声纹识别定义
声纹识别是通过对一种或多种语音信号的特征分析来达到对未知声音辨别的目的。声纹识别的理论基础是每一个声音都具有独特的特征,通过该特征能将不同人的声音进行有效的区分。
这种独特的特征主要由两个因素决定
- 第一个是声腔的尺寸,具体包括咽喉、鼻腔和口腔等,这些器官的形状、尺寸和位置决定了声带张力的大小和声音频率的范围。因此不同的人虽然说同样的话,但是声音的频率分布是不同的,听起来有的低沉有的洪亮。每个人的发声腔都是不同的,就像指纹一样,每个人的声音也就有独特的特征。
- 第二个决定声音特征的因素是发声器官被操纵的方式,发声器官包括唇、齿、舌、软腭及腭肌肉等,他们之间相互作用就会产生清晰的语音。而他们之间的协作方式是人通过后天与周围人的交流中随机学习到的。人在学习说话的过程中,通过模拟周围不同人的说话方式,就会逐渐形成自己的声纹特征。
因此,理论上来说,声纹就像指纹一样,很少会有两个人具有相同的声纹特征。
语音具备了一个良好的性质,称为短时平稳,在一个20-50毫秒的范围内,语音近似可以看作是良好的周期信号,因此一般处理语音都是用20-50ms分帧处理。
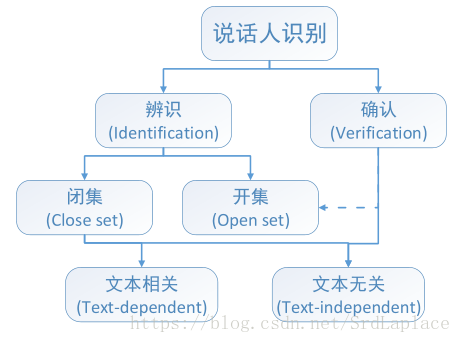
声纹识别分类
文本无关识别,文本相关识别;说话人辨认,说话人确认;开集,闭集等。
预处理
VAD,去噪,解混响,speaker separation等。
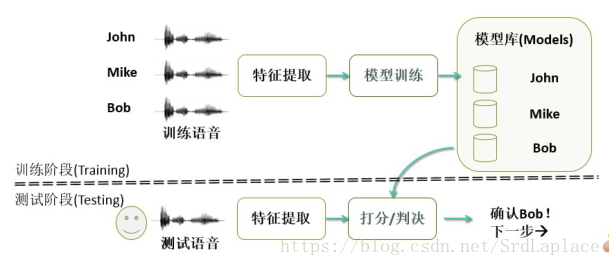
声纹识别的评价指标
1.等错误概率EER:当FA和FR相等时的错误概率
2.最小检测代价:
,
和
是代价因子。
3.DET曲线(detection error tradeoff):FA和FR的曲线
数据集
NIST SRE
RSR2015 Text-Dependent
VAD
短时能量:取20ms为一帧,然后用3高斯混合模型拟合,取
作为分分界,来确定是否有声音。(
为经验值,通常取1.5到2,mid为中间高斯分量)
加权有限状态转移(WFST):用静音和一些说话声音训练一个HMM,然后进行VAD,缺点是需要标注数据。
特征
MFCC梅尔倒频系数:原理人耳对低频比高频敏感,流程signal-FFT-三角滤波器-DCT-MFCC
PLP感知线性预测:线性预测的系数(自相关)。
动态因子:MFCC和PLP都是对短时语音帧提取的特征,前后做差可以得到动态因子
高斯混合模型
对于一个
维特征向量
,混合概率密度定义为

是
个unimodal(单峰) Gaussian densities
之和, 每个高斯分布的参数有一个
维的均值向量
,和一个
维的协方差矩阵
:
混合权重 满足 。模型记为 , where .
这里我们把 限定为对角阵,这是因为对角阵有3个好处:1.full covariance GMM可以被更高阶的diagonal covariance GMM等效表示;2.diagonal-matrix GMMs计算效率更高,因为公式中有大量的求逆,转置之类的;3.根据经验,我们观察到对角矩阵GMM优于全矩阵GMM。
给定训练特征向量集,可以使用EM算法估计最大似然模型参数。
通常假设特征向量
,之间是独立的,那么给定参数
下的似然概率为
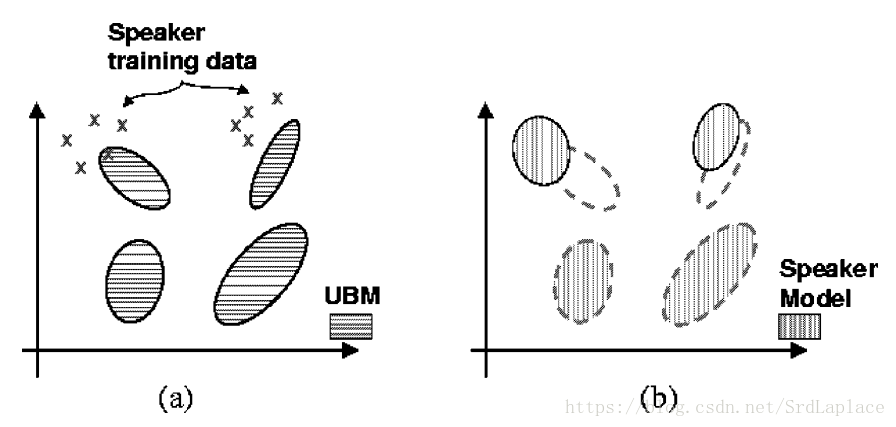
GMM-UBM
UBM是指根据所有说话人(有标签+没标签)训练出的高斯混合模型,作为说话人识别的先验分布。
在GMM-UBM系统中,我们通过使用说话人的训练语音和贝叶斯自适应的方法调整UBM的参数来推导出说话人模型。自适应方法的基本思想是通过更新UBM中训练好的参数来推导说话者的模型。这提供了说话人模型和UBM之间更紧密的耦合,这不仅比解耦模型产生更好的性能,而且评分更快速。
给定UBM和对应某个speaker的训练向量
,我们首先将每个向量与UBM中的高斯分布对应,也就是说对于UBM第
个高斯分量,我们计算
然后用
和
计算权重,均值和方差的统计量:
这和普通的EM算法expectation step相同。然后用这些统计量更新UBM中的参数:
是保证
和为1的缩放因子。参数
是控制新旧变量的平衡,被定义为:
是固定的相关因子。更新公式可以看作是最大后验概率估计(MAP)。如果某个高斯分量的 很低,那么对应的 也就很小,那么更新时会更强调旧的(训练好)的均值和方差。反之会更倾向用新的数据来更新模型。这样会使得对于训练数据受限的情况下的鲁棒性更强。本文中我们取所有的 。当取 时,GMM-UBM就退化成普通的EM算法了。
Log-Likelihood Ratio Computation
测试序列的log-likelihood ratio为 。由于 是从 中更新来的,许多分量并没有更新,所以log-likelihood ratio可以被the top C best scoring近似;而且GMM和UBM中的分量一一对应。可以利用上述的两个trick加快评分过程。
Handset Score Normalization
对于不同信道的样本可以通过调整模型的均值和方差来提升准确率。
JFA and i-vector
因子分析是把声音向量分解为 , 是speaker- and session-independent supervector(UBM),V和D为说话人的子空间(分别是本征话音矩阵和对角残差),U是会话子空间(eigenchannel matrix)。向量 是Normal distribution ,表示对应子空间的随机变量。i-vector是把声音 ,然后通过EM算法求解出各个分量。然后进行相当于提取特征+降维(200-400多维度)。然后用cosine距离或者PLDA进行分类。
Deep Speaker: an End-to-End Neural Speaker Embedding System - Baidu Inc.
将信号变到频域上,然后用ResNet或者GRU提取特征,用triplet loss做损失函数
triplet loss
在FaceNet中,作者提出了基于度量学习的误差函数Triplet loss,其思想来源如下:
其中Anchor
为训练数据集中随机选取的一个样本,Positive
为和Anchor属于同一类的样本,而Negative
为和Anchor不同类的样本。
该不等式本质上定义了同类样本和异类样本之间的距离关系,即:所有同类样本之间的距离+阈值threshold,要小于异类样本之间的距离。当距离关系不满足上述不等式时,我们可通过求解误差函数,通过反向传播算法来调节整个网络:
利用该公式可分别计算出
、
和
的梯度方向,并根据反向传播算法调节前面的网络。
center loss
Center loss是ECCV2016中一篇论文提出来的概念,主要思想就是在softmax loss基础上额外加入一个正则项,让网络中每一类样本的特征向量(softmax前的向量)都能够尽量聚在一起。
表示第
个类别的中心,梯度为:
整体的loss为 , 控制center loss和交叉熵的比重,通过梯度更新权重,通过 更新中心。
tuple-based end-to-end (TE2E) model:
对于每个输入元组,我们计算LSTM的L2归一化响应:
。这里每个
是固定维度的嵌入向量,其由LSTM定义的序列向量映射产生。元组的质心为
$$c_k=E[e_{km}]=\frac{1}{M}\sum_{i=1}^Me_{km}$
使用余弦相似度函数定义相似性:
是learnable。TE2E loss定义为:
是sigmoid函数,当 时,TE2E损失函数鼓励更大的 值,而当 时,鼓励更小的 值。考虑正元组和负元组的更新-与FaceNet中triplet loss非常相似。
GENERALIZED END-TO-END LOSS FOR SPEAKER VERIFICATION - Google Inc.
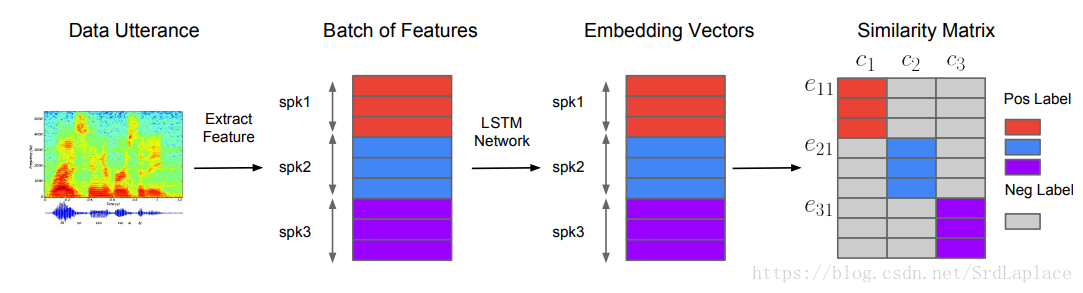
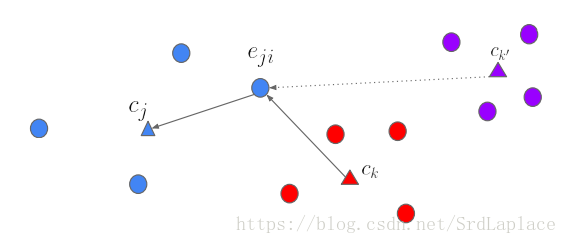
用
段语音做一个batch(N个speakers,每个speaker有M段语音)。
表示从speaker
的第
段语音提取的特征。
embedding vector (d-vector)被定义为:
第j个speaker的embedding vectors的质心(centroid)被定义为
。
The similarity matrix被定义为 ( and are learnable parameters)。限定 为正,因为我们希望余弦相似度越大,相似度越大。我们希望通过训练使得相同speaker的embedding和他们的质心相似度很高,而不同speaker的embedding和相似度很低。给定embedding vector ,所有质心 ,和the corresponding similarity matrix ,有两种方式实现上面说的情况:
- Softmax:
- Contrast: , 是sigmoid函数
每种loss都在再一定情况下有好的表现(contrast loss performs better for TD-SV, while softmax
loss performs slightly better for TI-SV)。
我们发现当计算 时,去掉自己的质心有更稳定的表现
综上可得:
GE2E比TE2E更有效率。
Overview
声纹识别的发展:
1.高斯混合模型enroll进去所有人声纹的分布,来一段未知声音判断他是哪个人声音的概率最大,存在的问题就是参数过多,训练数据不足够,而且对声音的信道敏感;
2.GMM-UBM判断把所有的声音训练一个UBM作为先验分布,然后针对不同人微调GMM,加快了训练和验证的时间,减少了参数,缓解了一些数据量的要求,对声音的信道敏感;
3.JFA和i-vector,我的理解就是把信道作为单独的变量,把数据embedded到低维空间,对信道的鲁棒性提高了;
4.d-vector是深度学习阶段的产物,直接end2end,不用单独提取特征,把声纹embedding到一个向量上,利用向量的相似度来判断。