- 第三种模型,即只要Master确认收到消息就算投递成功;实际使用时,根据应用特性选择,绝大多数情况下都会中和可靠性和性能选择第三种模型
Partition ack:当ack=1,表示producer写partition leader成功后,broker就返回成功,无论其他的partition follower是否写成功。当ack=2,表示producer写partition leader和其他一个follower成功的时候,broker就返回成功,无论其他的partition follower是否写成功。当ack=-1[parition的数量]的时候,表示只有producer全部写成功的时候,才算成功,kafka broker才返回成功信息。这里需要注意的是,如果ack=1的时候,一旦有个broker宕机导致partition的follower和leader切换,会导致丢数据。
如果备份replica下面两个指标不合格,则移除与其保持同步的备份列表,即不作为可靠备份,不作为优先候选者


上图是指producer在推送消息到broker时,确认推送成功的指标。
message状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
消息的消费状态是与consumer绑定的,因为消息可以被不同 consumer group的consumer消费,所以消费偏移量也是由consumer自己决定的
message持久化:Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的,这就是为了数据库的瓶颈经常在IO上,需要换SSD硬盘的原因。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。一般的机器,单机每秒100k条数据。
message有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的
同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。是指发送消息时,是会缓存一部分消息,然后批量将缓存的消息推送,可以减少网络IO的开销,从而提升吞吐。
分区机制partition:Producer可以决定把消息发到哪个partition,在一个partition 中message的顺序就是Producer发送消息的顺序,一个topic中可以有多个partition,具体partition的数量是可配置的。partition可以设置replica副本,replica副本存在不同的kafka broker节点上,第一个partition是leader,其他的是follower,message先写到partition leader上,再由partition leader push到parition follower上。所以说kafka可以水平扩展,也就是扩展partition。
解耦: 相当于一个MQ,使得Producer和Consumer之间异步的操作,系统之间解耦
顺序保证性:由于kafka的producer的写message与consumer去读message都是顺序的读写,保证了高效的性能。
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
- Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列
- Segment:partition物理上由多个segment组成,每个Segment存着message信息
- Producer : 生产message发送到topic
- Consumer : 订阅topic消费message, consumer作为一个线程来消费
- Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的consumer thread来处理。它不能像AMQ那样可以多个BET作为consumer去处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
Kafka动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader.ISR在ZooKeeper中维护。
。一个partition只能被一个消费者消费(一个消费者可以同时消费多个partition),因此,如果设置的partition的数量小于consumer的数量,就会有消费者消费不到数据。所以,推荐partition的数量一定要大于同时运行的consumer的数量。另外一方面,建议partition的数量大于集群broker的数量,这样leader partition就可以均匀的分布在各个broker中,最终使得集群负载均衡。
- 每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
- 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
这样做的好处就是能快速删除无用文件,有效提高磁盘利用率。
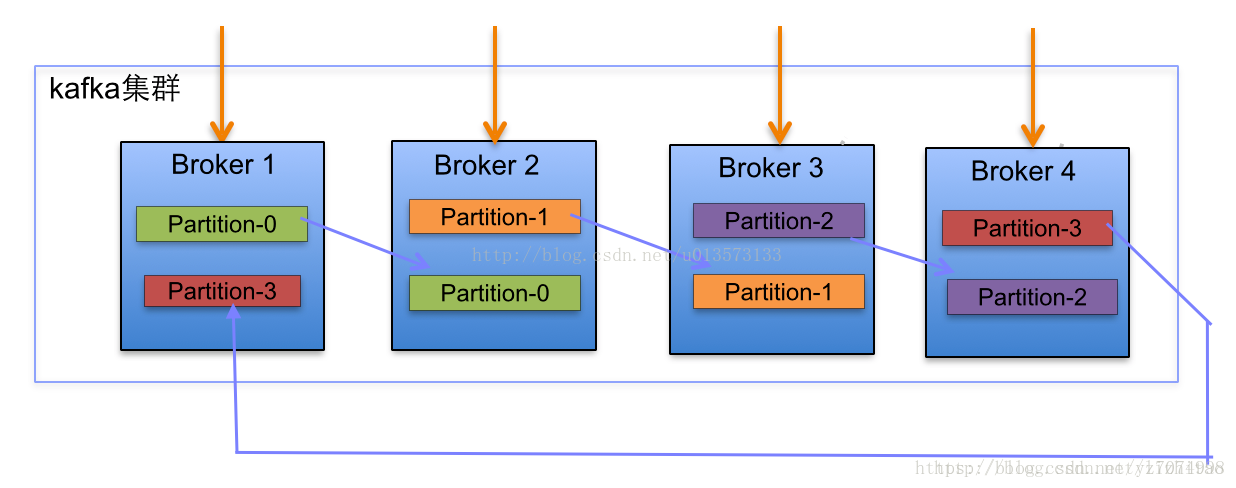
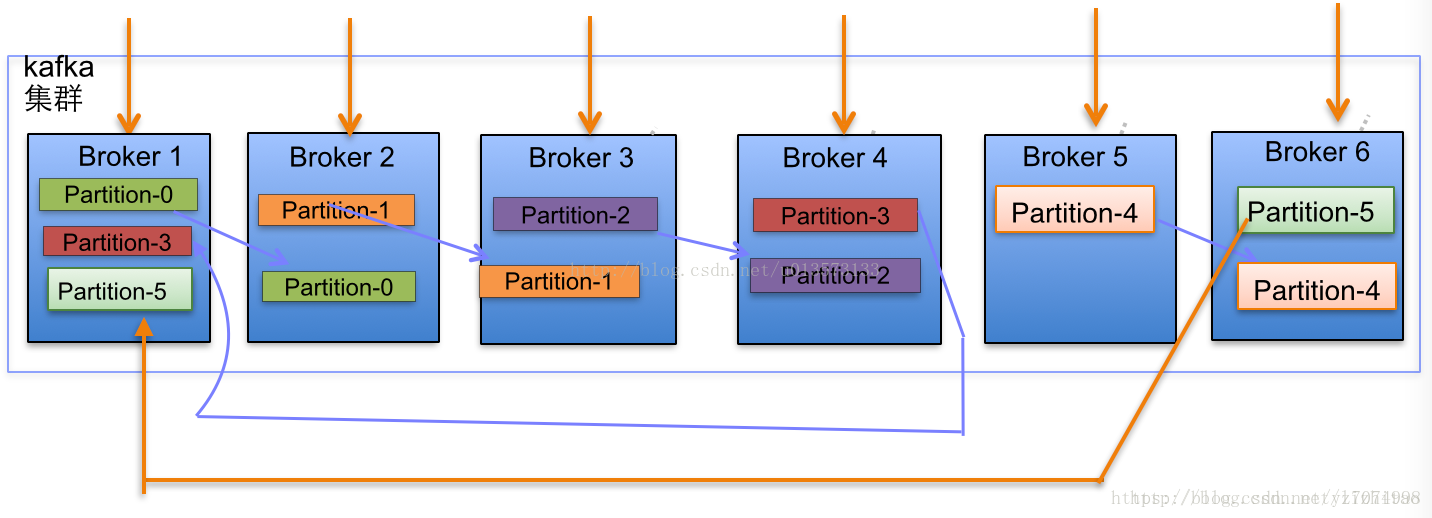
副本分配逻辑规则如下:
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
3. 维护消费关系及每个partition的消费信息。
6.2 Zookeeper上的细节:
1. 每个broker启动后会在zookeeper上注册一个临时的broker registry,包含broker的ip地址和端口号,所存储的topics和partitions信息。
2. 每个consumer启动后会在zookeeper上注册一个临时的consumer registry:包含consumer所属的consumer group以及订阅的topics。
3. 每个consumer group关联一个临时的owner registry和一个持久的offset registry。对于被订阅的每个partition包含一个owner registry,内容为订阅这个partition的consumer id;同时包含一个offset registry,内容为上一次订阅的offset。