String、StringBuilder、StringBuffer算得上是一个老生常谈的问题了,在实际使用中会经常用到这些类,了解这些类的使用和原理是十分必要的,本文将根据JDK1.8的源码分析。
一、String类
先来看String类的源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
//存储字符串字符的char数组
private final char value[];
//hashCode缓存,只有当第一次调用了hashCode方法时才会被赋值,以后调用该方法时直接返回该变量
private int hash;
//省略所有的方法和静态变量
}单凭上述源码可以总结出:
1、String类不可被继承:该类被final修饰。
2、String类是不可变的:value[]被final修饰,可以将String看成是对char数组的一个封装。
3、String类可以序列化,可以和其他String比较其大小:实现了Comparable接口
String类提供了大量的API处理字符串,但是无论怎么操作,原有的String都是不变的,调用类似substring、concat方法都会返回一个全新的String对象。
下面是一个经典的问题:
public class Test {
public static void main(String[] args) {
String a = "abc";
String b = new String("abc");
String c = new String("abc");
String d = b.intern();
System.out.println(a == b);
System.out.println(b == c);
System.out.println(a == d);
}
}运行上述代码,输出结果是什么?
答案是:
false
false
true
这是为什么呢?
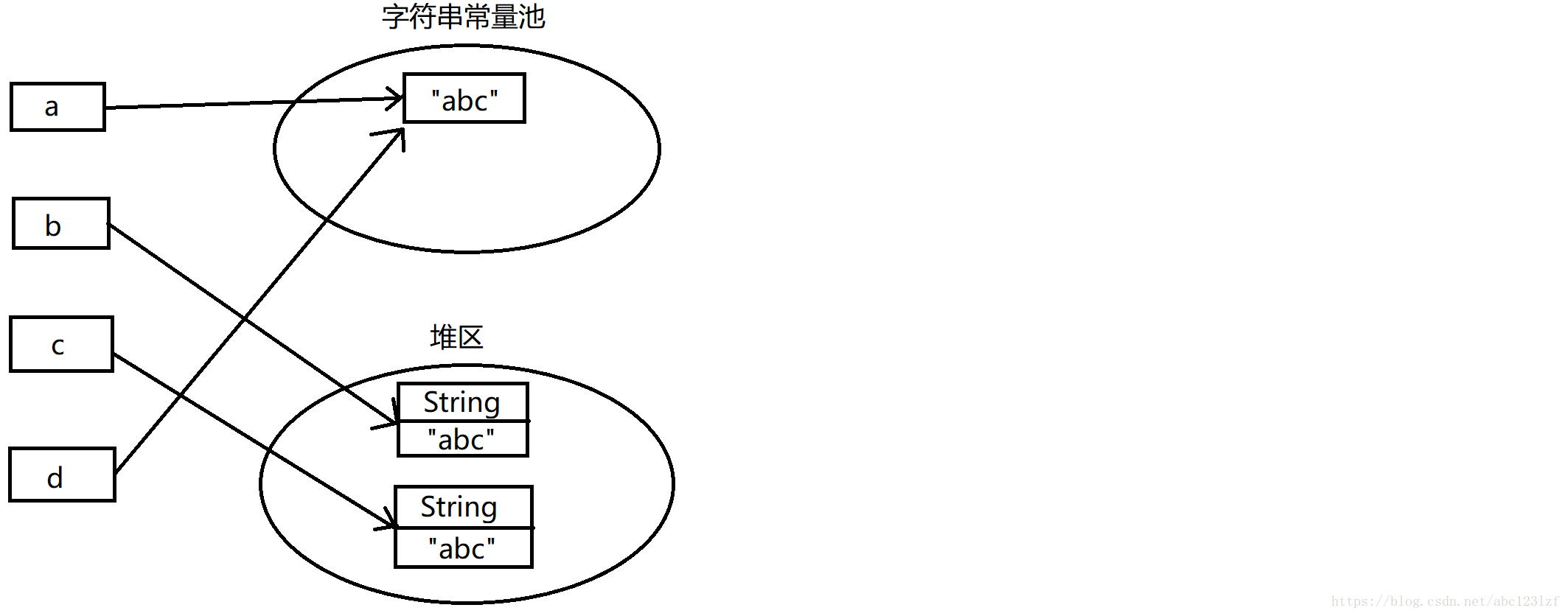
在JVM中,为了减少内存的消耗,存在一个称为字符串常量池的区域。当我们通过String a = “abc”这样创建一个字符串对象时,JVM会首先在字符串常量池中寻找这个字符串,若存在,则将a直接指向该字符串,若不存在,则在常量池中创建该字符串并将a指向它,所以a==d返回true。当我们通过String b = new String(“abc”)这样创建字符串时,情况就不一样了,它会在堆区创建该字符串对象并使b指向它,同样调用String c = new String(“abc”)时,也会在堆区再创建一个String对象并使c指向它,JVM并不会判断堆区是否存在其它相同的String对象,所以b==c返回false。当调用String d = b.intern();时,intern方法(该方法为native方法)会在字符串常量池中查找是否存在该字符串对象,如果存在,则将d指向该常量池中的字符串对象,如果不存在则在常量池中创建该字符串并指向它,所以a==d返回true。
二、StringBuilder
StringBuilder经常用在需要对字符串进行大量操作的地方,它可以非常高效的对字符串进行拼接等操作。
可能会有人问:我同样可以用+号来拼接字符串啊,为什么还要用到StringBuilder?
如果你提出了这样一个疑问,请看下面代码:
public class Test {
public static void main(String[] args) {
String s = "";
long st = System.currentTimeMillis();
for(int i = 0; i < 100000; i++) {
s += "a";
}
long ed = System.currentTimeMillis();
System.out.println("时间:" + (ed - st) + "毫秒");
st = System.currentTimeMillis();
StringBuilder sb = new StringBuilder();
for(int i = 0; i < 100000; i++) {
sb.append("a");
}
ed = System.currentTimeMillis();
System.out.println("时间:" + (ed - st) + "毫秒");
}
}运行上述代码,输出:
时间:2735毫秒
时间:2毫秒
可以看出,在大量对字符串进行连接操作的情况下,StringBuilder优势非常明显。下面我们根据上述例子,来逐步了解StringBuilder。
先贴出StringBuilder的源码:
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
public StringBuilder() {
super(16);
}
public StringBuilder(int capacity) {
super(capacity);
}
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
public StringBuilder(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
//省略其他方法
}StringBuilder继承了AbstractStringBuilder,和String一样实现了CharSequence和Serializable接口。
StringBuilder提供了4个构造器,无参构造器默认创建一个长度为16的char数组,作为存储字符串的缓冲区。用户也可以传入一个int参数指定该缓冲区的大小,也同样可以传入一个初始字符串。字符串存储的实现在其父类AbstractStringBuilder类中。
下面来看AbstractStringBuilder源码:

abstract class AbstractStringBuilder implements Appendable, CharSequence {
//存储字符串的char数组
char[] value;
//字符串的长度
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
public AbstractStringBuilder append(String str) {
//如果str为null,则直接往后拼接"null"
if (str == null)
return appendNull();
int len = str.length();
//确保value数组的长度足够,不会越界
ensureCapacityInternal(count + len);
//将str从value[count]开始拼接
str.getChars(0, len, value, count);
//更新数组长度
count += len;
return this;
}
//扩展value数组的长度,minimumCapacity的值为新char数组的长度
private void ensureCapacityInternal(int minimumCapacity) {
if (minimumCapacity - value.length > 0) {
//将旧数组的值拷贝到新数组
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
//省略其它方法...
}和String不同的是,value数组的长度并不代表字符串的实际长度,而是采用一个变量count记录字符串长度。每当调用append、insert、reverse方法时,会首先判断value长度是否充足,如果长度不够,则会重新分配一个新的char数组并将旧数组拷贝进去,再进行拼接。如果长度足够,则直接将需要拼接的字符串加在数组后面,再修改count的值即可。
当我们需要获取StringBuilder的字符串时,直接调用toString即可,toString方法在StringBuilder中默认是将value数组从0~count截取并返回一个全新的String对象。
了解StringBuilder拼接原理后,我们再来分析为什么在大量的拼接操作时String速度会明显慢于StringBuilder。
public class Test {
public static void main(String[] args) {
String s = "";
for(int i = 0; i < 100000; i++) {
s += "a";
}
System.out.print(s);
}
}将上述代码编译成class文件,通过eclipse自带的class文件分析工具得到main方法的字节码:
public static void main(java.lang.String[] args);
0 ldc <String ""> [16]
2 astore_1 [s]
3 iconst_0
4 istore_2 [i]
5 goto 31
8 new java.lang.StringBuilder [18]
11 dup
12 aload_1 [s]
13 invokestatic java.lang.String.valueOf(java.lang.Object) : java.lang.String [20]
16 invokespecial java.lang.StringBuilder(java.lang.String) [26]
19 ldc <String "a"> [29]
21 invokevirtual java.lang.StringBuilder.append(java.lang.String) : java.lang.StringBuilder [31]
24 invokevirtual java.lang.StringBuilder.toString() : java.lang.String [35]
27 astore_1 [s]
28 iinc 2 1 [i]
31 iload_2 [i]
32 ldc <Integer 100000> [39]
34 if_icmplt 8
37 getstatic java.lang.System.out : java.io.PrintStream [40]
40 aload_1 [s]
41 invokevirtual java.io.PrintStream.print(java.lang.String) : void [46]
44 return
Line numbers:
[pc: 0, line: 6]
[pc: 3, line: 7]
[pc: 8, line: 8]
[pc: 28, line: 7]
[pc: 37, line: 10]
[pc: 44, line: 11]
Local variable table:
[pc: 0, pc: 45] local: args index: 0 type: java.lang.String[]
[pc: 3, pc: 45] local: s index: 1 type: java.lang.String
[pc: 5, pc: 37] local: i index: 2 type: int
Stack map table: number of frames 2
[pc: 8, append: {java.lang.String, int}]
[pc: 31, same]分析字节码,可以看出字符串+=操作实际上是一个语法糖,在每次循环中,都会创建一个StringBuilder对象(指令8),再调用String.valueOf(s)返回字符串对象(指令12、13),接着调用StringBuilder的append方法对字符串”a”进行拼接(指令19、21),最后再调用StringBuilder的toString方法赋值给变量s(指令24、27),单次循环完成。
所以事实上,上述代码其实可以看成:
public class Test {
public static void main(String[] args) {
String s = "";
for(int i = 0; i < 100000; i++) {
StringBuilder sb = new StringBuilder(s);
sb.append("a");
s = sb.toString();
}
System.out.print(s);
}
}每一次循环都会创建一个StringBuilder对象并将字符串s拷贝到自己的value数组,拼接好一个字符串后再调用toString再次创建一个String对象赋值给a,这样频繁的创建对象会造成频繁的GC,而且复制操作又十分耗时,这就是为什么大量的拼接操作中StringBuilder效率要比String好。
三、StringBuffer
public final class StringBuffer extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {
private transient char[] toStringCache;
//省略其它方法
}StringBuffer和StringBuilder一样继承了AbstractStringBuilder,实现了CharSequence和Serializable接口。
StringBuffer和StringBuilder功能一样,不同点在于StringBuffer中的方法大都用了synchronized修饰,它可以在多线程环境下安全的使用,而StringBuilder不是线程安全的。
StringBuffer比StringBuilder多了一个toStringCache缓冲区。
@Override
public synchronized String toString() {
if (toStringCache == null) {
toStringCache = Arrays.copyOfRange(value, 0, count);
}
return new String(toStringCache, true);
}这样在并发环境下大量调用toString方法时,可以减少很多数组复制操作。当然每次更新value数组时都会将toStringCache设为null,保证toString返的是最新的字符串。
相比于StringBuilder,在单线程环境下我们应当尽量使用StringBuilder,它减少了加锁的步骤,效率比StringBuffer更快。而在多线程环境下,应当首先考虑的是线程安全,所以我们应当使用StringBuffer。