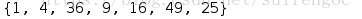字典生成式
1: 假设有20个学生,学生分数在60-100之间,筛选出成绩在90分以上的学生
方法一
import random
stuInfo={}
for i in range(20):
name = "westos"+ str(i)
score = random.randint(60,100)
stuInfo[name] = score
stuInfo["westos"+ str(i)] = random.randint(60,100)
print(stuInfo)
# 筛选出score>90
highScore = {}
for name, score in stuInfo.items():
if score > 90:
highScore[name] = score
print(highScore)
方法二 字典生成式
import random
stuInfo = {"westos"+ str(i):random.randint(60,100)for i in range(20)}
print(stuInfo)
# 筛选出score>90
print({ name:score for name, score in stuInfo.items() if score > 90 })
- 假设已有若干用户名字及其喜欢的电影清单,现有某用户, 已看过并喜欢一些电影, 现在想找新电影看看, 又不知道看什么好.
思路:
根据已有数据, 查找与该用户爱好最相似的用户,
即看过并喜欢的电影与该用户最接近,
然后从那个用户喜欢的电影中选取一个当前用户还没看过的电影进行推荐.
userInfo = {
'user1':{'file1', 'file2', 'file3'},
'user2':{'file2', 'file2', 'file4'},
}
# # 1. 随机生成电影清单
import random
data = {} # 存储用户及喜欢电影清单的信息;
for userItem in range(10):
files = set([])
for fileItem in range(random.randint(4,15)):
files.add( "film" + str(fileItem))
data["user"+str(userItem)] = files
print(data)
import pprint
pprint.pprint({
"user"+str(userItem):
{"film" + str(fileItem) for fileItem in range(random.randint(4,15))}for userItem in range(10) })
3.将字典的key值和value值调换;
d = {'a':'apple', 'b':'bob', 'c':'come'}
print({v:k for k,v in d.items()})
print({k:k.upper() for k,v in d.items()})
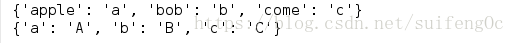
4.大小写计数合并 : key值最终全部为小写.
d1 = {'A':10, 'b':3, 'a':5, 'B':8, 'd':1}
print({k.lower(): d1.get(k.upper(),0)+d1.get(k.lower(),0) for k,v in d1.items()})
# print({k.lower(): d1[k.upper()]+d1[k.lower()] for k,v in d1.items()}) # 报错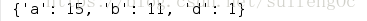
集合生成式
s = {1,2,3,4,5,6,7}
# 集合生成式
print({i**2 for i in s })