1.DOM思想:
将整个XML加载到内存中 形成一颗(dom)树
将文档的各个组成部分 封装成为一些独立的对象 进行解析
所有对XML的操作都是在对内存中的文档对象进行操作
DOM 是官方的XML解析标准
所以DOM 是所有开发语言都支持的 java javascript 都支持
2.优缺点:
优点:因为在内存中会形成dom树 所以可以对dom树的节点进行增删改查
缺点:dom树非常占用内存 解析速度慢 容易内存溢出
3.基本的DOM对象:
Document 文档
Node 节点
NodeList 节点列表
Element 元素
Attr 属性
4.javax.xml.parsers 类 DocumentBuilderFactory
从 XML 文档获取生成 DOM 对象树的解析器。
常用方法:
获取DocumentBuilderFactory对象:
static DocumentBuilderFactory newInstance()
获取 DocumentBuilderFactory 的新实例。
获取DocumentBuilder解析器:
abstract DocumentBuilder newDocumentBuilder()
使用当前配置的参数创建一个新的 DocumentBuilder 实例
5.javax.xml.parsers 类 DocumentBuilder
常用方法:
Document parse(String uri)
将给定 URI 的内容解析为一个 XML 文档,并且返回一个新的 DOM
Document 对象。
6.org.w3c.dom 接口 Document
本类:
Element getElementById(String elementId)
返回具有带给定值的 ID 属性的 Element。
NodeList getElementsByTagName(String tagname)
按文档顺序返回包含在文档中且具有给定标记名称的所有 Element 的
NodeList。
NodeList getElementsByTagNameNS(String namespaceURI, String
localName) 以文档顺序返回具有给定本地名称和名称空间 URI 的所有 Elements 的 NodeList。
继承父类(Node)的:
Node appendChild(Node newChild)为这个节点 添加一个子节点 并且是放在所有子节点的最后 如果这个子节点已经存在 先删除 再添加
Node getFirstChild()此节点的第一个子节点。
String getNodeName()此节点的名称,取决于其类型;。
String getNodeValue()此节点的值,取决于其类型;
Attr createAttribute(String name)创建给定名称的 Attr。
Element createElement(String tagName)创建指定类型的元素。
Text createTextNode(String data)创建给定指定字符串的 Text 节点。
Node removeChild(Node oldChild)从子节点列表中移除 oldChild 所指示的子节点,并将其返回。
Node replaceChild(Node newChild, Node oldChild)将子节点列表中的子节点 oldChild 替换为 newChild,并返回 oldChild 节点。
其他:
item(int) 返回指定位置的Node对象
getLength() 返回列表长度
7.Node 和 Element 的区别
XML文档中 每个成分都是一个节点Node
Node 对象 是整个DOM的主要数据类型
代表文档树中的一个个单独节点
Element 对象 表示XML文档中的元素
简单来说 就是 Node 是一个基类
DOM中的 Element, Attr ,Text 和 Comment 都属于 Node
他们分别叫做 ELEMENT_NODE , TEXT_NODE 和 COMMENT_NODE
Element 一个元素必须包含完整的信息
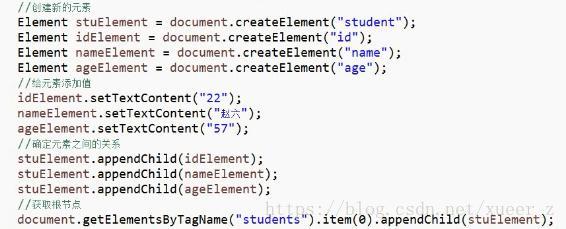
8.步骤:
(1)创建DocumentBuilderFactory工厂
(2)获得解析器DocumentBuilder
(3)调用parse方法获得Document对象
(4)获取元素
(5)根据元素获取节点集合
(6)创建集合
(7)添加数据
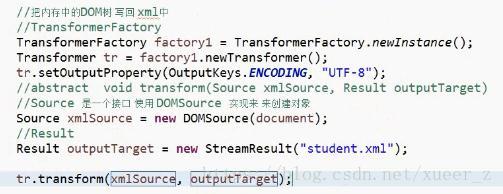
9.javax.xml.transform 类 TransformerFactory
static TransformerFactory newInstance()
获取 TransformerFactory 的新实例。
abstract Transformer newTransformer()
创建执行从 Source 到 Result 的复制的新 Transformer。
abstract void setOutputProperties(Properties oformat)
设置转换的输出属性。
abstract void transform(Source xmlSource, Result outputTarget)将 XML Source 转换为 Result
DOMSource(Node n)创建带有 DOM 节点的新输入源。
StreamResult(String systemId)从 URL 构造 StreamResult。
10. SAX 和 DOM 区别:
1.
SAX适用于解析比较复杂的XML文件
SAX 基于事件的 当某个事件被触发时 才会获取相应的XML部分数据
不管文件有多大 都只占用了少量内存空间
DOM适用于解析比较简单的XML文件
如果文件过大 会造成内存溢出
DOM 基于内存的 不管文件有多大 都会将所有内容预先装载到内存中
消耗大量的内存空间
2.
SAX只能读 不能再文件中插入数据
DOM可以读取文件 也可以向文件中插入数据
3.
SAX不可以对指定的元素进行随机访问
SAX是从文档开始执行遍历
并且只能遍历一次
不能随机访问XML文件 只能从头读到尾 当然可以中间截断
DOM可以对指定的元素进行随机访问
详细请参考:
链接:https://pan.baidu.com/s/138o9WZre-OP-VTtcfRAILQ 密码:umk6