基础数据类型初识
1、int型
int:用于计算。
十进制转化成二进制的有效位数。
1 0000 0001
2 0000 0010
3 0000 0011
... ...
100 ?
计算十进制转化成二进制的有效位数。.bit_length()
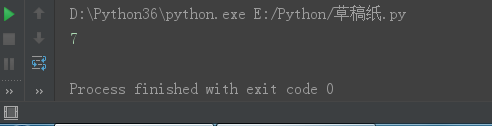
i = 100 print(i.bit_length())
2、字符串str
str: 'alex'、'1235443543'、'[1,2,3]'。可存放少量数据。
索引、切片、步长
索引编号:
python12期
012345678
p 的正向索引编号为0,y 的正向索引编号为1,t 的正向索引编号为2,h 的正向索引编号为3,o 的正向索引编号为4,n 的正向索引编号为5,1 的正向索引编号为6,2 的正向索引编号为7,期 的正向索引编号为8.
索引:
[索引位编号]
s = 'python12期' s1 = s[0] print(s1,type(s1))

s = 'python12期' s2 = s[4] print(s2)
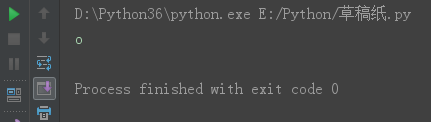
s = 'python12期' s3 = s[2] print(s3)

python12期
-9-8-7-6-5-4-3-2-1
期 的反向索引编号为-1,2 的反向索引编号为-2,1 的反向索引编号为-3,n 的反向索引编号为-4,o 的反向索引编号为-5,h 的反向索引编号为-6,t 的反向索引编号为-7,y 的反向索引编号为-8,p 的反向索引编号为-9。
s = 'python12期' s4 = s[-1] print(s4)

切片:
[索引起始位编号:索引结束位编号]
顾头不顾尾。
s = 'python12期' s5 = s[0:6] print(s5)

中括号中的切片起始位索引为为0时,可省略。
s = 'python12期' s6 = s[:6] print(s6)
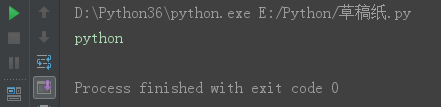
s = 'python12期' s7 = s[1:4] print(s7)
当中括号中索引位结束编号省略时,默认切片达到字符串结束。
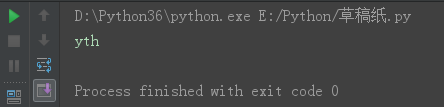
s = 'python12期' s8 = s[1:] print(s8)

当中括号中索引起始位编号与索引结束位编号省略时,默认对整个字符串切片,但是切片处的结果与原字符串本质上不是同一个内容(不同的存储位置)。
s = 'python12期' s9 = s[:] print(s9)
步长:
在中括号中,索引的结束位后边加上 :数字 表示截取的步长,即每几位截取一位。同时只能等距截取。
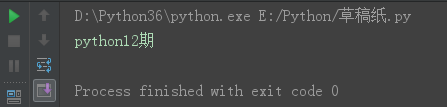
s = 'python12期' s10 = s[:5:2] print(s10)
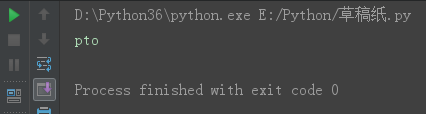
s = 'python12期' s11 = s[4::2] print(s11)

当步长为负数时,表示倒序截取。
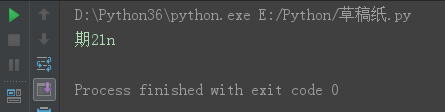
s = 'python12期' s12 = s[-1:-5:-1] print(s12)
s = 'python12期' s12 = s[-3:-1] print(s12)

字符串的常用操作方法:
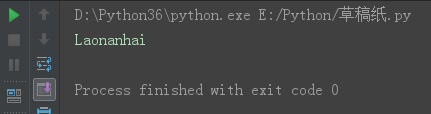
** capitalize 首字母大写,其余字母小写。
s = 'laoNANhai' s1 = s.capitalize() print(s1)
* center 居中
center(a,b) -a为设定字符串的总位数,当设定的总位数小于字符串的位数时,不变。 -b为在空位数上填充的字符串。
s = 'laoNANhai' s2 = s.center(27,"*") print(s2)

*** upper:全大写
s = 'laoNANhai' s3 = s.upper() print(s3)
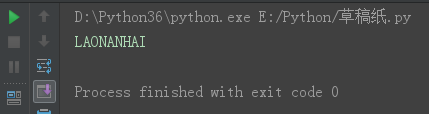
*** lower:全小写
s = 'laoNANhai' s4 = s.lower() print(s4)

code = 'QAdr'.upper()
your_code = input("请输入验证码,不分大小写:").upper()
if your_code == code:
print("验证成功")

*** startswith 判断以什么内容开头
返回bool值
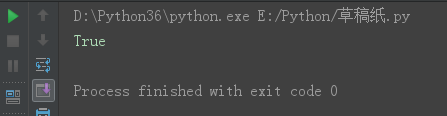
s = 'laoNANhai'
s5 = s.startswith('l')
print(s5)
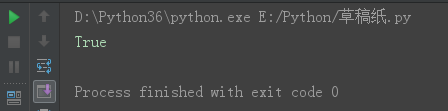
s = 'laoNANhai'
s6 = s.startswith('lao')
print(s6)
返回bool值,可以切片,切片用逗号隔开。
s = 'laoNANhai'
s7 = s.startswith('N',3,6)
print(s7)

* swapcase 大小写翻转
s = 'laoNANhai' s8 = s.swapcase() print(s8)

* title 非字母隔开的每个单词首字母大写。
s = 'gdsj wusir6taibai*ritian' s9 = s.title() print(s9)

*** 通过元素找索引
index:通过元素找索引,可切片,找不到报错。
s = 'gdsj wusir6taibai*ritian'
s10 = s.index('a')
print(s10)

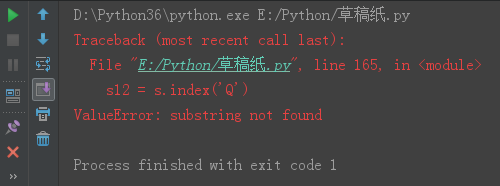
s = 'gdsj wusir6taibai*ritian'
s12 = s.index('Q')
print(s12)
find:通过元素找索引,可切片,找不到返回-1。
s = 'gdsj wusir6taibai*ritian'
s13 = s.find('a')
print(s13)
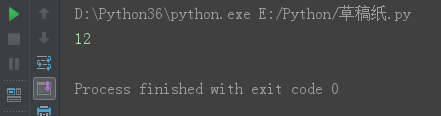
s = 'gdsj wusir6taibai*ritian'
s14 = s.find('A',2)
print(s14)
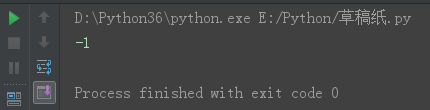
s = 'gdsj wusir6taibai*ritian'
s15 = s.find('Q')
print(s15)

\t :缩进符,缩进一个Tab键的距离。
s = '\talex' print(s)

\n :换行符。
ss = 'alex\n' print(ss)
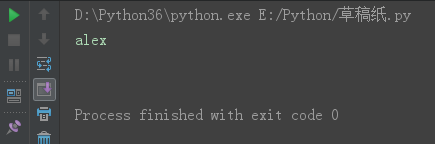
s = '\talex\n' print(s)
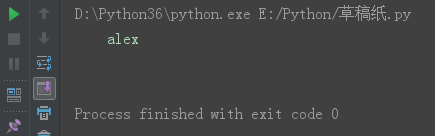
*** strip() 去除前后端的空格、换行符、制表符。
s = '\talex\n' s16 = s.strip() print(s16)
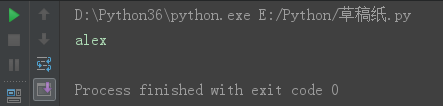
username = input("请输入账户名:").strip()
if username == "婉蓉":
print("登陆成功")

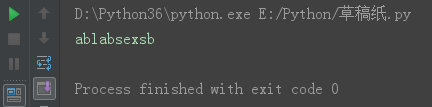
strip('a') 去除两端的指定字符,某一端当遇到第一个非a字符时,该端停止操作,另一端也遇到非a时完成操作。
s = ' ablabsexsba'
s17 = s.strip('a')
print(s17)

strip('abc') 当括号内的字符不只一个时,将括号内的内容拆分成单个的最小单元,然后从两端不分顺序的去除,当遇到非括号内的组成单元时,操作结束。
s = ' ablabsexsba'
s18 = s.strip('abc')
print(s18)

lstrip('a') 去除左端的a字符。
s = 'ablabsexsba'
s19 = s.lstrip('a')
print(s19)

rstrip('a') 去除右端的a字符。
s = 'ablabsexsba'
s20 = s.rstrip('a')
print(s20)
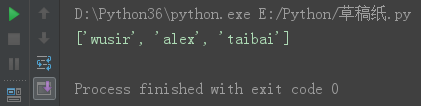
*** split() str ---> list
默认以空格隔开。
s = 'wusir alex taibai' s21 = s.split() print(s21)

s = 'wusir,alex,taibai'
s22 = s.split(',')
print(s22)
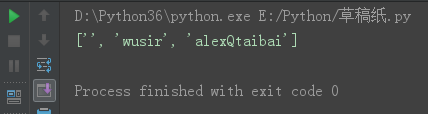
split('a',b) b为数字,也可以设定以a隔开,然后设定隔开前b个a,后边如果再有a,不考虑。
s = 'QwusirQalexQtaibai'
s23 = s.split('Q', 2)
print(s23)
*** join: 加入
s = 'alex' s24 = '+'.join(s) print(s24)

在某些情况下,list ---> str 。
s = ['wusir', 'alex', 'taibai'] s25 = ' '.join(s) print(s25)

replace('a','b') a为被替换的内容,b为替换后的内容。
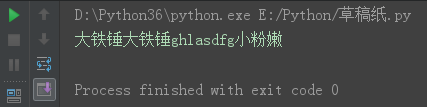
s = '小粉嫩小粉嫩ghlasdfg小粉嫩'
s26 = s.replace('小粉嫩', '大铁锤')
print(s26)

replace('a','b',c) a为被替换的内容,b为替换后的内容,c为数字,意为从左至右将前c个a替换为b。
s = '小粉嫩小粉嫩ghlasdfg小粉嫩'
s27 = s.replace('小粉嫩', '大铁锤', 2)
print(s27)
公共方法:
len() 统计字符串的总个数。
s = 'fdsajlskgjdsaf;jdskfsdaf' print(len(s))

count() 计算某些元素出现的个数,可切片。
s = 'fdsajlskgjdsaf;jdskfsdaf'
s28 = s.count('f')
print(s28)

format 格式化输出
三种方式:
1、
{} 占位符
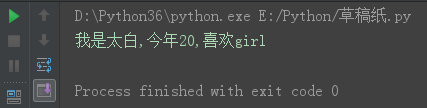
msg = '我是{},今年{},喜欢{}'.format('太白', '20','girl')
print(msg)
2、
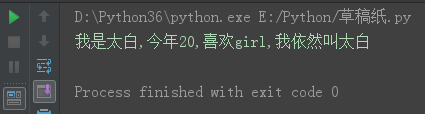
msg = '我是{0},今年{1},喜欢{2},我依然叫{0}'.format('太白', '20','girl')
print(msg)

3、 \ 换行符
msg = '我是{name},今年{age},喜欢{hobby},我依然叫{name}'\
.format(name = '太白', age = '20',hobby = 'girl')
print(msg)
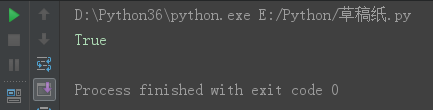
isalnum() 字符串由字母或数字组成。
name = 'jinxin123' print(name.isalnum())
isalpha() 字符串只由字母组成。
name = 'jinxin123' print(name.isalpha())

isalnum() 字符串只由数字组成。
name = 'jinxin123' print(name.isdigit())

for循环:
for i in 可迭代对象:
pass
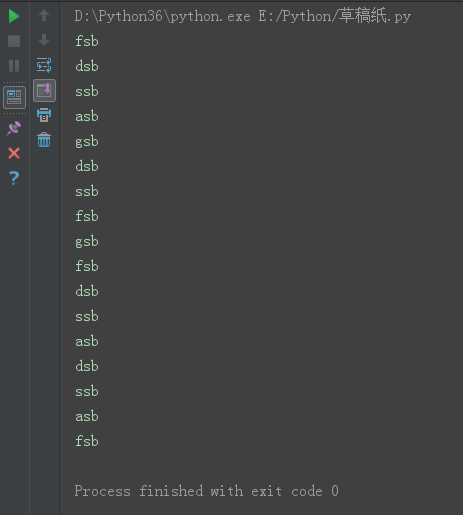
s = 'fdsagdsfgfdsadsaf'
count = 0
while count < len(s):
print(s[count])
count += 1

s = 'fdsagdsfgfdsadsaf'
for i in s:
print(i + 'sb')
3、bool
int <-----> str
str -----> int :int(str) 条件: 字符串必须全部由数字组成。
age = int(input(">>>"))
print(age,type(age))
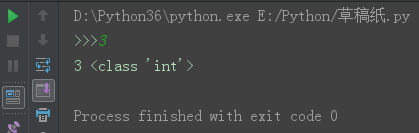
int ----->str :str(int)
s1 = str(123) s2 = 123 print(s1, type(s1)) print(s2, type(s2))

bool <-----> int True ----->1 False ----->0
print(int(True))

print(int(False))

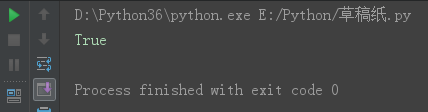
int ----->bool 非零即为Ture,零为False。
print(bool(100))
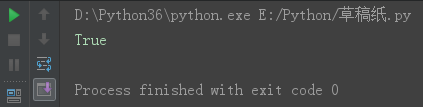
print(bool(0))

print(bool(-1))
bool -----> str str(True) str(False)
str -----> bool 非空即为True,''空字符串为False。
s1 = ''
if s1:
print(666)

4、list
['name',Ture,[]....] 各种类型的数据,大量数据,便于操作。
5、tuple 元组
() 只读列表,可读不可写。
6、dict
{'name':'老男孩',
'name_list':['反面教材',......]
'alex':{'age':40,
'hobby':'oldwomen',
}
},
存储大量的数据,关系型数据。
7、set
{'wusir','alex',...}