ceph概述
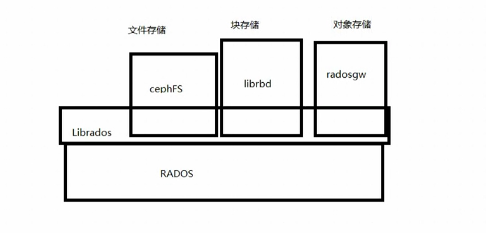
ceph本质是一种rados:可靠的、主动的、分布式对象存储。
ceph提供libados库供客户端访问存储,客户端访问ceph提供的文件系统则通过cephFS调用librados访问进而访问ceph后端存储;客户端访问ceph提供的块存储则通过librbd调用librados访问进而访问ceph后端存储;客户端访问ceph提供的对象存储则通过radosgw调用librados访问进而访问ceph后端存储。
注意:cephFS、librbd、radosgw是客户端的库。
虚拟机挂载ceph后端存储的过程
nova调用虚拟机控制程序libvirtd,libvirtd调用kvm驱动和qemu驱动创建出虚拟机(kvm虚拟cpu和内存,qemu虚拟其它的IO设备)。
块存储是挂载给虚拟机使用,块存储通过cinder调用ceph的存储驱动从而创建出硬盘。
虚拟机通过qemu创建,对虚拟机的所有操作都要通过qemu,创建的云硬盘要想挂载给虚拟机则需要通过qemu调用librbd驱动,而librbd调用ceph存储后端的librados库链接至ceph的mon集群上,获取mon集群的cluster map。客户端获取到cluster map后,就能够掌握整个集群状态。

ceph架构

ceph集群架构
disk集群:实际的物理硬盘,负责存储数据。在设计过程中,可以将一块硬盘进行分区,一个分区当成一块硬盘来使用;也可以将多块硬盘做raid,raid盘当作一块硬盘来使用。使用单独的硬盘效率最高;
osd daemon集群:硬盘是独立的,无法进行通信,所以在硬盘之上添加一个软件即osd daemon,可以实现硬盘之间基于某种协议的通信;
功能:1.数据的存储和复制;2.向mon汇报自己监控的disk状态以及组内其它osd daemon的状态,osd daemon默认每2s向mon汇报自身的状态,一旦2s内未汇报,mon就会将osd daemon状态标记为stable,过了300s还未汇报的话就会将它踢出集群,将会通过crush算法从其它的osd中找一个osd填充该位置。
monitor daemon集群:负责监控ceph集群状态,monitor daemon节点通常是奇数个。mon通过paxos(分布式强一致性算法)算法选举出一个leader,其余两个是provider。
可以存在多个mon节点,多个mon节点通过共同计算出一个映射关系即cluster map,cluster map反映了三类集群的状态。provider周期性向leder同步cluster map信息,通过epoach(版本号)的方式,保证了mon节点之间cluster map的一致性(通过paxos算法保持一致性)。维护一个cluster map(集群视图)来监控集群状态。
paxos算法的功能:1.选举;2.保证mon节点之间cluster map的一致性。
cluster map包含:
1.mon map:监控mon自身的状态;
2.osd map:监控osd daemon的状态;
3.pg map:pg是一个逻辑概念,一个pg后端对应多个osd daemon;
4.crush map:保存pg到osd的映射关系。
ceph中的对应关系:
object和pg是一对一的关系;
pg和object是多对多的关系;
pg和osd daemon是多对多的关系;
osd daemon和pg是多对多的关系;
osd daemon和disk是一对一的关系。
ceph网络架构
集群网路(万兆网络):也称为北向网络
1.负责连接ceph集群mon、osd daemon、disk,使大家一起协同工作;
2.mon集群之间的通信;
3.向mon汇报自己监控的disk状态以及组内其它osd daemon的状态;
4.负责连接客户端使得客户端能够访问osd存储,客户端能够获取cluster map。
复制网路(万兆网络):也称为东西网络
-1.osd节点之间进行数据复制;
2.监控。
ceph和lvm的对比
lvm中的pv类似于ceph中的osd daemon,lvm中的vg类似于ceph中存储池(pool)的概念,池是多个pg的集合。
客户端要想使用ceph的存储空间,首先要先通过ceph客户端命令创建一个存储池(ceph osd pool create volumes 128(指定该存储池中包含pg数)),存储池的功能就是为客户端提供块存储。当要划分块设备给客户端时,实际上就是在存储池中划分出一块空间,该空间称为image,image可以对应多个pg。注意:image是一个磁盘配额,并不是实际的空间大小,如为客户端创建100G的块设备,对应的image配额就为100G,这样的好处是可以实现在线动态扩容,只要修改配额就可以简单实现在线动态扩容。
客户端存储文件过程
云硬盘挂载至虚拟机的一个目录下,虚拟机向该目录的读写操作将会发给qemu,qemu将文件发给librbd,librbd会将文件进行切分成多个二进制(默认是4MB),一个二进制就称为object(object即ceph最小的存储单位)。客户端通过pool id和object id计算出一个pg(对object id做hash运算,而后与所有的pg数取模,而后再与pool id做hash得到一个值,这个值就是具体要存储的pg);接下来就是通过crush map查找pg对应的osds,然后先将数据存储至pg中的组长osd daemon下的disk,而后由组长osd daemon负责数据的复制操作。
注意:ceph存储小文件的效率并不高,ceph的性能会随着osd数目的增加理论上会无限增加。