版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37855575/article/details/82288011
本文是根据stackoverflow上一个问题进行的复盘,若涉及任何侵权,请联系我修改或删除。
stackoverflow原文链接 -->
https://stackoverflow.com/questions/32459325/python-pandas-dataframe-select-row-by-max-value-in-group
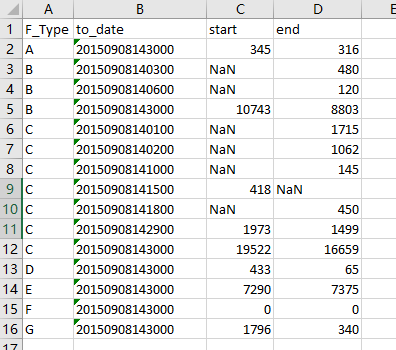
我将上面的数据直接复制粘贴到excel中,分列及填充F_Type列后,保存为csv格式。
接下来,用pandas.read_csv导入到python中,
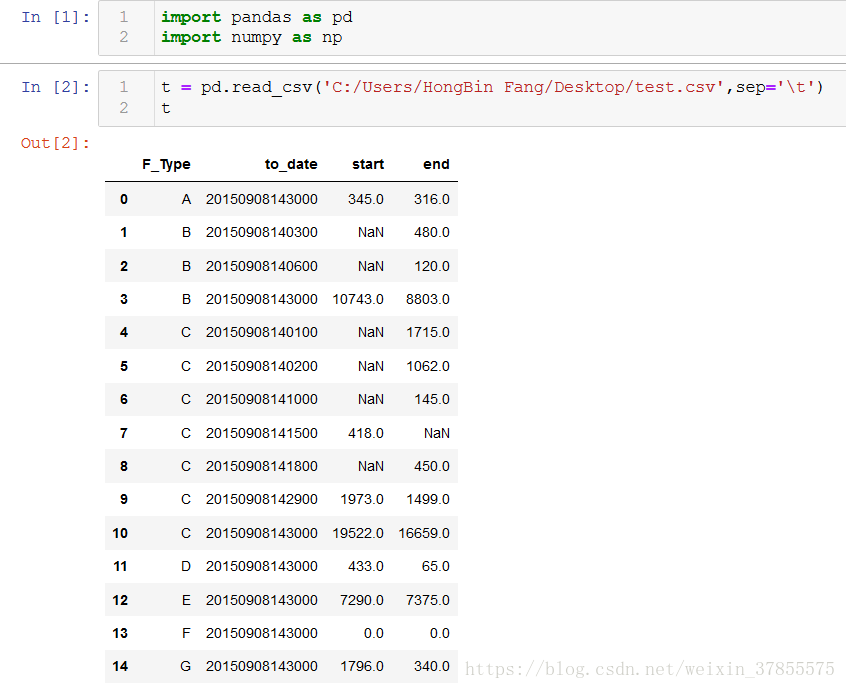
重新设置索引就可以显示出与原问题相同的结构
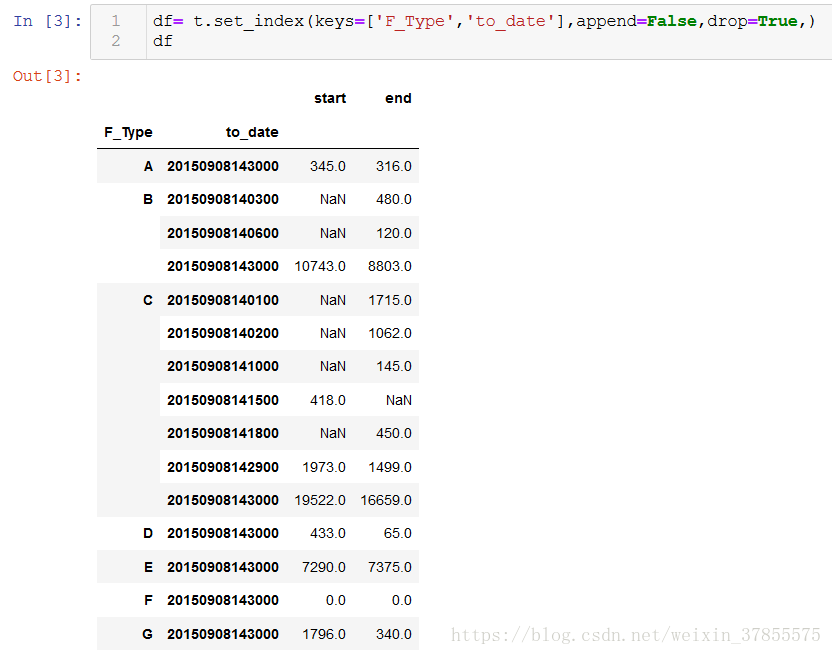
接下来,问题中的要求是按ABCD中去分组,然后取出每一分组的to_date最大的一条数据
先对df重设索引,这样就可以把F_Type变成column类,再以这个column分组

用group_name.groups,可以查看每一分组的信息,这里课可以看到每一分组包含的数据的索引位置信息
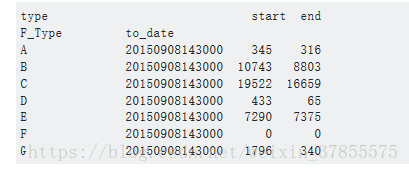
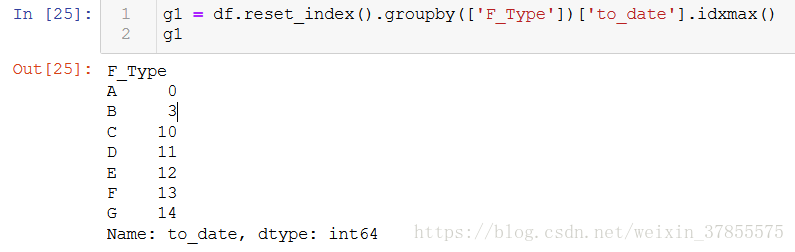
接下来,指定各个groups中某一列。并idxmax()提取该列里面的最大值的索引
这里的出来的g1,是一个series,索引是各类,值是原数据的索引
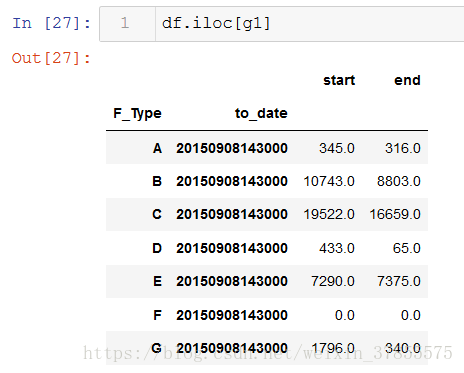
各最大值索引的位置出来了,我们就可以用iloc选取原数组中对应的行数据,iloc是根据索引的位置来选取数据行
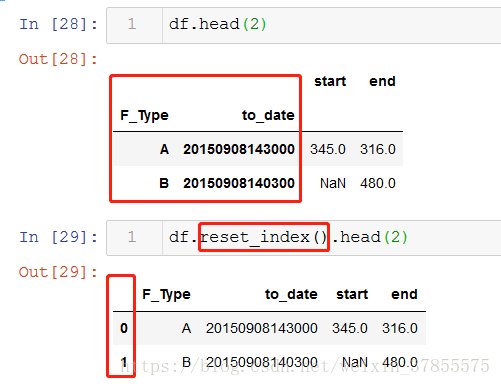
如果要用loc,loc是根据索引的值来选取数据行
那么我们就要对数组reset_index,这样一来,index就是重设为从0开始,新index无论是值还是位置,都是从0开始,便可以根据索引值选取数据行
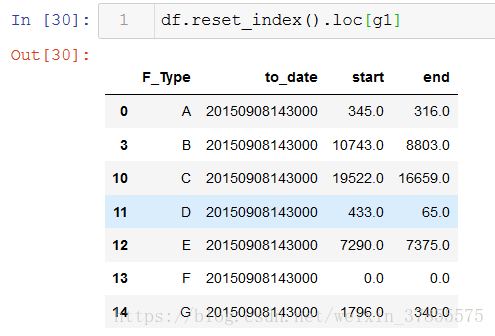
用loc选取后的数组如下
原链接中解决问题的答案现在已经无法给出结果,resolver用的是loc+idxmax(), 可能pandas已经无法用loc去同时匹配一个作为条件的sereis的索引和值。

--- End ---