0. 写作目的
好记性不如烂笔头。记录在学习过程中遇到的问题,以及对问题的思考和解决方法,为后来人提供一些经验。
1. 网络的重要性
虽然MNIST数据集相对比较简单,已经不能作为网络的评价标准,因为许多网络在MNIST数据上的精度都超过了99%,但是网络也不是随意选择的。刚开始随即设计了一个网络,用于测试MNIST数据集,收敛较慢,因此修改了网络的结构。
原始网络:
原始网络部分训练过程(由于训练时间有些长,就只训练了部分)

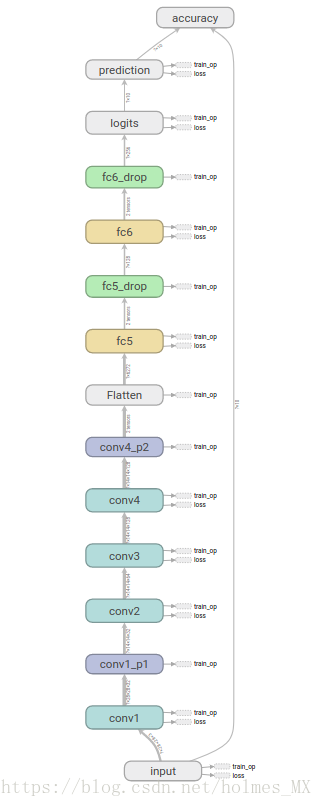
修改后的网络:

修改后的网络的训练过程显示:

2. Shuffle Batch 的探索
2.1 问题的来源
目前深度学习的框架,对于训练都有自己的一套完整流程。此处在验证如何读取较大数据时产生的一个问题,具体的读入数据方式可以参考我的博客——基于tensorflow的MNIST探索(基于图像版本的实现与探索)——如何读取较大数据集进行训练(一)。
2.2 问题的描述
在自己写的LoadDatas类中,存在一个public函数next_batch(self, batch_size=16)。在训练时,对于next_batch需要进行打乱,那么问题来了,如何进行打乱。博主认为有三种打乱的方式:
i) 对于每次的next_batch,将所有数据集打乱,然后取前batch_size个数据,然后抽取的样本放入总样本中,对应概率中的放回抽样
ii) 对于每次的next_batch,将所有数据集打乱,然后取前batch_size个数据,然后将抽取的样本不放入总样本中,对应概率中的不放回抽样
iii) 对于每次的next_batch,在每一个epoch时将顺序打乱,然后开始从头向后去batch_size个数据,即只打乱一次
2.3 针对问题进行的实验
网络架构选择修改后的网络(tf.train.MomentumOptimizer(learning_rate=0.001, momentum=0.9), batch_size=32)。
i)情况下的训练结果

ii) 情况下的训练结果

iii) 情况下的训练结果(由于时间关系,只训练了3个epoch)

2.4 实验的结果以及结论
从2.3中的训练结果图来看,采用i)情况,即有放回的batch_size结果比较好,而且iii)情况效果最差,原因可能是由于shuffle次数过少,导致数据的分布可能呈现一定的规律。当然也有可能实验不够充分,存在一定的随机性。
There may be some mistakes in this blog. So, any suggestions and comments are welcome!