1. max pooling和mean pooling(averge pooling)的区别
1.1 说法一1
pooling的作用主要有两个:
1.是保持不变性(旋转,平移,尺度)
2.是去除冗余信息,减少参数,防止过拟合。
在现在的DL中,数据量巨大。不同的样本基本已经涵盖了数据的平移,旋转,尺度不变性,所以现在的pooling更多的是被赋予上面所说的第2个作用。也就是在现在的DL标配中,多为conv->max pooling。
因为feature map本身就具有冗余,我们需要去掉这些冗余的信息,在做pooling时,如果使用average pooling,还是把这些冗余的信息考虑进来了,不如直接用max pooling,选取最显眼的那一个特征,当然这也有可能会有漏网之鱼。
而averge pooling考虑的更多的是全局(global)的信息,在Network in Network中,softmax之前的feature map好像是1000个,然后采用global average pooling来获得1000个神经元进行分类。这里的kernel为整个feature map那么大,就是考虑了所有的信息来做一个综合的判断。
因此,在模型的中间部分,多为max pooling,在分类前面,可以使用average pooling来综合考虑。
相关论文: LeCun的“Learning Mid-Level Features For Recognition”对前两种pooling方法有比较详细的分析对比,如果有需要可以看下这篇论文。
1.2 说法二2
特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。Stochastic-pooling则介于两者之间,通过对像素点按照数值大小赋予概率,再按照概率进行亚采样,在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
2.keras 特征图可视化
1.keras模型可视化,层可视化及kernel可视化
效果:
特征图:

卷积核:

2.利用Keras解释CNN的滤波器
VGG参数可视化,Keras自带例子:https://github.com/keras-team/keras/blob/master/examples/conv_filter_visualization.py

3.caffe逐层可视化图像特征
作者自己写的代码,将特征图保存之后,转换成mat,然后用matlab显示
结果如下:

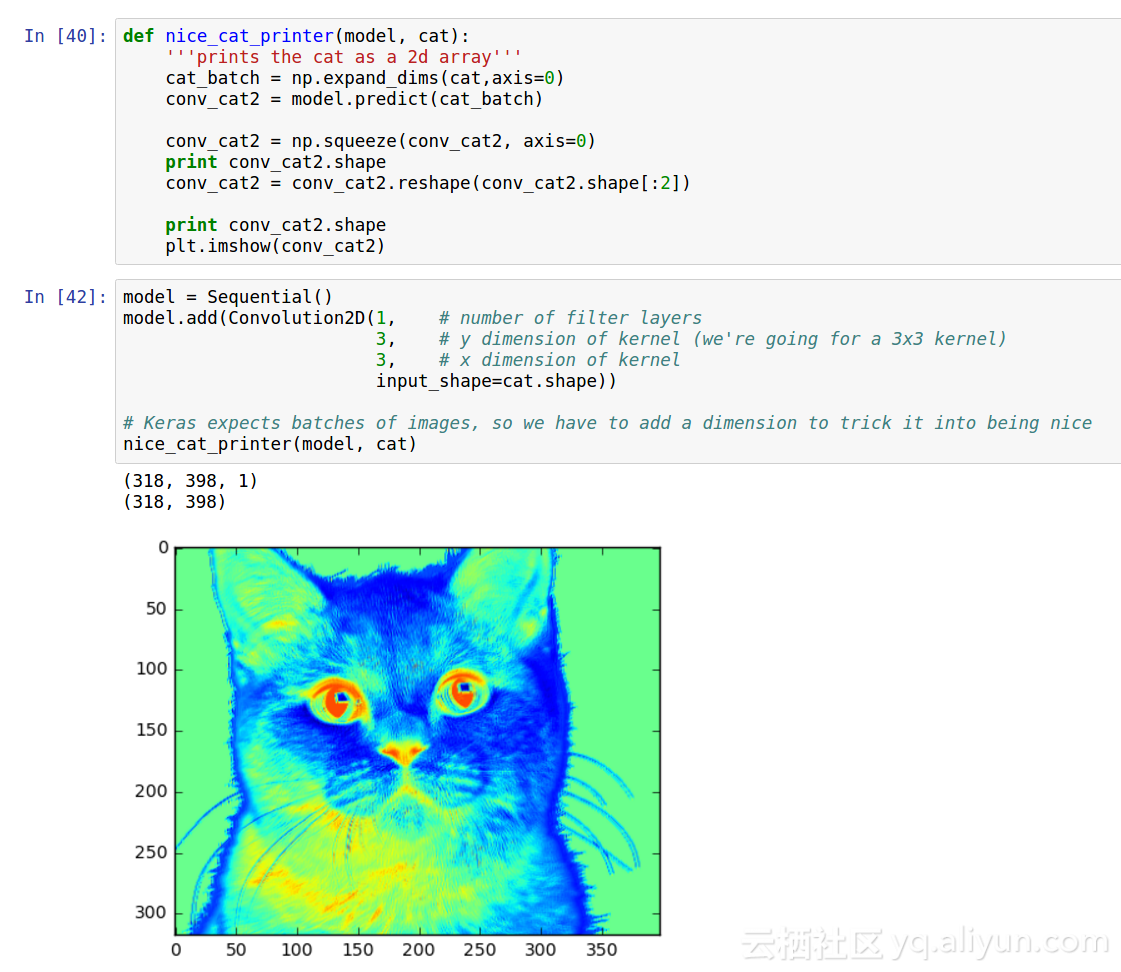
4.卷积神经网络实战(可视化部分)——使用keras识别猫咪
效果如下:
5.Keras中间层输出的两种方式,及特征图可视化
效果:

3.L2与方差的区别
https://www.jianshu.com/p/a47c46153326
https://www.colabug.com/2117220.html
4.交叉熵是以e为底还是以10为底
5.C和残差只有一个除以N还是都除以N
- 作者:Silence
链接:https://www.zhihu.com/question/23437871/answer/330874827
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 ↩ - 作者:张腾
链接:https://www.zhihu.com/question/23437871/answer/24696910
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 ↩