0. 介绍
Ceph是一个开源的分布式文件系统。因为它还支持块存储、对象存储,所以很自然的被用做云计算框架openstack或cloudstack整个存储后端。当然也可以单独作为存储,例如部署一套集群作为对象存储、SAN存储、NAS存储等。国内外很多公司实践证明,ceph块存储和对象存储是完成可靠的。本文希望通过自己的理解,通俗地想大家分析ceph的整个架构。
1. 架构总揽

1.1支持接口
对象存储:即radosgw,兼容S3接口。通过rest api上传、下载文件。
文件系统:posix接口。可以将ceph集群看做一个共享文件系统挂载到本地。
块存储:即rbd。有kernel rbd和librbd两种使用方式。支持快照、克隆。相当于一块硬盘挂到本地,用法和用途和硬盘一样。
1.2 优点
分布式文件系统很多,ceph相比其他的优点:
1.2.1 统一存储
虽然ceph底层是一个分布式文件系统,但由于在上层开发了支持对象和块的接口。所以在开源存储软件中,能够一统江湖。至于能不能千秋万代,就不知了。
1.2.2 高扩展性
说人话就是扩容方便、容量大。能够管理上千台服务器、EB级的容量。
1.2.3 可靠性强
支持多份强一致性副本,EC。副本能够垮主机、机架、机房、数据中心存放。所以安全可靠。存储节点可以自管理、自动修复。无单点故障,容错性强。
1.2.4 高性能
因为是多个副本,因此在读写操作时候能够做到高度并行化。理论上,节点越多,整个集群的IOPS和吞吐量越高。另外一点ceph客户端读写数据直接与存储设备(osd) 交互。在块存储和对象存储中无需元数据服务器。
注:上面的都是ceph呈现的设计理念优势,由于ceph各个版本都存在bug,具体应用得经过大规模测试验证。推荐版本:0.67.0、0.80.7、0、94.2
1.3 Rados集群
Rados集群是ceph的存储核心。下面先简单介绍各个组件的作用。后续会讲解各个组件之间如何协作。
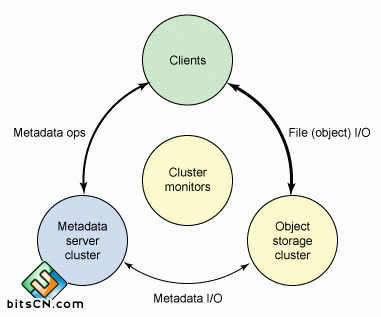
如图,rados集群中分为以下角色:mdss、osds、mons. Osd 对象存储设备,可以理解为一块硬盘+osd 管理进程,负责接受客户端的读写、osd间数据检验(srub)、数据恢复(recovery)、心跳检测等。Mons 主要解决分布式系统的状态一致性问题,维护集群内节点关系图(mon-map osd-map mds-map pg-map)的一致性,包括osd的添加、删除的状态更新。Mds元数据服务器,在文件存储时是必须配置。需要注意的是,mds服务器并不存放数据,仅仅只是管理元数据的进程。Ceph文件系统的inode等元数据真正存在rados集群(默认在metadata pool)。以下信息,呈现的是ceph集群中状态信息。
# ceph -s
cluster 72d3c6b5-ea26-4af5-9a6f-7811befc6522
health HEALTH_WARN
clock skew detected on mon.mon1, mon.mon3
monmap e3: 3 mons at {mon1=10.25.25.236:6789/0,mon2=10.25.25.235:6789/0,mon3=10.25.25.238:6789/0}
election epoch 16, quorum 0,1,2 mon2,mon1,mon3
osdmap e330: 44 osds: 44 up, 44 in
pgmap v124351: 1024 pgs, 1 pools, 2432 GB data, 611 kobjects
6543 GB used, 153 TB / 160 TB avail
1024 active+clean
2. 什么是对象存储
我的理解从几方面来阐述:
一是:从存储数据类型来讲,指非结构化数据,如图片、音视频、文档等。
二是:从应用场景来说,即一次写人多次读取。
三是:从使用方式,与文件posix不同,对象存储一般使用bucket(桶)概念,给你一个桶,你变可以向桶里存储数据(通过对象id)。

3. 什么是块存储
块存储的典型设备是磁盘或磁盘阵列。以块形式的方式存取数据的。单盘的iops和吞吐很低,所以自然想到用raid来并行的读写。Ceph的块存储当然也是解决此类问题,不过利用分布式提供更高的性能,可靠和扩展性。只不过ceph是一种网络块设备,如同SAN。下图就是ceph 将分布在不同主机磁盘“虚拟”后,提供给VM做磁盘。

4. Ceph 组件交互
乱扯淡:其实在IT领域,一直是分分合合的状态。分久必合,合久必分。例如,单台计算机由cpu,内存,输入输出设备,总线等组件协同工作。当单机计算,存储能力不足时候,就开始分化成分布式架构。网络就相当于总线,网络设备就是路由中心、数据中转站,对外提供更强计算、存储能力的计算机。物理(逻辑)分开的主机协同工作,则需要主要解决下列的问题:
连:如何将独立的单元连起来。
找:连起来的目的当然不是为了繁殖,而是通信。首先得找到它。
发:找到主机后,得发数据交互才能产生价值,繁衍数据吧。
接下来看ceph如何解决这些问题的。
4.1 rados -连连看
前面介绍了rados集群中各个角色的分工。通过一张逻辑部署图将各个组件联系起来。

4.2 crush-我要找到你
Client 读写数据,则需要找到数据应该存放的节点位置。一般做法将这种映射关系记录(hdfs)或者靠算法计算(一致性hash)。Ceph采用的是更聪明的crush算法,解决文件到osd的映射。先看看ceph中管理数据(对象)的关系。首先ceph中的对象被池(pool)化,pool中有若干个pg,pg是管理一堆对象的逻辑单位。一个pg分布在不同的osd上。如图client端的文件会被拆分个object,这些对象以pg的单位分布。
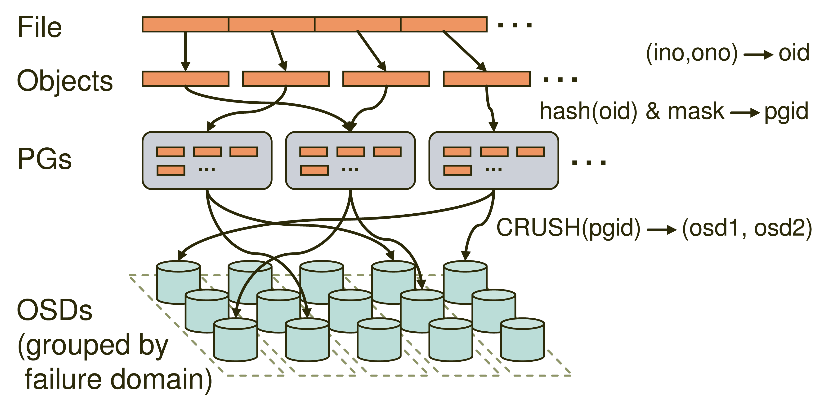
Crush算法的输入为(pool obj),即ceph的命名空间
-
计算pg号,通过obj mod 当前pool中的pg总数
-
Crush(pg,crushmap) 计算出多个osd。crush算法是一个多输入的伪随机算法, Crushmap主要是整个集群osd的层次结果、权重信息、副本策略信息。
后面我会介绍crush算法内部实现细节。
4.3 ceph rw-数据交互
Rados集群中节点相互的通信。主要包括下面几个方面:
客户端读写
主要接收客户端上传、下载、更新、删除操作。为了保持数据强一致性,写操作必须几个副本写成功后才算一次写操作完成。(客户端只会向primary写)

集群内部读写
包括osd间数据同步,数据校验、心跳检查。Mon与osd间心跳检查,mon间状态同步等。