版权声明:@Author 犯罪嫌疑人卢某 洒家辛苦总结 希望尊重洒家的劳动哟 https://blog.csdn.net/unscdf117/article/details/79070141
最近病了,病的很厉害.人发烧了,顶着头疼去了网易考拉进行二面.然后让人给怼了,认识了两位大佬加了微信,总算是没有白去..泽州大佬告诉我,要学会思考,不要做代码机器…
回到家里,瘫在沙发上一动不想动..
之前博文中有讲到Redis的一些使用方式和一些场景以及发生的一些问题.现在我总结一下Reids的PipeLine,也就是管道.
Redis的管道可以在大量数据需要一次性操作完成的时候,使用Pipeline进行批处理,将一大队的操作合并成一次操作,可以减少链路层的时间消耗,毕竟频繁操作是不好的嘛.
Redis有很多客户端可供使用 我这里以Jedis为例.做一个简单的小测试,管道的效果一目了然.
先上一段代码:
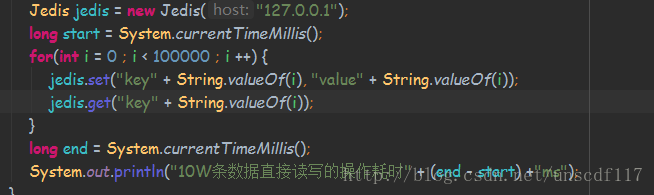
我使用Jedis客户端 先在本地测试Redis 10W条数据的读写
测试结果:
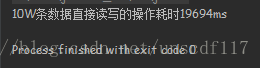
10W条数据本地操作耗时19694ms 将近20000毫秒..
现在我使用Pipeline 代码也相应改动一下:

现在在代码当中通过Jedis.pipeline();获取到一个pipeline对象,通过pipeline去操作Redis读写
测试结果:

结果仅仅使用了671ms
在本地运行的情况下性能差距就已经如此明显,更何况是在互联网项目当中,如果是频繁的操作Redis,使用管道技术去进行操作是可取的.不仅减少服务器压力,还能减少链路层中的时间消耗,批量处理频繁的操作,将大量操作结合成少量的操作..这是十分可取的.
PipeLine的强大已经是非常直观的了,那么具体的实现光靠猜是不行的,必须去阅读对应的源码.
扫描二维码关注公众号,回复:
3051128 查看本文章
