在数据科学中,计算机科学和统计学汇合在一起。作为数据科学家,我们使用统计原理编写代码,以便我们可以有效地探索手头的问题。
这至少需要对数据结构,算法和时空复杂性有基本的了解,这样我们才能更有效地编程并理解我们使用的工具。对于更大的数据集,这变得尤为重要。我们编写代码的方式会影响分析数据的速度,并相应地得出结论。在这篇文章中,我将描述O符号作为描述时空复杂性的方法,并简要介绍一些与时间复杂性相关的算法。在后面的文章中,我将讨论与空间复杂性相关的算法。
O符号
在编程中,算法是为了实现特定目标而要遵循的过程或规则集。算法的特征在于其运行时间(运行时间),无论是空间还是时间。作为数据科学家,我们对最有效的算法感兴趣,以便我们可以优化我们的工作流程。
在计算机科学中,O表示法用于通过比较算法中的操作数来描述算法“快速” 增长的方式。稍后将对此进行更详细的解释,但现在,让我们理解所有正式的符号。
正式表示法
- Ω:最好的情况。算法的Ω描述了算法在最佳情况下运行的速度。
- O:最糟糕的情况。通常,我们最关心的是O时间,因为我们感兴趣的是给定算法运行的速度有多慢。我们如何从根本上使“最坏情况”变得不尽如人意?
- θ:如果Ω和O相同,这只能用于描述算法的运行时间。也就是说,算法的运行时间在最佳和最差情况下都是相同的。
因为我们最关心算法的O,所以本文的其余部分将只关注O.
我们如何使用O来描述算法?假设您希望在电话簿中搜索某人的姓名。

电话簿:谷歌之前的事情
找到这个人最直接的方法是什么?好吧,你可以浏览电话簿中的每个名字,直到找到你的目标。这被称为简单搜索。
如果电话簿非常小,只有10个名字,这是一个相当快的过程。但如果电话簿中有1000个名字怎么办?
充其量,您的目标名称位于列表的前面,您只需要检查第一项。在最坏的情况下,您的目标名称位于电话簿的最末端,您需要搜索所有1000个名称。随着“数据集”(或电话簿)的大小增加,运行简单搜索所需的最长时间也会线性增加。
在这种情况下,我们的算法是一个简单的搜索。O表示法允许我们描述最糟糕的情况。我们最糟糕的情况是我们必须搜索电话簿中的所有元素(n)。我们可以将运行时描述为:
O(n) 其中n:操作次数因为最大操作次数等于我们电话簿中的最大元素数(您可能需要搜索它们以查找目标的名称),我们说简单搜索的O是O(n)。简单的搜索永远不会比O(n)时间慢。
不同的O运行时间
不同的算法具有不同的运行时间。也就是说,算法以不同的速率增长。最常见的O运行时间,从最快到最慢,是:
- O(log n):又名日志时间
- O(n):又称线性时间
- O(n log n)
- O(Ñ ²)
- O(n!)
O 小抄对于快速图形化表示不同运行时间以及它们如何相互比较非常有用。
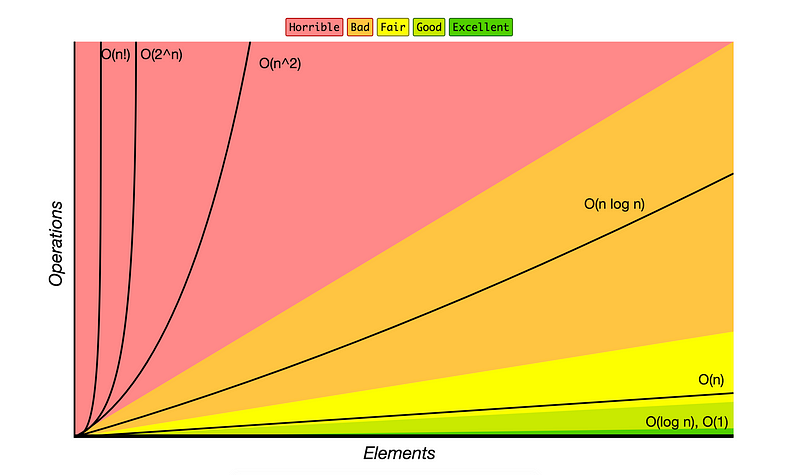
常见O运行时间的图形表示(http://bigocheatsheet.com/)
在这篇文章及其后续文章中,我将描述由这些不同的运行时间描述的常见算法。
笔记
在讨论一些常见算法之前,以下是一些重要的原则。
递归:递归是函数调用自身的时间。也许递归的典型例子是实现阶乘函数:
def factorial(n):
if n < 1: #base case
return 1
else: #recursive case
return n * factorial(n-1)该函数在函数本身内被调用,并将继续调用自身,直到达到基本情况(在这种情况下,当n为1时)。
分而治之(D&C):问题解决的递归方法,D&C(1)确定问题的最简单情况(AKA基本情况)和(2)减少问题,直到它现在是基本情况。
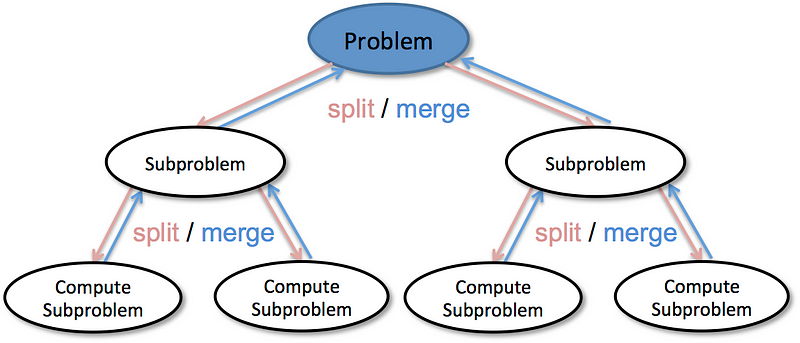
分治技术概述(来源:http://bigdata.ices.utexas.edu/project/divide-conquer-methods-for-big-data-analytics/)
也就是说,一个复杂的问题被分解为更简单的子问题。解决了这些子问题,然后将它们的解决方案结合起来解决原始的更大问题。
常用算法
搜索和排序算法可能是首先要理解的最重要的算法。
搜索
简单搜索
这在前面的电话簿示例中进行了描述,最糟糕的情况是要求您在找到感兴趣的名称之前搜索电话簿中的所有名称。通常,简单搜索具有O(n)时间。所需的最长时间与列表中的元素数量线性相关。
二进制搜索
让我们坚持使用电话簿示例。我们仍然有兴趣在电话簿中找到某人的名字,但这次我们将尝试提高效率。我们不是单调乏味地浏览电话簿中的每个名字,而是从电话簿的中间开始,然后从那里开始。
假设我们的目标名称以P开头。我们打开大致位于字母表中间的M s。我们知道M比字母表中的P早,所以我们可以消除从A到M的部分。现在我们可以看一下电话簿的后半部分(N到Z),将该部分分成中间(到Ts)),并与我们的目标进行比较。T在字母表中比P稍晚。然后我们知道要消除后半部分(T到Z)。我们专注于N到S.现在,把它分成两半,依此类推,直到找到我们感兴趣的名字。
通常,在二进制搜索中,您可以获取已排序(这很重要)的数据并找到中点。每次,您将目标与中间值进行比较。如果目标值与中间值相同,那么您的工作就完成了。否则,您知道根据比较消除列表的哪一半。您继续分割,直到找到目标或数据集不能再减半。
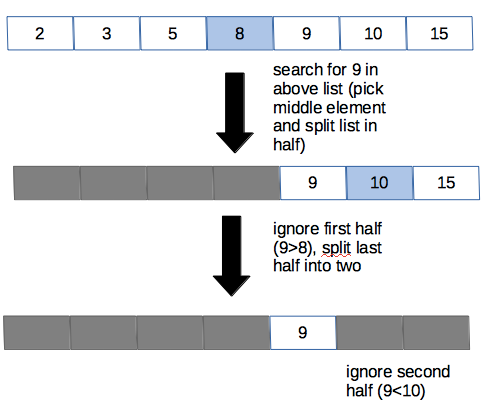
二进制搜索图与数字列表
由于二进制搜索涉及数据集减半,因此O时间为O(log n)。因此,它比简单搜索更快,特别是当您的数据集增长时(算法的增长不是线性的而是对数的,因此相对于O(n)的线性运行时间,它变得更慢)。
另外,二进制搜索可以递归写入,但不被视为D&C算法。尽管较大的输入确实被分解为子集,但如果它们不包含感兴趣的值,则忽略这些子集。不为这些子集生成解决方案,以便它们可以组合以解决更大的输入。
分类
选择排序
就像搜索算法的简单搜索一样,选择排序可能是对数据进行排序的最直接,“强力”方式。实际上,您将遍历列表中的每个元素,并按所需顺序将每个元素附加到新列表中。例如,如果您有兴趣对从最大到最小的数字列表进行排序,您会:
- 搜索列表以查找最大的数字
- 将该号码添加到新列表中
- 转到原始列表,再次搜索它以查找下一个最大的数字
- 将该数字添加到新列表中,依此类推......
对于选择排序,你必须遍历列表中的每个项目(这需要n次,就像进行简单搜索一样)并且你必须这样做n次(不只是一次,因为你必须继续回到原始列表,用于查找要添加到新列表的下一个项目)。因此,这需要O(ñ ²)时间。
Quicksort
快速排序与选择排序有何不同?如果我们使用数字列表,就像以前一样:
- 从列表中选择一个元素,称为数据透视表。选择枢轴对于确定快速排序算法的运行速度非常重要。现在,我们可以每次选择最后一个元素作为枢轴。(有关枢轴选择的其他信息,我建议使用Stanford Coursera算法课程。)
- 对列表进行分区,使得小于枢轴的所有数字都在其左侧,并且所有大于枢轴的数字都在其右侧。
- 对于列表的每个“一半”,您可以将其视为具有新数据透视表的新列表,并重新排列每一半,直到它被排序。
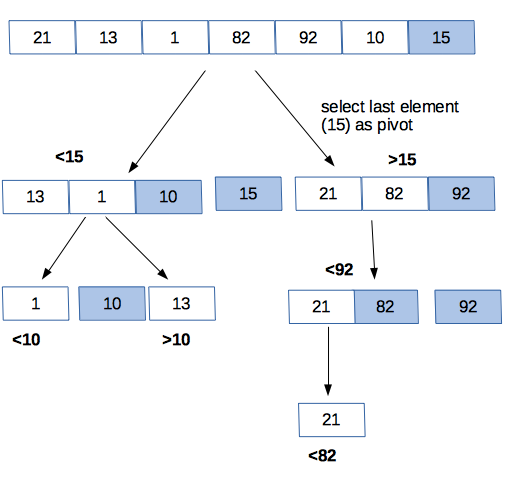
快速排序图与数字列表
Quicksort是D&C算法的一个示例,因为它将原始列表划分为更小和更小的列表。然后将这些较小的有序列表组合以产生更大的有序列表。
Quicksort是独一无二的,因为它的速度取决于枢轴选择。在最坏的情况,可能需要O(ñ ²)的时间,这是因为选择排序慢。但是,如果pivot在列表中始终是一个随机元素,则quicksort 平均在O(n log n)时间内运行。
Mergesort
假设我们仍在使用我们的数字列表。对于合并排序算法,列表将分解为其各个元素。然后从这些元素创建有序对(左边的数字越小)。然后将这些有序对分组为有序的四个组,并且这将继续,直到创建最终合并的排序列表。
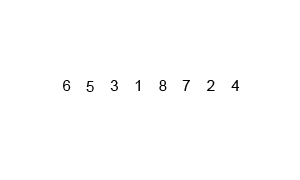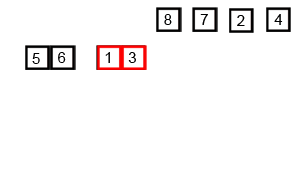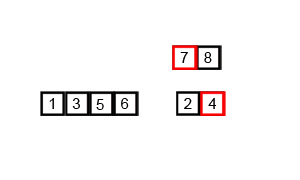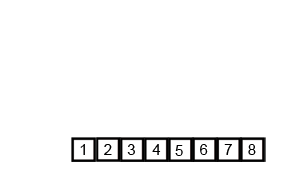
mergesort算法的动画概述(通过Swfung8 - 自己的工作,CC BY-SA 3.0,https://commons.wikimedia.org/w/index.php?curid = 14961648 )
与quicksort一样,mergesort是一种D&C算法,因为输入列表在被组合以生成较大的原始列表的有序版本之前被分解和排序。
Mergesort在O(n log n)时间运行,因为整个列表减半(O(log n))并且这是针对n个项目完成的。
对算法和数据结构的了解对数据科学家很有用,因为我们的解决方案不可避免地用代码编写。因此,了解数据结构以及如何根据算法进行思考非常重要。在以后的文章中,我将描述常见的数据结构,空间复杂性和常见的相关算法。
其他有用资源:
- Aditya Y. Bhargava的 Grokking算法
- 破解 Gayle Laakmann McDowell的编码专访
- 斯坦福大学Coursera 算法专业化
- O小抄
原文:https://towardsdatascience.com/a-data-scientists-guide-to-data-structures-algorithms-1176395015a0