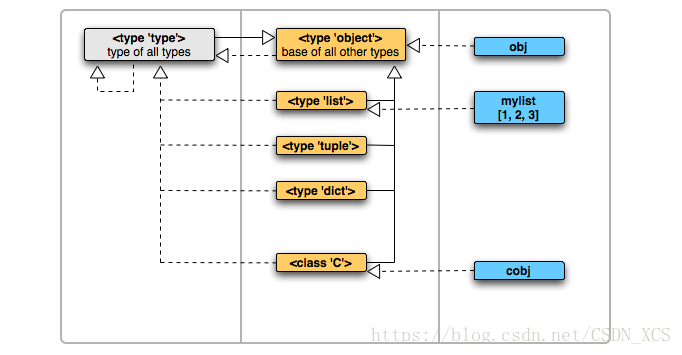
白板上的虚线表示源是目标的实例,实线表示源是目标的子类。
即,左边的是右边的类型,而上面的是下面的父亲。
虚线是跨列产生关系,而实线只能在一列内产生关系。除了type和object两者外。
15.2 属性(Attribute)
属性(Attribute):一个对象的 有命名的元素
# 变量 blank 引用向 一个Point对象,它包含两个属性。
# 每个属性 引用 一个浮点数
blank.x = 3.0
blank.y = 4.0
# 找到blank 引用的对象,并取得它的 x属性的值。
print(blank.x)15.5 对象是可变的
def grow_rectangle(rect,dwidth,dheight)
rect.width += dwidth
rect.height += dheight可以将 blank 这个实例,作为函数实参 按照通常的方式传递。
(在函数内修改值,blank 也会被修改)
函数 也可以返回实例。
15.6 复制(copy.copy)
使用别名的 常用替代方案是 复制对象。
(因为跟踪掌握 所有引用到一个给定对象 的变量,是困难的)
p2 = copy.copy(p1) copy模块 里有一个copy函数 可以复制任何对象。
【注】:此处,copy.copy为浅复制(shallow copy),只复制对象和该对象包含的引用,但步复制内嵌对象。
box3 = copy.deepcopy(box) copy模块 里有一个deepcopy函数 不但复制对象,且复制对象中的对象,称为深复制(deep copy)。
【注】:此时,box3和box是两个完全分开的对象。
15.7 调试
如果 访问了一个并不存在的属性,会得到错误:
AttributeError: xxx instance has no attribute ‘xx’
type(p) 询问对象的类型
hasattr(p,'x') 某对象是否有某个属性
14 文件(跳过)
13 案例(跳的)
12 元组(跳过)
RUNOOB网站:可以用作基本语法查询
12.1 元组是不可变的
元组和列表很像,都是一个值的序列,且值可以是任意类型,且按照整数下标索引
但是,元组是不可变的。
t1 = ('a','b','c','d') 新建元组(小括号+逗号)
l1 = ['a','b','c','d'] 新建列表(中括号+逗号)
str = 'abcd' 新建字符串
t2 = tuple('abcd') 另一种新建一个元组(本质是 将其他类型 转换为元组),
列表的大多数操作(下标操作符、切片操作符)均可作用于元组;
但是,元组的元素不能被修改。更类似字符串一些?
12.4 元组赋值
收集(gather):将所有的参数 收集到一个元组上;
分散(scatter):有一个序列,将他们作为各个参数分开。
12.5 列表 和 元组
zip 是一个内置函数,接收多个序列,将他们“拉”到一起,成为一个元组列表
11 字典
字典类似于列表。
在列表中,下标 必须是 整数;
在字典中,下标 (几乎)可以是任意类型。
可以把 字典看作 下标(称为键)集合 与 值集合之间的 映射。
每一个 键,都映射到一个值上。
键和值之间的关联 被称为 键值对(key-value pair),或者有时称为一项(item)
eng2sp = dict() 新建一个不包含任何项的字典;
eng2sp['one'] = 'uno' 添加新项,使用方括号操作符;
print eng2sp 打印字典;
【注】:打印时发现,字典中各项的顺序是不可预料的;
但好在顺序并不重要,只要 键 总是映射到 值 上。
len(eng2sp) 返回键的个数;
'one' in eng2sp 查看一个值 是不是 字典中的键;
vals = eng2sp.values() 查看一个值 是不是 字典的值;
'uno' in vals
in 操作符,对于列表,python 使用搜索算法。(列表越长,搜索时间越长)
对于字典,python用一个称为 散列表(hashtable) 的算法。(时间与字典规模无关)
11.1 使用 字典 作为计数器集合
假定给定一个字符串,你想要计算每个字母出现的次数。有几种可能的实现方法:
- 创建26个变量;
- 创建一个包含26个元素的列表;
- 建立一个字典。
实现(implementation) 是进行某种计算的一个具体方式。
def histogram(s) # 统计字符串 s 中字符出现的次数
d = dict()
for c in s:
if c not in d:
d[c] = 1 # 字符是键,次数是值
else:
d[c] =+ 1
return d直方图(histogram):统计出现的频率
h.get('a',0) 字典中的一个方法,接受一个 键和一个 默认值
11.2 循环 和 字典
for 循环遍历字典,键
def print_hist(h):
for c in h: # 使用键来遍历
print c,h[c]11.3 反向查找
查找(lookup):指 根据 键 找到 值;
反向查找:是指根据 值 找到 键。(速度远远慢于 查找)
并没有进行 反向查找的简单语法,需要使用遍历
另外,可能存在多个键映射在同一个值上的情况(或者挑选其中一个键?或者保存所有键在一个列表里?)
11.4 字典 和 列表
列表 可以在字典中 以值的形式出现。
字典1:字符中 的字符是键,出现的频率是值;
反转字典1:字符中 出现的频率作为 键,确实以该频率出现的字符 是 值。
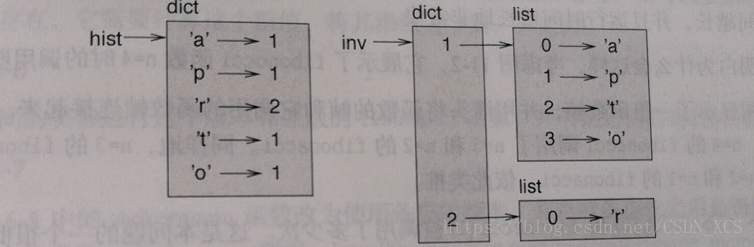
def inverse_dict(d): # 原字典是 d,反转后的字典是 inverse
inverse = dict()
for key in d
val = d[key]
if val not in inverse:
inverse[val] = key
else:
inverse[val].append(key) # inverse的值是 列表
return inverse键 必须是 可散列的(hashable),像列表这样的可变类型是 不可散列的。
散列 是一个函数,接受(任意类型)的值,并返回一个整数
11.5 备忘(Memo)
解决 Fibonacci 数列递归时,效率低的问题的一个方案是:
记录已经计算过的值,并将它们保存在一个字典中。
将之前计算的值保存起来,以便后面使用的方法 称为备忘(Memo)
known = {0:0,1:1} # known是一个已知的 Fibonacci数 的字典
def fibonacci(n): # 注意! known 被之间访问了
if n in known:
return known[n]
res = fibinacci(n-1)+fibonacci(n-2)
known[n] = res
return res
known 是 在函数之外创建的,属于被称为
__main__的特殊帧。
__main__之中的变量有时被称为 全局变量,它们可以被任意函数访问,一般情况下需要在函数中使用 global 声明!
为什么此处 known 没有用 global 声明,直接使用了呢?
如果,全局变量是可变的,你可以不用声明它,就直接进行【修改】——即,添加、删除、替换
但是,如果想要给全局变量重新赋值!则需要声明它:
known = {0:0,1:1}
def example():
global known # 注意区别
known = dict()11.8 调试
当你使用更大的数据集时,通过 打印和手动检查数据的方式 来调试已经 变得笨拙了。下面是一些调试大数据集的建议:
- 缩小输入:如果可能,减小数据的尺寸(逐步增大)
- 检查数据集的概要信息和类型,而不是整个数据集:如字典中条目的数目,列表中数的和
- 编写自检查逻辑,使代码自动检查:(如求平均,检查结果是否比最大数小,或者最小数大)
- 美化输出:格式化输出,更容易发现错误。pprint 函数(更人性化的可读格式打印)
10 列表(List)
10.1 列表是一个序列
列表 是 值的序列。
在字符串中,这些值是 字符;
在列表中,这些值可以是 任何类型,且可以是 不同类型的。
10.2 列表是可变的
可以把 列表看作是 下标和元素的关联。这种关联称为映射(mapping)。
每一个下标 映射到 元素中的一个。
10.3 遍历一个列表
当仅仅需要读取列表元素本身时,for 循环的遍历方式很好
for cheese in cheeses:
print cheese当 需要写入或更新元素时,则需要下标,常见的方式是使用函数range 和 len:
for i in range(len(numbers)): #range(n) 返回一个下标的列表:0到n-1
numbers[i] = numbers[i]*210.4 操作
+ 操作符 拼接列表
* 操作符 重复列表
t[1:3], t[:] 切片;
因为列表是可变的,在进行折叠、拉伸或破坏操作之前,复制一份很有必要
10.6 列表的方法
t.append('d') 在尾部添加新元素;
t.extend(t2) 将另一个列表的所有元素 附加到当前列表中
t.sort() 将列表元素从低到高排序
(列表的方法全都是无返回值的)
10.7 化简、映射和过滤
化简(reduce):将一个序列的元素值合起来 到一个单独的变量的操作
- 累加器(accumulator):
sum(t)
映射(map):它将一个函数 “映射”到一个序列的每一个元素上
- 例如:将列表的元素都大写
过滤(filter):它选择列表中的某些元素,并过滤掉其他的元素。
列表中的绝大多数操作都可以用 化简、映射和过滤 的组合来表达。
因为 这些操作非常常见,Python 提供了语言特性 直接支持它们。
10.8 删除元素
如果 你知道要删除元素的下标:
x = t.pop()删除该元素,并返回该元素的值;不提供下标,是指最后一个元素del t[1]直接删除del t[1:5]删除多个元素(从第一个下标开始,到第二个下标为止(不包含))
如果你知道 待删除元素的值:
t.remove('b')返回值是None
10.9 列表 和 字符串
字符的列表 != 字符串
t = list(s) 将 一个字符串 转换为 一个字符的列表;
t = s.split() 将字符串(一句话) 拆成一个个单词放在列表里;
delimiter = ' ' split 的逆操作,接受字符串列表,拼接成长字符串。
delimiter.join(t)
liist 是内置函数,应避免将其用作变量名
10.10 对象 和 值
两个列表是 相等的(equivalent);
但却不一定是 相同的(identical)。
对于同一个对象的两个引用,它们引用的对象是相同的,且一定有也是相等的;
对于不同对象的两个引用,它们有可能是相等的,但不能说它们是相同的。
10.11 别名
当一个对象有多个引用,且引用有不同的名称时,称这个对象有别名(aliase)
如果,处理的是可变对象,避免使用别名会更安全。(除非知道自己在使用)
【注意】:以下两句,是有很大区别滴!
a = [1,2,3]
b = a # b,a 两个变量引用 同一个对象
c = a[:] # c 和 a是相等的,但,不是相同的,引用不同的对象!
b[1]=3 # b,a 发生相同的改变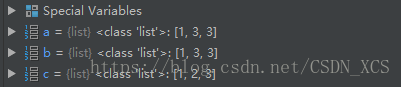
10.12 列表参数
当 将一个列表作为参数 传入函数中,函数会得到 这个列表的一个引用。
如果函数修改了列表参数,则 调用者 也能看到该修改。
区分,修改列表的操作 和 新建列表的操作 很重要!
t1 = [1,2]
t1.append(3) # 修改 t1,增加了一个元素
t2 = t1+[4] # t1 不发生变换,新建了列表 t2
del t1[0] # 删除 t1 的第一个元素
t3 = t1[1:] # t1 不变, 新建了列表 t310.13 调试
- 列表的大部分 方法,都是修改参数并返回 None 的;(因为列表是可变的)
相对应,字符串的方法,都是新建一个字符串,原字符串不变;(字符串不可变)
补充列表的方法的文档 - 选择一种风格,坚持不变!
列表的问题之一 就是,同样的事情有太多种可能的做法! - 通过复制,来避免别名。
8. 字符串
8.1 字符串是一个序列
字符串 是一个字符 序列(sequence)
可以使用 方括号操作符 来访问单独的字符,
方括号中的 表达式称为下标(index)
fruit = 'banana'
letter = fruit[1] # 则 letter 中存放 a对计算机科学家而言,下标 表示的是离 字符串开头的偏移量。 第一个字母的偏移量是0
8.2 len
len 是一个内置函数,返回 字符串中字符的个数。
那么,想要获取最后一个字符,可以这么写:
length = len(fruit)
last = fruit[length-1]或者,可以使用 负数下标
fruit[-1] #最后一个字母
fruit[-2] #倒数第二个字母8.3 使用 for 循环进行遍历(traversal)
方法1:使用 while 循环
index = 0
while index<len(fruit)
print(fruit[index])
index = index+1方法2:使用 for 循环
for char in fruit
print char每次迭代中,字符串中的下个字符 会被赋给 变量char。
循环会继续,直到没有剩余的字符为止。
8.4 字符串切片(slice)
操作符 [n:m] 返回字符串从 第n个字符 到 第m个字符 的部分。
包含 第n个字符,但不包含 第m个字符
8.5 字符串是不可变的
字符串是不可变的(immutable),也就是说,不能修改一个已经存在的字符串。
greeting = 'Hello, World!'
greeting[0] = 'J' # 会出错!只能新建字符串 使用切片拼接起来
new_greeting = 'J'+greeting[1:]8.6 搜索 find
python 本身是 存在该方法的(函数?)
def find(word,letter)
index = 0
while index<len(word)
if word[index] == letter
return index
index = index+1
return -1从某种意义上,find 是 [ ] 操作符的反面。
[ ] 操作符,通过一个下标查找对应的字符;
find ,根据一个字符 查找其在字符串中的下标。
【注】:标准库中存在 find 方法,并且:

8.8 字符串方法
方法和函数很类似,——它接受形参并返回值;
但语法有所不同。
例如:接收一个字符串,并返回一个将其全部字母均大写的字符串
使用语法的不同 体现在:
函数版:upper(word)
方法版:word.upper() #句点表示法,指定了方法的名称,以及方法作用的字符串名称
点击链接 阅读字符串方法的官方文档
点击链接 查看python标准库文档
strip 和 replace特别有用
strip: remove all coverings from 移除覆盖物
移除两端的空格

replace 替换

8.10 字符串比较
所有大写字母 都在 小写字母之前。
处理这个问题的常用办法:先将字符串都转换成 标准的形式(如都大写或小写)
8.11 调试
当使用下标来遍历序列中的值时,要正确实现遍历的开端和结尾需要留心。
必要时,可以打印 索引值。
7. 迭代
7.4 break语句
一种常见的写 while 循环的方式:
while True:
line = input('>')
if line == 'done':
break
print line
print 'done!'这种方式有两个优点:
- 可以把判断循环条件的逻辑放在循环的任意地方(而不只是在顶端);
- 可以用肯定的语气来表示终结条件(“当这样发生时,停止循环”),而不是否定语气(“继续执行,直到那个条件发生”)
7.5 平方根
牛顿法 是计算平方根的方法之一。
基于一个简单的直觉:
在比较小的范围内,某点的切线可以代替曲线,
且求该切线的零点可以让我们向 真实的零点靠近。
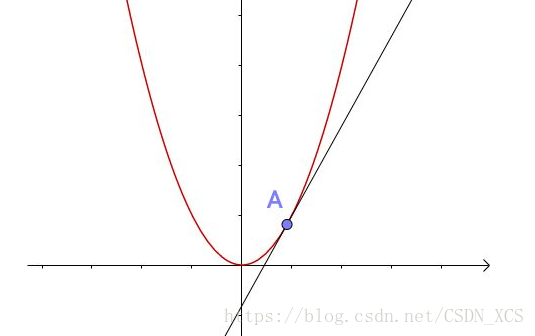
整理即得迭代公式:
特例:求平方根算法程序实现
while True:
print x0
x = (x0+a/x0)/2
if abs(x-x0)<epsilon:
break
x0 = x终止条件用精度控制,epsilon的值为 0.0000001,近似度是足够的。
7.6 算法
定义算法并不容易。
牛顿方法是 算法 的一个例子:它是解决一类问题的机械化过程。
算法的特点是,不需要任何聪明才智就能执行。
人类花费如此多的时间 在学校学习如何执行算法。。。有写尴尬;
另一方面,设计算法 的过程则充满趣味和挑战!也是程序设计的核心成分之一。
有时,我们自然而然、毫不费力做的事情,用算法表达却很困难。
我们都能够理解自然语言,但是迄今为止,还没有人能够解释我们怎么做到的,至少还没用算法解释。
7.7 调试
二分调试(debugging by biseection)
当开始编写 更大的程序时,
找到程序的中点,一个可以检验中间结果的地方,
如果检验结果错误,则错误出现在前半部分;如果正确,则在后半部分。
应当思考,哪些地方可能出现错误,
哪些地方容易加上检验,
然后选择一个其前后发生错误几率差不多的地方进行检验。
6. 有返回函数
6.2 增量开发
增量开发 的目标是,通过每次只增加一小部分代码,来避免长时间的调试过程。
关键点是:
- 以一个可以正确运行的程序开始,每次只做小的增量修改。如果在任意时刻发生错误,你都应当知道错误在哪里。
- 使用临时变量保存计算的中间结果,这样可以显示和检查它们;
- 一旦整个程序完成,你可能会想要删除某些脚手架代码(scaffolding)或者把多个语句整合到一个复杂表达式中。但只在不增加代码阅读难度时才这么做。
6.5 再谈递归
至今为止,我们只涉及到 python 的一个很小的子集,
但是,这个子集已经是一个 完备的编程语言了呦!
即,任何可以计算的问题,都可以用这个子集语言来完成;任何已有的程序,都可以用现在已经学会的语言特性重写出来。
6.6 坚持信念
跟踪程序执行的流程 是阅读程序的一个办法。但容易陷入迷宫境地。
另一个办法就是坚持信念,
即,当你遇到一个函数调用时,不去跟踪执行的流程,而假定函数是工作的!能返回正确结果的!
以 递归函数为例:
假设我能够 正确得到
的阶乘,如何计算
的阶乘?
6.8 检查类型
让 factorial 函数检查其实参的类型。
前面的检查条件就像守卫(guardian)一样,保护后面的代码。
6.9 调试
将 一个大程序 分解为小函数,自然而然引入了 调试的检查点。
如果 一个函数不能正常工作,可以考虑3重可能性:
- 函数获得的实参有问题,某个前置条件没有达到;(函数开始的地方加print)
- 函数本身有问题;(每个 return 前面加 print)
- 函数的返回值有问题;(检查调用它的代码(是否被调用,是否正确调用))
5. 条件 和 递归
5.3 逻辑操作符
and、or、not 表示 与、或、非
5.4 条件执行
一个语句头、一个缩进的语句体。
偶尔可能会遇到 需要一个语句体什么都不做(标记一个还没来得及写的代码的位置),这个时候可以用 pass 语句。
if x<0:
pass分支(branch)和条件链(chained conditional)
5.7 嵌套语句
逻辑操作符 常常能够用来简化 嵌套条件语句。
5.11 键盘输入
python3里,提供了一个内置函数 input,
当这个函数被调用时,程序会停止运行,并等待用户输入一些东西。
当用户按下回车键,程序会被恢复运行,
而且通过字符串形式返回用户输入的内容(意味着如果是整型,要进行类型转换)
date = input('what day is it today?')
what day is it today?>? 27
int(date)
275.12 调试
当发生错误时,python 的回溯包含了大量的信息,但最有用的信息是:
- 错误的类型;
- 发生错误的地方
【经验】:总的来说,错误信息会告诉我们发现错误的地址,
但真正发生错误的地方可能在更前面的代码中,有时候甚至在前一行。
3. 函数
3.1 函数调用
函数 是指用于进行某种计算的一系列语句的 有名称 的组合。
3.3 数学函数
python 有一个数学计算模块,提供了大多数常用的数学函数。
模块(Module) 是指包含一组相关的函数 的文件。
import math #想要使用一个模块,需要先将它导入
# 上面语句将会建立一个名为 math 的模块对象,
# 且 模块对象中包含了这个模块中 定义的函数和变量
math.pi #从math模块中获取变量pi的值,使用句点表达式(dot notation)3.5 添加新函数
def 是关键字,表示 接下来是一个函数的定义。
函数定义的第一行为 函数头,以冒号结束;
其他部分称为 函数体,整体缩进一级。
定义一个函数后,会创建一个同名的变量!该变量的值是一个函数对象,类型是’function’。
函数的定义,必须在函数的第一次调用之前执行。
3.6 执行流程
执行流程 ——即,程序中语句执行的顺序(保证定义先于执行)
- 总是从程序的第一行开始,从上到下,按顺序,执行每一条;
- 函数定义不改变执行流程(但函数体中的语句不立即执行,而是等到调用时执行)
启示:按照执行流程来阅读代码
3.10 栈图(stack diagram)
如果调用函数的过程中发生了错误,
python 会打印出 函数名,
调用这个函数的 函数名,
调用上面这个调用者 的函数名,
一直到 __main__
这个函数列表被称为 回溯(traceback),其中的函数顺序与栈图中一致。
他会告诉你 错误在那个程序文件,哪一行,以及哪些函数在运行。
3.13 使用from 导入模块
from math import pi #导入math 中的 pi对象
from math import * #导入math 中的 所有对象这样就不需要使用 句点表达式 math.pi访问对象 pi了,可以使用 pi
优点:代码更简洁;
缺点:可能发生名字冲突,在不同模块的同名成员、或和自定义的变量之间。
3.14 调试
建议:
尝试找一个能帮你处理缩进的编辑器;(统一使用空格符来缩进)
在运行之前保存代码,(如果开发环境不能自动保存);
确保眼前看到的程序,和执行的程序是一致的(在必要的地方添加 print(‘hello’) )
2. 变量、表达式和语句
2.3 变量名称 和 关键字
变量名 使用小写字母开头 是个好主意。
当变量名非法:SyntaxError: invalid syntax
python3 的31个关键字:
and as assert
break class continue
def del elif else except
finally for from global
if import in is lambda
not nonlocal or pass print
raise return try
while with yield
2.4 操作符 与 操作对象
在 python 中,
^ 表示 按位异或(XOR)
** 表示 乘方
在 python3 中,
// 表示 舍去式除法(floor division)舍去小数部分
2.7 操作顺序
优先级规则(Rules of precedence)
对数学操作符,python 遵守数学的传统规则:PEMDAS
- Parentheses:括号;
- Exponentiation:乘方;
- Multiplication:乘法; Division:除法;
- Addition:加法; Subtraction:减法;
2.8 字符串操作
+ 表示 拼接;
* 表示 重复; 'Spam'*3 结果为 'SpamSpamSpam'2.9 注释
# 表示 注释
注释 最重要的作用 是解释代码并不显而易见的特性(在做什么,为什么这样做)
2.10 调试
最常看到的语法错误信息:
SyntaxError: invalid syntax
SyntaxError: invalid token (二者都没有多少有用信息)
最常犯的运行时错误:没有定义就使用(use before def)
变量名 是 大小写敏感的!:LaTeX 与 latex 不同
1. 程序之道
计算机科学家 最重要的技能是问题解决。
问题解决 意味着发现问题,创造性地思考解决方案,以及清晰准确地表达解决方案的能力。
事实证明:学习编程的过程,是训练问题解决能力的绝佳机会。
1.1 python编程语言
有两种 程序 可以处理高级语言 并将其转换为 低级语言:
解释器 和 编译器。
图片
1.2 什么是程序
几乎所有语言 都会出现的几类基本指令:
- 输入
- 输出
- 数学操作
- 条件执行
- 重复
所有的程序,不论多么复杂,都是由类似上面的指令完成的。
所以,我们可以把 编程 看做将大而复杂的任务 分解为更小的子任务的过程,直到子任务简单得 可以由上面的这些指令组合完成。
1.3 什么是调试
程序是很容易出错的。由于某种古怪的原因,程序错误被称为 bug(虫)。
查捕 bug 的过程被称为 调试 debug。
1.4 程序错误
一个程序可能出现3种类型的错误:
- 语法错误;
- 运行错误(SyntaxError: invalid token);——(只有程序运行后才会出现)
- 语义错误。——(你写出的代码 和 你想写的代码不一致)
1.7 实验型调试
你将会掌握的一个最重要的技能就是 调试 。
虽然,调试比较困惑,但它的确是编程活动中,最动头脑、最有挑战、最有趣的部分。
在某种程度上,调试和刑侦工作很像!
你会面对一些线索,而且必须推导出事件发生的过程,以及导致现场结果的事件。
调试 也是一种实验科学。
一旦你猜出错误的可能原因,就可以修改程序,再运行一次:
如果你猜对了,那么程序的运行结果会符合你的预测,这样就离正确的程序更近了一步;
如果你猜错了,则需要重新思考。
夏洛克 福尔摩斯 说:
当你排除掉所有的可能性,那么剩下的,不管多么不可能,必定是真相。
——(柯南 道尔《四签名》)
对某些人来说,编程和调试 是同一件事情:
即,编程正是 不断修改直到程序达到设计目标。
这种想法的要旨是:你应该从一个能做 某些事 的程序开始,然后一点点修改,并调试修改,如此迭代,以确保总是有一个可以运行的程序。
1.8 自然语言 和 形式语言
自然语言:
指人们说的语言,是自然演化而来的。
形式语言:
是 人们设计出来的用于特殊用途的语言——(倾向于做出严格语法限制)
数学公式的符号表示系统:是一种表示 数字和符号的关系的形式语言。
化学式:表达分子的化学结构
编程语言:人们设计出来表达 计算过程的形式语言。
语法规则有两种:
- 关于记号:
- 关于语句的结构:
为什么使用 形式语言(或 自然语言的弊端;或二者的区别):
- 自然语言充满了 歧义性!(有时需要联系上下文理解)
- 自然语言有大量 冗余!(为了弥补歧义,减少误解)
- 自然语言充满了 比喻和成语!(形式语言 严格按照字面直接意思)
阅读程序的建议:
- 形式语言的密度 远大于 自然语言,因此阅读它需要花费更多的时间。
- 在头脑中解析程序的结构:自顶而下、从左向右并不一定最好。
- 细节!
1.10 调试
编程,特别是调试,有时候会引发强烈的情绪。
如果 你挣扎于一个困难问题时,可能会感到愤怒、沮丧以及窘迫。
对这些反应行为有所准备,可以帮助我们更好地对待电脑。
一种方法是,把它当成你的雇员:它有一定的长处——速度、精度;也有特定的弱点——无法顾全大局、没有同情心;
你的任务就是,做一个好经理——设法扬长避短!