一、准备好数据集

二、需求分析
案例分析:美国各州人口数据分析
作业知识补充
首先导入文件,并查看数据样本
合并pop与abbrevs两个DataFrame,分别依据state/region列和abbreviation列来合并。
为了保留所有信息,使用外合并。
查看存在缺失数据的列。
使用.isnull().any(),只有某一列存在一个缺失数据,就会显示True。
查看缺失数据
根据数据是否缺失情况显示数据,如果缺失为True,那么显示
找到有哪些state/region使得state的值为NaN,使用unique()查看非重复值
为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN!
记住这样清除缺失数据NaN的方法!
合并各州面积数据areas,使用左合并。
思考一下为什么使用外合并?
继续寻找存在缺失数据的列
我们会发现area(sq.mi)这一列有缺失数据,为了找出是哪一行,我们需要找出是哪个state没有数据
去除含有缺失数据的行
查看数据是否缺失
找出2010年的全民人口数据,df.query(查询语句)
对查询结果进行处理,以state列作为新的行索引:set_index
计算人口密度。注意是Series/Series,其结果还是一个Series。
排序,并找出人口密度最高的五个州sort_values()
找出人口密度最低的五个州
要点总结:
- 统一用loc()索引
- 善于使用.isnull().any()找到存在NaN的列
- 善于使用.unique()确定该列中哪些key是我们需要的
- 一般使用外合并、左合并,目的只有一个:宁愿该列是NaN也不要丢弃其他列的信息
三、操作实例
1.导入三剑客:
import numpy as np
import pandas as pd
from pandas import Series,DataFrame2.导入文件
abb=pd.read_csv('../data/state-abbrevs.csv')
areas=pd.read_csv('../data/state-areas.csv')
pop=pd.read_csv('../data/state-population.csv')3.查看数据结构

4.实现需求
① 合并pop与abbrevs两个DataFrame,分别依据state/region列和abbreviation列来合并。
【为了保留所有信息,使用外合并】
abb_pop=pd.merge(abb,pop,left_on='abbreviation',right_on='state/region',how='outer')
abb_pop.head()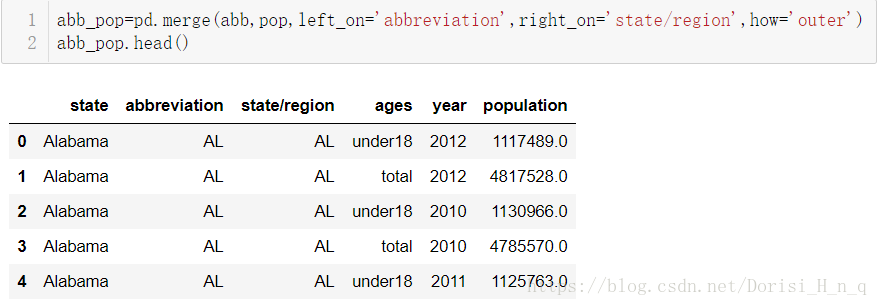
②删除重复的列: .drop('abbreviation',axis=1,inplace=True)
#删除重复的列
abb_pop.drop('abbreviation',axis=1,inplace=True)
abb_pop.head()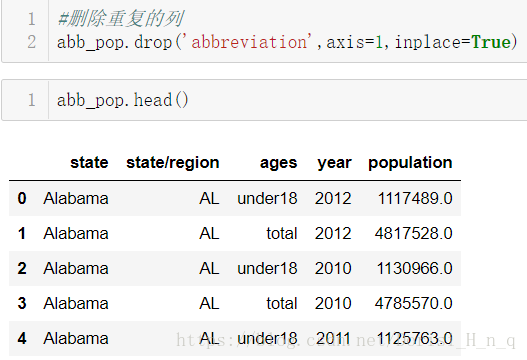
③查看存在缺失数据的列: 使用.isnull().any(),只有某一列存在一个缺失数据,就会显示True。
abb_pop.isnull().head() #如果df中存在空值,则空值对应的行列位置显示的是True
abb_pop.isnull().any(axis=0) #检查每一列中是否存在空值(True)
#运行结果发现只有state和population中存在空值
④查看缺失数据【根据数据是否缺失情况显示数据,如果缺失为True,那么显示】
#查看的是population列中空值所对应的行信息------------
misspop=abb_pop['population'].isnull() #找出pop这一列中所有的空值,如果是空值则返回True
misspop
abb_pop.loc[misspop] #获取了pop空值所对应的行数据
#查看的是state这一列中空值存在情况------------------
missState=abb_pop['state'].isnull()#如果该列中某一个数组元素为空值则显示True
missState
#将上一步返回的布尔列表作为行索引
State=abb_pop.loc[missState]
State⑤找到那些state的值为NAN,使用unique()查看非重复值
state['state/region'].unique()
#unique()是Serise的一个函数,该函数可以对Serise中的数组元素进行去重
Output: array(['PR', 'USA'], dtype=object)为找到的这些state/region的state项补上正确的值,从而去除掉state这一列的所有NaN!
abb_pop['state/region']=='PR'
#返回一组布尔值,True表示True所在位置的元素值为PR。
#获取的这组布尔值的意义在于想要将其作为行索引,
#目的是为了获取一个或者一组数组元素,将数组元素进行修改。
abb_pop.loc[abb_pop['state/region']=='PR','state']='PUERTO RICO'
abb_pop.loc[abb_pop['state/region']=='USA','state']='United State'测试是否还存在空数据,使用isnull(),出现False表示没有空值
abb_pop['state'].isnull().any()
Output:False⑥合并各州面积数据araes,使用左合并
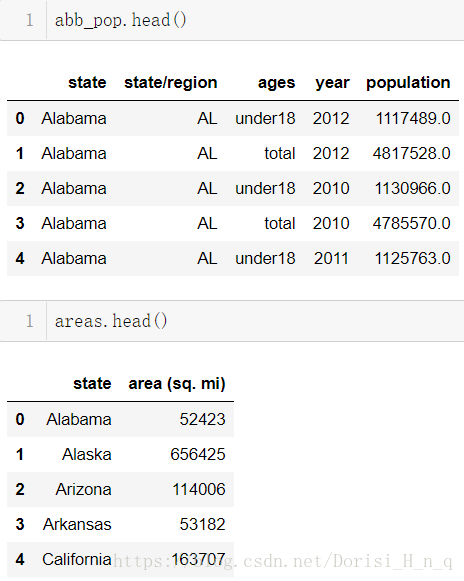
abb_pop.head()
areas.head()
abb_pop_areas=pd.merge(abb_pop,areas,how='left')
abb_pop_areas⑦继续寻找缺失的数据的列
abb_pop_areas.isnull().any()
- 发现area(sq.mi)这一列有缺失值,为了找出是哪一行,需要找到那个state没有数据
abb_pop_areas['area (sq. mi)'].isnull()
abb_pop_areas.loc[abb_pop_areas['area (sq. mi)'].isnull()]
#获取行索引
indexs=abb_pop_area.loc[abb_pop_area['area (sq. mi)'].isnull()].index去除含有缺失数据的行
abb_pop_areas.drop(indexs,axis=0,inplace=True)⑧找出2010年的全民人口数据,df.query(查询语句)
abb_pop_areas.head()
data_2010=abb_pop_areas.query("year==2010 & ages=='total'")
data_2010.head()
⑨对查询结果进行处理,以state列作为新的行索引:set_index
data_2010['state']
data_2010_index=data_2010.set_index(data_2010['state'])
data_2010_index.head()⑩计算人口密度【注意是Series/Series,其结果还是一个Series。】
data_2010_index['population']/data_2010_index['area (sq. mi)']
data_2010_index['midu']=data_2010_index['population']/data_2010_index['area (sq. mi)']
data_2010_index.head()
⑪排序,并找出人口密度最高的5个州 : sort_values
data_2010_index.sort_values(by='midu',axis=0,ascending=False).head()找出人口密度最低的五个州
data_2010_index.sort_values(by='midu',axis=0,ascending=False).tail()