Set序言
Java 中的 Set 和正好和数学上直观的集(set)的概念是相同的。Set 最大的特性就是不允许在其中存放的元素是重复的。
根据这个特点,我们就可以使用 Set 这个接口来实现前面提到的关于商品种类的存储需求。Set 可以被用来过滤在其他集合中存放的元素,从而得到一个没有包含重复新的集合。
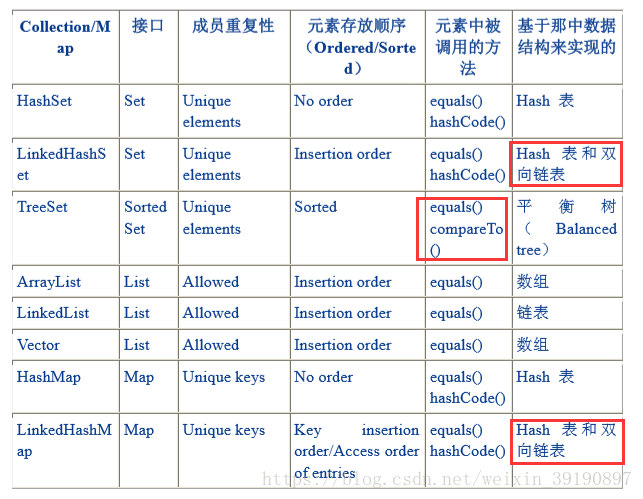
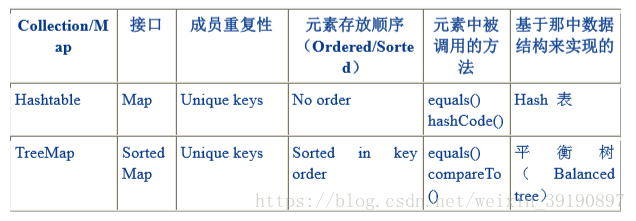
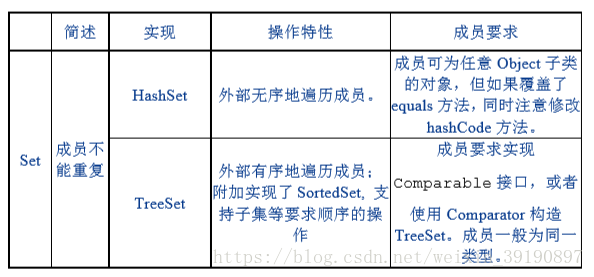
“集合框架” 支持 Set 接口两种普通的实现:HashSet 和 TreeSet以及 LinkedHashSet。
下表中是 Set 的常用实现类的描述:
在更多情况下,您会使用 HashSet 存储重复自由的集合。同时 HashSet中也是采用了Hash算法的方式进行存取对象元素的。
所以添加到 HashSet 的对象对应的类也需要采用恰当方式来实现 hashCode() 方法。
虽然大多数系统类覆盖了Object中缺省的hashCode() 实现,但创建自己的要添加到 HashSet 的类时,别忘了覆盖hashCode()。
应用实例
1、Set的使用
对于 Set的使用,我们先以一个简单的例子来说明:
package c08;
import java.util.*;
public class SetSortExample {
public static void main(String args[]) {
Set set1 = new HashSet();
Set set2 = new LinkedHashSet();
for(int i=0;i<5;i++){
//产生一个随机数,并将其放入 Set中
int s=(int) (Math.random()*100);
set1.add(new Integer( s));
set2.add(new Integer( s));
System.out.println("第 "+i+" 次随机数产生为:"+s);
}
System.out.println("未排序前 HashSet:"+set1);
System.out.println("未排序前 LinkedHashSet:"+set2);
//使用 TreeSet来对另外的 Set进行重构和排序
Set sortedSet = new TreeSet(set1);
System.out.println("排序后 TreeSet :"+sortedSet);
}
}该程序的一次执行结果为:
第 0 次随机数产生为:96
第 1 次随机数产生为:64
第 2 次随机数产生为:14
第 3 次随机数产生为:95
第 4 次随机数产生为:57
未排序前 HashSet:[64, 96, 95, 57, 14]
未排序前 LinkedHashSet:[96, 64, 14, 95, 57]
排序后 TreeSet :[14, 57, 64, 95, 96]从这个例子中,我们可以知道:HashSet的元素存放顺序和我们添加进去时候的顺序没有任何关系,而 LinkedHashSet 则保持元素的添加顺序。TreeSet则是对我们的 Set中的元素进行排序存放。
一般来说,当您要从集合中以有序的方式抽取元素时,TreeSet实现就会有用处。为了能顺利进行,添加到 TreeSet 的元素必须是可排序的。 而您同样需要对添加到 TreeSet中的类对象实现 Comparable 接口的支持。
一般说来,先把元素添加到HashSet,再把集合转换为TreeSet来进行有序遍历会更快。这点和下面HashMap的使用非常的类似。
2、Map的使用
来看另一个例子:(——关于Map(HashMap/ListHashMap/TreeMap)的使用)
package com.test;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Random;
import java.util.TreeMap;
public class MapSortDemo {
public static void main(String args[]) {
Map map1 = new HashMap();
Map map2 = new LinkedHashMap();
Random random =new Random();
for(int i=1;i<=5;i++){
int s=random.nextInt(10)+1; //产生一个随机数,并将其放入Map中
map1.put(s,"第 "+i+" 个放入的元素:"+s+"\n");
map2.put(s,"第 "+i+" 个放入的元素:"+s+"\n");
}
System.out.println("未排序前HashMap:"+map1);
System.out.println("未排序前LinkedHashMap:"+map2); //使用TreeMap来对另外的Map进行重构和排序
Map sortedMap = new TreeMap(map1);
System.out.println("排序后:"+sortedMap);
System.out.println("排序后:"+new TreeMap(map2));
}
}该程序的一次运行结果为:
未排序前HashMap:{1=第 5 个放入的元素:1
, 6=第 4 个放入的元素:6
, 7=第 3 个放入的元素:7
, 9=第 1 个放入的元素:9
}
未排序前LinkedHashMap:{9=第 1 个放入的元素:9
, 6=第 4 个放入的元素:6
, 7=第 3 个放入的元素:7
, 1=第 5 个放入的元素:1
}
排序后:{1=第 5 个放入的元素:1
, 6=第 4 个放入的元素:6
, 7=第 3 个放入的元素:7
, 9=第 1 个放入的元素:9
}
排序后:{1=第 5 个放入的元素:1
, 6=第 4 个放入的元素:6
, 7=第 3 个放入的元素:7
, 9=第 1 个放入的元素:9
}从运行结果,我们可以看出,HashMap的存入顺序和输出顺序无关。而LinkedHashMap 则保留了键值对的存入顺序。TreeMap 则是对 Map 中的元素进行排序。
在实际的使用中我们也经常这样做:
使用 HashMap 或者 LinkedHashMap 来存放元素,当所有的元素都存放完成后,如果使用则是需要一个经过排序的 Map 的话,我们再使用 TreeMap 来重构原来的 Map 对象。
这样做的好处是:
因为 HashMap 和 LinkedHashMap 存储数据的速度比直接使用 TreeMap要快,存取效率要高。当完成了所有的元素的存放后,我们再对整个的 Map 中的元素进行排序。这样可以提高整个程序的运行的效率,缩短执行时间。
这里需要注意的是,
TreeMap 中是根据键(Key)进行排序的。而如果我们要使用 TreeMap 来进行正常的排序的话,Key 中存放的对象必须实现 Comparable 接口。
3、Comparable 接口
我们简单介绍一下这个接口:
在 java.lang 包中,此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
它只有一个方法:int compareTo(T o);比较此对象与指定对象的顺序。用来比较当前实例和作为参数传入的元素:
(1)如果排序过程中当前实例出现在参数前(当前实例比参数大),就返回某个负值。
(2)如果当前实例出现在参数后(当前实例比参数小),则返回正值。
(3)否则,返回零。
如果这里不要求零返回值表示元素相等。零返回值可以只是表示两个对象在排序的时候排在同一个位置。
int的包装类:Integer 就实现了该接口。我们可以看一下这个类的源码:
public int compareTo(Integer anotherInteger) {
int thisVal = this.value;
int anotherVal = anotherInteger.value;
return (thisVal<anotherVal ? -1 : (thisVal==anotherVal ? 0 : 1));
}可以看到 compareTo 方法里面通过判断当前的 Integer对象的值是否大于传入的参数的值来得到返回值的。
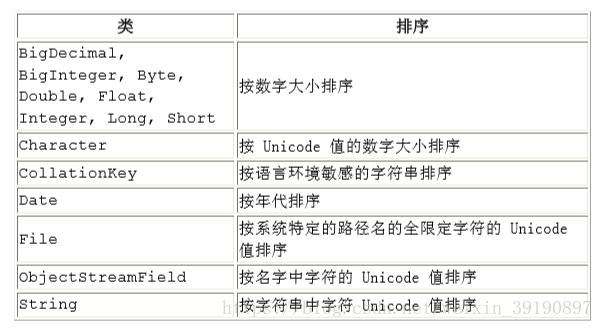
在 Java 2 SDK,版本 1.2 中有十四个类实现 Comparable接口。
下表展示了它们的自然排序。虽然一些类共享同一种自然排序,但只有相互可比的类才能排序。
HashSet实现原理
其实 Set的实现原理是基于 Map上面的。通过下面我们对 Set的进一步分析大家就能更加清楚的了解这点了。
Java 中 Set 的概念和数学中的集合(set)一致,都表示一个集内可以存放的元素是不能重复的。前面我们会发现,Set 中很多实现类和 Map 中的一些实现类的使用上非常的相似。而且前面再讲解 Map 的时候,我们也提到:Map 中的“键值对”,其中的“键”是不能重复的。这个和 Set 中的元素不能重复一致。我们以 HashSet 为例来分析一下,会发现其实 Set 利用的就是 Map 中“键”不能重复的特性来实现的。
先看看 HashSet 中的有哪些属性:
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();再结合构造函数来看看:
public HashSet() {
map = new HashMap<E,Object>();
}通过这些方法,我们可以发现,其实 HashSet 的实现,全部的操作都是基于 HashMap 来进行的。
我们看看是如何通过 HashMap 来保证我们的 HashSet 的元素不重复性的。从前面操作我们可以发现 HashSet 的巧妙实现:就是建立一个“键值对”,“键”就是我们要存入的对象,“值”则是一个常量。这样可以确保,我们所需要的存储的信息之是“键”。而“键”在 Map 中是不能重复的,这就保证了我们存入 Set 中的所有的元素都不重复。而判断是否添加元素成功,则是通过判断我们向 Map 中存入的“键值对”是否已经存在,如果存在的话,那么返回值肯定是常量:PRESENT,表示添加失败。如果不存在,返回值就为 null 表示添加成功。
了解了这些后,我们就不难理解,为什么 HashMap 中需要注意的地方,在 HashSet 中也同样的需要注意。其他的 Set 的实现类也是差不多的原理。
集合总结