一、列表生成式
列表生成式,是Python内置的一种极其强大的生成list的表达式。
1、举个简单的例子:在1~10中随机的取10个数子
import random
li = []
for i in range(10):
li.append(random.randint(1,10))
print(li)

我们看到上面的代码并不陌生,随机取10个数字并且添加到列表li中,我们不妨简化代码量,能否在一行中解决;
import random print([random.randint(1,10) for i in range(10)])注意:导入的random模块时产生随机数,random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b

这里产生了10个1~10的随机数,并且遍历这10个数,最后得到的结果就为一个10个随机数的列表,在这里我们用一行代替了4行代码;
但是我想在这里说:这样的代码在以后的工作中尽量避免,虽然它体现了python语言的简洁性,但是这也为以后自己在复看自己的代码时留下了隐患,因为我们都知道代码不是写给自己看,我们要为以后的人留下可读性高、简介分明的代码。
2、升级练习:找出1~20中的所有偶数
print([i for i in range(1,21) if i%2==0])
注意:range在这里实际产生的数是1~20,并没有21;

我们在写列表生成式时,返回值放在最前面,for循环和判断语句依次按照代码逻辑向后排开;
3、找出1~100之间所有的素数
def isprime(num):
count = num //2
while count > 1:
if num % count ==0:
break
count -= 1
else:
print("%s是一个素数"%(num))
print([i for i in range(1,101) if isprime(i)])

4、让‘ABC‘与’123‘一一对应起来
如:‘A1’‘A2’‘A3’‘B1’‘B2’‘B3’‘C1’‘C2’‘C3’
print([i+j for i in 'ABC' for j in '123'])

5、找出/var/log/目录中,所有以.log结尾的文件名或者目录名;
import os
print([filename for filename in os.listdir('/var/log') if filename.endswith('.log')])
os.listdir(dirname):列出dirname下的目录和文件;

导入os模块,遍历/var/log文件夹下的所有文件和目录,filename.endwith 以.log结尾的文件或目录
6、 将列表中所有内容都变为小写;
li = ['frdgrfgdsHHJJ', 'cdsfregHHHJDGF'] print([i.lower() for i in li])

二、字典生成式
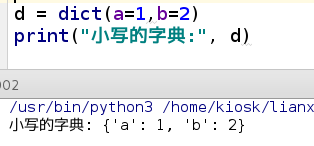
1、给定一个字典,把这个字典打印出来;d = dict(a=1,b=2)
和我们之前学的没有什么区别,但是我现在需要将字典的key值全部变为大写;
d = dict(a=1,b=2)
new_d = {}
for i in d: # 'a' 'b'
new_d[i.upper()] = d[i]
print("key转化为大写的字典:", new_d)

使用传统方法不难达到需求,创建一个新的字典,遍历d这个字典,把b中的key值赋给i,i.upper语句让b中的key变成大写,并且把value值对应起来,最后打印这个新的字典。
2、尝试使用字典生成式完成上面的需求;
print({k.upper():v for k,v in d.items()})

3、需求3:将大小写key值合并, 统一以小写key值输出;
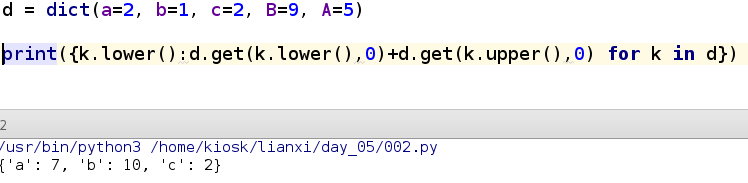
例如:字典:d = dict(a=2, b=1, c=2, B=9, A=5)
输出:a=7,b=10,c=2
我们不妨先用传统方式写写看,理理思路:key值既有大写也有小写,最后求同一个字母(不论大小写)的合,A+a,B+b,C+c;我们创建一个新的字典,把大写的变为小写,和本身就是小写的元素一起放进新的字典里;在放的过程中如果字典中那里没有这个key值,那我们就把相对应的key--value一起放进去,如果放进去发现有重复的key值,我们则把他们的value值相加,最后得到的新字典就是我们需求的结果。
d = dict(a=2, b=1, c=2, B=9, A=5)
new_d = {}
for k, v in d.items():
low_k = k.lower()
if low_k not in new_d:
new_d[low_k] = v
else:
new_d[low_k] += v
print(new_d)

上面的传统方法,不论是写起来还是读起来都是比较流畅的,尝试使用字典生成式能否达到需求;
d = dict(a=2, b=1, c=2, B=9, A=5)
print({k.lower():d.get(k.lower(),0)+d.get(k.upper(),0) for k in d})
字典生成式一行就可以达到我们的需求,在我这个技术小白的世界望去它还是有一丝丝的模糊,除非你就是那个技术大佬,个人更倾向传统方式,读起来更清晰,更加能够直观的告诉别人你的这段代码是要干什么。
三、集合生成式
集合生成式:集合生成式格式和列表生成式类似,不过用的是大括号;
我们使用传统方法来实现集合的运算
set1 = set()
for i in {1, 2, 3,4}:
set1.add(i**2)
print(set1,type(set1))

显然有些许的繁琐;如果是集合生成式呢?
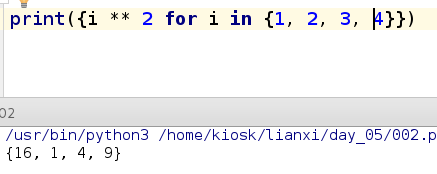
print({i ** 2 for i in {1, 2, 3}})
需求升级:我们要求算出10以内能被三整除的数的平方;
传统方式:
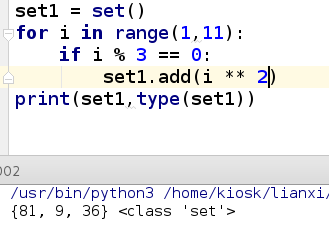
set1 = set()
for i in range(1,11):
if i % 3 == 0:
set1.add(i ** 2)
print(set1,type(set1))
如果我们用集合生成式呢?
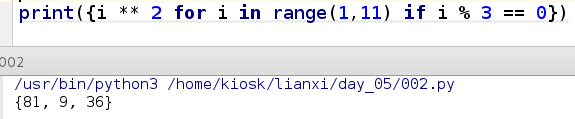
print({i ** 2 for i in range(1,11) if i % 3 == 0})
四、迭代
迭代:iterable:;可迭代的; 可以for循环;
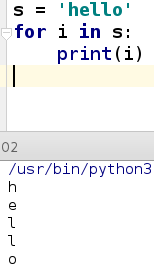
字符串是可迭代对像;
我们在写代码时经常能够遇到“set changed size during iteration”这样的话,为了避免地带出现的错误我们可以用下面的语句来判断;
from collections import Iterable
isinstance(1, int)
print(isinstance(1,Iterable))
print(isinstance({1,2,3},Iterable))

从collections中导入Iterable模块,判别某个是否为可迭代对象,返回值为Ture 或 False
五、打印斐波那契数列
什么是斐波那契数列:1 1 2 3 5 8 13 21 34 55 ....
def fib(num):
a, b, count = 0, 1, 1 # 0, 1
while count <= num:
print(b)
a, b = b, a + b #a=2, b=3
count += 1
fib(15)
