开学啦,让我们来看看豆瓣上有什么好书吧
首先当然是很正经地访问一下网页啦
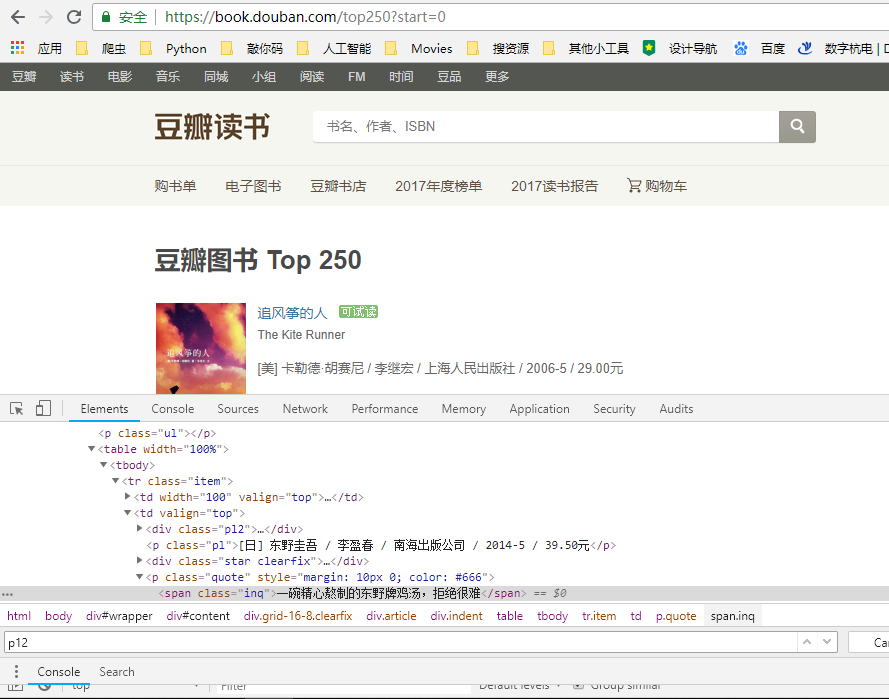
网站网址是https://book.douban.com/top250?start=0
那么我们所需要的内容就是图片旁边的信息了,那就先让虫子爬过去吧,上吧小虫虫!!!
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } resp = requests.get('https://book.douban.com/top250?start=0',headers = headers) # print(resp.text)
好了,get到源代码了,再来看看自己需要的信息在哪里

就是这个,用beautifulsoup解析他!
soup = BeautifulSoup(resp.text,'lxml') alldiv = soup.find_all('div', class_='pl2') # print(alldiv) ''' for a in alldiv: names = a.find('a')['title'] print('find_all():',names) 可以简化为下面两条 ''' names = [a.find('a')['title'] for a in alldiv] print(names)
欧克,同理找到其他信息
allp = soup.find_all('p', class_="pl") authors = [p.get_text()for p in allp] print(authors) starspan = soup.find_all('span',class_="rating_nums") scores = [s.get_text() for s in starspan] print(scores) sumspan = soup.find_all('span',class_="inq") sums = [i.get_text() for i in sumspan] print(sums)
然后我们把资源都统一到一个列表里面
for name, author, score, sum in zip(names,authors,scores,sums):
name = '书名:'+ str(name)+ '\n'
author = '作者:' + str(author) + '\n'
score = '评分:' + str(score) + '\n'
sum = '评价:' + str(sum) + '\n'
data = name + author + score +sum
把他存起来!
filename = '豆瓣图书排名top250.txt' with open(filename,'w',encoding= 'utf-8') as f: f.writelines('data' + '=========================='+'\n') print('OK')
至此第一页的内容我们就抓到了
那我们再来看看翻页的网址


就最后一个数字发生了变化呢,看起来只要对请求的网页改一下就好惹
base_url = 'https://book.douban.com/top250?start=' urllist = [] for page in range(0,250,25): allurl = base_url + str(page) urllist.append(allurl)
那么现在只要把所有的功能对象化,不断爬取、翻页、爬取就好啦
嗯,撸起来
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } resp = requests.get(url, headers = headers) # print(resp.text) return resp def html_parse(): for url in all_page(): soup = BeautifulSoup(get_html(url), 'lxml') alldiv = soup.find_all('div', class_='pl2') # print(alldiv) ''' for a in alldiv: names = a.find('a')['title'] print('find_all():',names) 可以简化为下面两条 ''' names = [a.find('a')['title'] for a in alldiv] # print(names) allp = soup.find_all('p', class_="pl") authors = [p.get_text()for p in allp] # print(authors) starspan = soup.find_all('span', class_="rating_nums") scores = [s.get_text() for s in starspan] # print(scores) sumspan = soup.find_all('span', class_="inq") sums = [i.get_text() for i in sumspan] # print(sums) for name, author, score, sum in zip(names,authors,scores,sums): name = '书名:'+ str(name)+ '\n' author = '作者:' + str(author) + '\n' score = '评分:' + str(score) + '\n' sum = '评价:' + str(sum) + '\n' data = name + author + score +sum f.writelines(data + '=========================='+'\n') def all_page(): base_url = 'https://book.douban.com/top250?start=' urllist = [] for page in range(0,250,25): allurl = base_url + str(page) urllist.append(allurl) return urllist filename = '豆瓣图书排名top250.txt' f = open(filename, 'w', encoding='utf-8') html_parse() f.close() print('OK')
结果出现了报错,喵喵喵?

我们把代码稍微改一下
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } resp = requests.get(url, headers = headers) print(resp.status_code) return resp def html_parse(resp): # for url in all_page(): # get_html(url) # print(resp) soup = BeautifulSoup(resp, 'lxml') alldiv = soup.find_all('div', class_='pl2') # print(alldiv) ''' for a in alldiv: names = a.find('a')['title'] print('find_all():',names) 可以简化为下面两条 ''' names = [a.find('a')['title'] for a in alldiv] # print(names) allp = soup.find_all('p', class_="pl") authors = [p.get_text()for p in allp] # print(authors) starspan = soup.find_all('span', class_="rating_nums") scores = [s.get_text() for s in starspan] # print(scores) sumspan = soup.find_all('span', class_="inq") sums = [i.get_text() for i in sumspan] # print(sums) for name, author, score, sum in zip(names,authors,scores,sums): name = '书名:'+ str(name)+ '\n' author = '作者:' + str(author) + '\n' score = '评分:' + str(score) + '\n' sum = '评价:' + str(sum) + '\n' data = name + author + score +sum f.writelines(data + '=========================='+'\n') def all_page(): base_url = 'https://book.douban.com/top250?start=' urllist = [] for page in range(0,250,25): allurl = base_url + str(page) urllist.append(allurl) return urllist filename = '豆瓣图书排名top250.txt' # f = open(filename, 'w', encoding='utf-8') n = 0 for url in all_page(): n = n+ 1 print(n) get_html(url) # html_parse(resp) # f.close() print('OK')
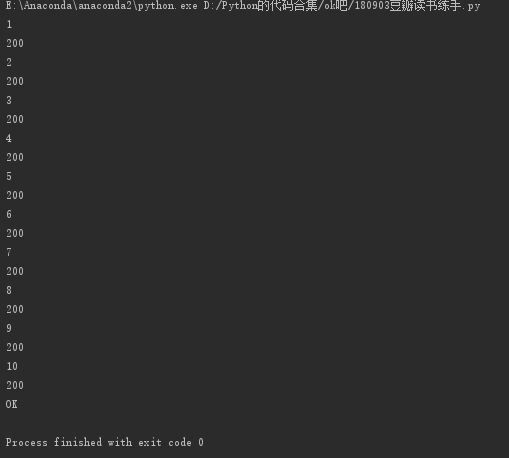
访问网页跳转正常,那么就是源代码输出到解析函数中发生了错误咯?
filename = '豆瓣图书排名top250.txt' # f = open(filename, 'w', encoding='utf-8') n = 0 resps = [] for url in all_page(): n = n+ 1 print(n) get_html(url) print(resps) # for response in resps # html_parse(resp) # f.close() print('OK')
输出的是。。。。!!!

搜嘎!!!我忘记加上text了

就是这一行!!!
再把文件的打开加上,终于可以惹!!不过我把第二个循环提到了外面方便大家理解哈哈哈
# -*- coding:UTF-8 -*- import requests from bs4 import BeautifulSoup def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } resp = requests.get(url, headers = headers).text resps.append(resp) # return resp def html_parse(response): # for url in all_page(): # get_html(url) # print(resp) soup = BeautifulSoup(response, 'lxml') alldiv = soup.find_all('div', class_='pl2') # print(alldiv) ''' for a in alldiv: names = a.find('a')['title'] print('find_all():',names) 可以简化为下面两条 ''' names = [a.find('a')['title'] for a in alldiv] # print(names) allp = soup.find_all('p', class_="pl") authors = [p.get_text()for p in allp] # print(authors) starspan = soup.find_all('span', class_="rating_nums") scores = [s.get_text() for s in starspan] # print(scores) sumspan = soup.find_all('span', class_="inq") sums = [i.get_text() for i in sumspan] # print(sums) for name, author, score, sum in zip(names,authors,scores,sums): name = '书名:'+ str(name)+ '\n' author = '作者:' + str(author) + '\n' score = '评分:' + str(score) + '\n' sum = '评价:' + str(sum) + '\n' data = name + author + score +sum f.writelines(data + '=========================='+'\n') def all_page(): base_url = 'https://book.douban.com/top250?start=' urllist = [] for page in range(0,250,25): allurl = base_url + str(page) urllist.append(allurl) return urllist filename = '豆瓣图书排名top250.txt' f = open(filename, 'w', encoding='utf-8') resps = [] for url in all_page(): get_html(url) print(resps) for response in resps: html_parse(response) f.close() print('OK')
结果如图:

我们再打开文件看一下

nice啊哈哈哈哈
补充,我在相关的一些爬取教程中看见说豆瓣有的时候书名和简介不服
这是因为有一些简介缺失了
所以可以补充以下代码:
sum_div = soup.select('tr.item>td:nth-of-type(2)') sums = [] for di in sum_div: sumspan = div.find('span',class_='inq') summary = sumspan.get_text() if sumspan else '无' sums.append(summary)
好了,今天就爬到这里了,你已经做的很好了,回来吧小虫虫!