最近在工作中用到拼音搜索,目前参考靠网上的例子做出一套,在这跟大家分享一下。
这套代码可以识别包快拼音缩写在内的拼音与汉字混合的字符串(例如:xiug手机h --> 修改手机号)
话不多说,直接开始:
1. 首先有一张中文词语对应拼音的表,然后建一张词语点击量的表(用于记录词语的常用度)
PinyinWord table
CREATE TABLE "public"."pinyinword" (
"id" text COLLATE "default" NOT NULL,
"word" text COLLATE "default" NOT NULL,
"whole" text COLLATE "default" NOT NULL,
"acronym" text COLLATE "default" NOT NULL,
"wordlength" int4 NOT NULL,
"wholelength" int4 NOT NULL,
"acronymlength" int4 NOT NULL
)
WordClick table
CREATE TABLE "public"."wordclick" (
"wordcontent" text COLLATE "default",
"id" text COLLATE "default" NOT NULL
)
表中数据自行初始化
2. 接下来介绍两个数据类型,在分析input时起到很重要的作用
/**
* 词元
*/
public class Lexeme {
private String content; //词元内容
private LexemeType lexemeType; //词元类型
}
public enum LexemeType {
CHINESE, //中文
WHOLE, //全拼
ACRONYM //拼音首字母缩写
}
/**
* 中文句子(处理用户输入的类)
*/
public class ChineseSentence {
private String content; // 用户输入内容
private List<Lexeme> sentenceUnits; // content中包含的词元
private SentenceType sentenceType; // 句子最低级类型(不能set,赋值请看initSentenceType())
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public List<Lexeme> getSentenceUnits() {
return sentenceUnits;
}
public SentenceType getSentenceType() {
return sentenceType;
}
public void setSentenceUnits(List<Lexeme> sentenceUnits) {
this.sentenceUnits = sentenceUnits;
initSentenceType();
}
private void initSentenceType() {
sentenceType = SentenceType.CHINESE_SENTENCE;
for (Lexeme lexeme : sentenceUnits) {
if (lexeme.getLexemeType() == LexemeType.ACRONYM) {
sentenceType = SentenceType.ACRONYM_SENTENCE;
break;
} else if (lexeme.getLexemeType() == LexemeType.WHOLE
&& sentenceType == SentenceType.CHINESE_SENTENCE) {
sentenceType = SentenceType.WHOLE_SENTENCE;
}
}
}
}
3. 接下来就是处理用户输入(xiug手机h),使用正则表达式将目标分解成词元(Lexeme)并 生成句子
//正则表达式(从网上copy下来做了一些修改,识别中文和疑似的拼音)
private static final String SUSPECTED_PINYIN_REGEX
= "[\\u4e00-\\u9fa5]|(sh|ch|zh|[^aoeiuv])?[iuv]?(ai|ei|ao|ou|er|ang?|eng?|ong|a|o|e|i|u|ng|n)?";
使用这个正则表达式可能会截取出 不存在的拼音组合,比如说jvao
这种直接成 j,v,a,o(找一个拼音组合的库,看看截出来的拼音属不属于库里即可)
经过截取并给每个词元附一个lexemeType,得到下边的结果
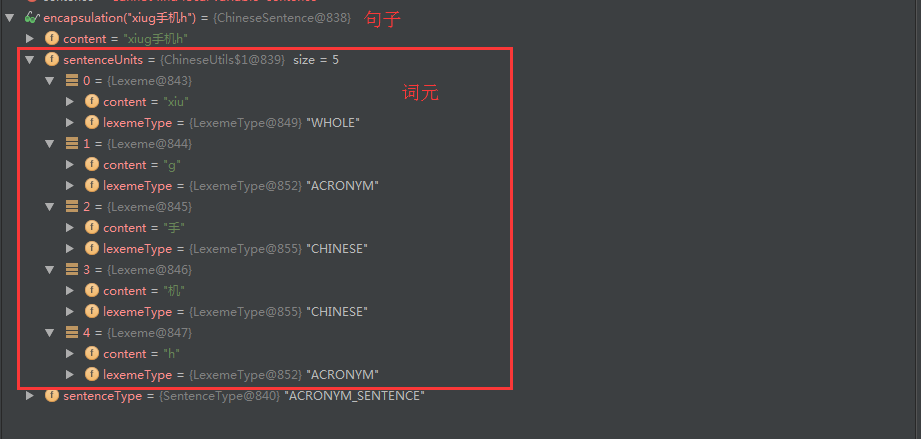
4. 接下来就是对句子中词元逐个进行分析
首先简要说明一下分析原理
先看一下查询条件
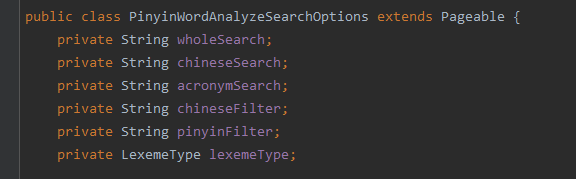
解释一下查询参数,首先是lexemeType 这个字段是指定搜索的词级,必须按照句子的最低词级进行搜索
例如: '修改' --> LexemeType.CHINESE
'xiu改' --> LexemeType.WHOLE
'修g' --> LexemeType.ACRONYM
Search结尾的三个参数是用来做搜索的,他们在SQL中用来做like操作, 这样可以击中索引
and pinyinword.acronym like #{acronymSearch} || '%'
由于用户输入的句子中可能含有中文或者拼音,这两种类型里需要进行过滤
比如说用户输入 ‘修g’ 我们用最低词级进行搜索 就是 like 'xg' % 这样可能搜到 '鞋柜' 所以我用了chineseFilter 和 pinyinFilter 来进行过滤(把 '%修%' append到chineseFilter中),这样查询条件就变成了
and pinyinword.acronym like #{acronymSearch} || '%'
and pinyinword.word like #{chineseFilter}
这样就不会搜到 '鞋柜' 了
来看一下mybatis下的SQL,这里join了wordclick表,取得了每个词语的点击量,用来排序
<select id="searchByClickCount" resultType="model.value.WordClickCount" parameterType="model.options.PinyinWordAnalyzeSearchOptions">
select
pw.word word, count(wc.id) clickCount
from
PinyinWord pw left join wordclick wc on wc.wordcontent = pw.word
where 1=1
<choose>
<when test="lexemeType.equals('CHINESE')">
<if test="chineseSearch!=null">
and pw.word like #{chineseSearch} || '%'
</if>
group by pw.word
order by clickCount desc
<if test="paging">
limit 5 offset 0
</if>
</when>
<when test="lexemeType.equals('WHOLE')">
<if test="wholeSearch!=null">
and pw.whole like #{wholeSearch} || '%'
</if>
<if test="chineseFilter!=null">
and pw.word like #{chineseFilter}
</if>
group by pw.word
order by clickCount desc
<if test="paging">
limit 5 offset 0
</if>
</when>
<otherwise>
<if test="acronymSearch!=null">
and pw.acronym like #{acronymSearch} || '%'
</if>
<if test="chineseFilter!=null">
and pw.word like #{chineseFilter}
</if>
<if test="pinyinFilter!=null">
and pw.whole like #{pinyinFilter}
</if>
group by pw.word
order by clickCount desc
<if test="paging">
limit 5 offset 0
</if>
</otherwise>
</choose>
</select>
然后是分析用户的输入,把查询条件生成出来
这是部分代码,足以明了 查询条件生成原则了
LexemeType currentLexemeType; //当前词元类型
LexemeType lastLexemeType = null; //之前词元最低级
List<Lexeme> lexemes = sentence.getSentenceUnits(); //累积词元最低级
for (int i = 0; i < lexemes.size(); i++) {
Lexeme lexeme = lexemes.get(i);
currentLexemeType = lexeme.getLexemeType();
String content = lexeme.getContent();
switch (currentLexemeType) {
case CHINESE: //若当前词元为中文
String pinyin = convertSmartAll(content); //转成拼音(pinyin4j)
chineseSearch.append(content); //append到chineseSearch字段
wholeSearch.append(pinyin); //append到wholeSearch字段
acronymSearch.append(pinyin.charAt(0)); //append到acronymSearch字段
chineseFilter.append(content).append("%"); //append到chineseFilter字段
break;
case WHOLE: //若为拼音 同理中文
wholeSearch.append(content);
acronymSearch.append(content.charAt(0));
pinyinFilter.append(content).append("%");
break;
case ACRONYM: //同理
acronymSearch.append(content);
break;
}
//将lastLexemeType 转换成当前词元和当前lastLexemeType中的第一级别的LexeType,因为搜索时需要词元最低级
lastLexemeType = LexemeType.changeDown(lastLexemeType, currentLexemeType);
//new searchOptions
PinyinWordAnalyzeSearchOptions options = new PinyinWordAnalyzeSearchOptions(
chineseSearch.toString(), wholeSearch.toString(), acronymSearch.toString(),
chineseFilter.toString(), pinyinFilter.toString(), lastLexemeType
);
// 结果出来啦。。。
List<WordClickCount> wordClickCounts = mapper.searchByClickCount(options);
测试一下:
@Test
public void analyzeAndSearchTest() throws Exception {
List<List<WordClickCount>> results = pinyinWordService.analyzeSearch("xiugaishoujihao"); //为了初始化 pinyin4j
long start1 = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
long start = System.currentTimeMillis();
List<List<WordClickCount>> results1 = pinyinWordService.analyzeSearch("xiugais机haoqyxgai修改");
long end = System.currentTimeMillis();
System.out.println(end - start + " ms");
}
long end1 = System.currentTimeMillis();
System.out.println(end1 - start1 + " ms");
}
测试结果
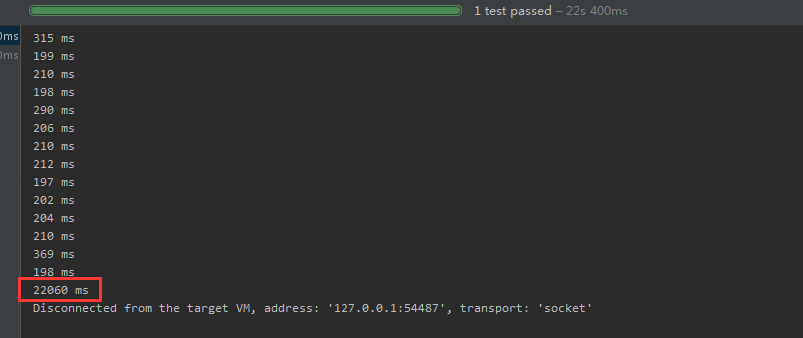 测试分解100条 11个词元的用户输入,话费22.1秒,平均每个221ms,效果还行
测试分解100条 11个词元的用户输入,话费22.1秒,平均每个221ms,效果还行
未来优化:
在sql中,使用了表关联和count操作,当数据量比较大的时候,可以考虑将pinyinword 加一个字段,每天跑定时把count update到pinyinword表中,这样可以对pinyinword进行单表查询了