原题链接:https://leetcode-cn.com/problems/binary-tree-postorder-traversal/description/
题目描述:

知识点:二叉树、后序遍历、递归
思路一:递归实现
学过数据结构的人都知道,二叉树天然的具有递归性质,因为二叉树的定义就是用递归的形式定义的。因此,在后序遍历二叉树的时候我们完全可以采用递归算法。
所谓后序遍历,就是先去访问该节点的左孩子,再访问该节点的右孩子和该节点。
由于要遍历每一个节点,这样实现的时间复杂度是O(n)级别的,其中n为二叉树中的节点个数。而对于空间复杂度,由于递归存在对系统栈的调用,而这里递归层数就是树的高度,因此空间复杂度是O(h)级别的,其中h为树的高度。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
postorderTraversal(root, list);
return list;
}
private void postorderTraversal(TreeNode treeNode, List<Integer> list) {
if(treeNode == null) {
return;
}
postorderTraversal(treeNode.left, list);
postorderTraversal(treeNode.right, list);
list.add(treeNode.val);
}
}LeetCode解题报告:

思路二:模拟系统栈的递归过程
在我们思路一的实现中,我们利用递归的性质实现了二叉树的后序遍历,其实本质上是利用了系统栈后进先出的性质。

那么如果我们自己创建一个栈来模拟系统栈的全过程呢?那么我们也就不需要用到递归这个方法,我们完全可以用非递归的形式来实现我们的思路。注意这里入栈的顺序应该是先记录当前节点的值,再访问当前节点的右孩子,最后访问其左孩子。
其实这个思路和思路一本质上是一模一样的,只不过思路一中使用的是系统栈,而思路二中使用的是我们自定义的栈。因此时间复杂度为O(n),其中n为二叉树中的节点个数。空间复杂度为O(h),其中h为树的高度。
JAVA代码:
public class Solution {
private class Command {
String s;
TreeNode treeNode;
public Command(String s, TreeNode treeNode) {
this.s = s;
this.treeNode = treeNode;
}
}
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<Command> stack = new Stack<>();
stack.push(new Command("go", root));
while(!stack.isEmpty()) {
Command command = stack.pop();
if("visit".equals(command.s)) {
list.add(command.treeNode.val);
}
if("go".equals(command.s) && command.treeNode != null) {
stack.push(new Command("visit", command.treeNode));
stack.push(new Command("go", command.treeNode.right));
stack.push(new Command("go", command.treeNode.left));
}
}
return list;
}
}LeetCode解题报告:

思路三:模拟手工计算后序遍历的过程,用栈来记录之前遍历过的节点
但是后序遍历和前序遍历和中序遍历都不同。前序遍历是在入栈的时候就记录该节点的值。入栈代表我们对该节点的第一次访问。而中序遍历是在出栈的时候记录该节点的值。出栈代表我们对该节点的第二次访问。而后序遍历的实质是:在第三次访问该节点的时候才记录该节点的值。那么,我们如何来判断我们是第三次访问该节点呢?我们自定义一个一个内部类TagNode用以记录该节点是否已经被访问过。如果出栈的时候该节点的标记是没有被访问过,我们改变这个标记为访问过,将该出栈的原节点入栈。如果出栈的时候该节点的标记是被访问过,我们记录该节点的值即可。
在整个过程中,和前序遍历和中序遍历一样,我们需要一个cur指针来带领我们遍历整棵树。而且入栈的操作都是一样的,只不过在出栈的时候我们做了一些特殊处理而已。
由于此思路的实现中对于每一个节点都存在着入栈-出栈-入栈-出栈这么几个过程,因此其时间复杂度虽然也是O(n)级别的,其中n为树中的节点个数,但事实上的时间消耗是前序遍历和中序遍历的2倍。对于空间复杂度而言,和前序遍历和中序遍历一样,都是O(h)级别的,其中h为二叉树的高度。
JAVA代码:
public class Solution {
private class TagNode {
TreeNode treeNode;
boolean visited;
public TagNode(TreeNode treeNode) {
this.treeNode = treeNode;
this.visited = false;
}
}
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TagNode> stack = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack.isEmpty()) {
while(cur != null) {
stack.push(new TagNode(cur));
cur = cur.left;
}
TagNode tagNode = stack.pop();
cur = tagNode.treeNode;
if(tagNode.visited) {
list.add(tagNode.treeNode.val);
cur = null;
}else {
tagNode.visited = true;
stack.push(tagNode);
cur = cur.right;
}
}
return list;
}
}
LeetCode解题报告:

思路四:用两个栈来实现后序遍历
前序遍历:先记录自身的值,再记录左孩子的值,最后记录右孩子的值。
后序遍历:先记录左孩子的值,再记录右孩子的值,最后记录自身的值。
我们将“记录自身的值”这个过程看作是过程一,将“记录左孩子的值”看作是过程二,“记录右孩子的值”这个过程看作是过程三。那么前序遍历就是先过程一,再过程二,最后过程三。而后序遍历就是先过程二,再过程三,最后过程一。因此,我们发现后序遍历,从另一个角度看,是前序遍历的逆过程。我们只需要将前序遍历思路三的入栈顺序改成先入栈右孩子,再入栈左孩子。那么我们就将前序遍历变为了:过程一、过程三、过程二。再在此基础上,我们完全可以再用一个栈来颠倒结果,就得到的后序遍历的过程:过程二、过程三、过程一。
对于每一个节点都要出入两个栈,相当于思路三中的每一个节点出入同一个栈两次,因此该思路的时间复杂度与思路三相同,是O(n)级别的,其中n为树中的节点个数。而空间复杂度,用了两个栈,而且对于第二个栈而言,需要存满树中的所有节点,因此比思路三要用的空间多,其空间复杂度是O(n)级别的。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack1 = new Stack<>();
Stack<Integer> stack2 = new Stack<>();
stack1.push(root);
while(!stack1.isEmpty()) {
TreeNode treeNode = stack1.pop();
stack2.push(treeNode.val);
if(treeNode.left != null) {
stack1.push(treeNode.left);
}
if(treeNode.right != null) {
stack1.push(treeNode.right);
}
}
while(!stack2.isEmpty()) {
list.add(stack2.pop());
}
return list;
}
}LeetCode解题报告:

思路五:模拟手工计算前序遍历的过程,再用第二个栈来翻转结果
思路四中对于前序遍历的翻转实现是将前序遍历思路三的入栈顺序改成先入栈右孩子,再入栈左孩子。那么我们同样可以利用前序遍历思路四来翻转实现后序遍历的过程。
时间复杂度和空间复杂度均与思路四相同。对于每一个节点都要出入两个栈,相当于思路三中的每一个节点出入同一个栈两次,因此该思路的时间复杂度与思路三相同,是O(n)级别的,其中n为树中的节点个数。而空间复杂度,用了两个栈,而且对于第二个栈而言,需要存满树中的所有节点,因此比思路三要用的空间多,其空间复杂度是O(n)级别的。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack1 = new Stack<>();
Stack<Integer> stack2 = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack1.isEmpty()) {
while(cur != null) {
stack1.push(cur);
stack2.push(cur.val);
cur = cur.right;
}
cur = stack1.pop();
cur = cur.left;
}
while(!stack2.isEmpty()) {
list.add(stack2.pop());
}
return list;
}
}LeetCode解题报告:

思路六:用一个指针pre来记录前一个被记录值的节点
入栈的思路和前序遍历思路三相同,不过在出栈的时候我们要判断是否记录该节点的值,如果不记录该节点的值,我们要将该节点重新入栈。我们如何来判断是否要记录该节点的值呢?
我们要设置一个pre指针来指向前一个被记录值的节点。如果当前出栈节点的左孩子和右孩子均为空,或者pre不为空且pre为当前出栈节点的左孩子且当前出栈节点的右孩子为空,或者pre不为空且pre为当前出栈节点的右孩子,我们则记录该节点的值,并更新pre的值。
由于此思路的实现中对于除叶子节点外的每一个节点都存在着入栈-出栈-入栈-出栈这么几个过程,因此其时间复杂度虽然也是O(n)级别的,其中n为树中的节点个数,但事实上的时间消耗比前序遍历和中序遍历要大。对于空间复杂度而言,和前序遍历和中序遍历一样,都是O(h)级别的,其中h为二叉树的高度。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
TreeNode pre = null;
while(!stack.isEmpty()) {
TreeNode treeNode = stack.pop();
if((treeNode.left == null && treeNode.right ==null) || (pre != null && pre == treeNode.left && treeNode.right == null) || (pre != null && pre == treeNode.right)) {
list.add(treeNode.val);
pre = treeNode;
}else {
stack.push(treeNode);
if(treeNode.right != null) {
stack.push(treeNode.right);
}
if(treeNode.left != null) {
stack.push(treeNode.left);
}
}
}
return list;
}
}LeetCode解题报告:

思路七:模拟手工计算前序遍历的过程,用一个指针pre来记录前一个被记录值的节点
入栈的思路和前序遍历思路四相同,不过在出栈的时候我们要判断是否记录该节点的值,如果不记录该节点的值,我们要将该节点重新入栈。我们如何来判断是否要记录该节点的值呢?
这个判断和思路六的判断同理,但是不尽相同。我们要设置一个pre指针来指向前一个被记录值的节点。如果当前出栈节点没有右孩子或者pre为当前出栈节点的右孩子,我们则记录该节点的值,并更新pre的值。
为什么这里的判断和思路六中的判断不一样?为什么这里不用判断当前出栈节点是否有左孩子了呢?
在判断之前我们有一个入栈的循环过程,该循环过程就是一直往左走入栈的。所以对于出栈的元素,其左孩子要么为空,要么其左孩子已经被记录过了。
此思路的实现中对于除不存在右孩子节点外的每一个节点都存在着入栈-出栈-入栈-出栈这么几个过程,因此其时间复杂度虽然也是O(n)级别的,其中n为树中的节点个数,但事实上的时间消耗比前序遍历和中序遍历要大。对于空间复杂度而言,和前序遍历和中序遍历一样,都是O(h)级别的,其中h为二叉树的高度。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode pre = null;
TreeNode cur = root;
while(cur != null || !stack.isEmpty()) {
while(cur != null) {
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
if(cur.right == null || pre == cur.right) {
list.add(cur.val);
pre = cur;
cur = null;
}else {
stack.push(cur);
cur = cur.right;
}
}
return list;
}
}LeetCode解题报告:

思路八:思路七的另一种实现形式
把思路七的while循环用一个if-else语句来代替。
实现思路和思路七是一模一样的,自然时间复杂度和空间复杂度和思路七也是一样的。时间复杂度为O(n),其中n为二叉树中的节点个数。空间复杂度为O(h),其中h为树的高度。
JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode pre = null;
TreeNode cur = root;
while(cur != null || !stack.isEmpty()) {
if(cur != null) {
stack.push(cur);
cur = cur.left;
}else {
cur = stack.pop();
if(cur.right == null || pre == cur.right) {
list.add(cur.val);
pre = cur;
cur = null;
}else {
stack.push(cur);
cur = cur.right;
}
}
}
return list;
}
}LeetCode解题报告:

思路九:Morris遍历
Morris后序遍历的实现比Morris前序遍历和Morris中序遍历的实现要复杂得多。需要建立一个虚拟根节点dumpRoot,令其左孩子是root。并且还需要一个子过程,就是倒序输出某两个节点之间路径上的各个节点。
步骤如下:
当前节点设置为虚拟根节点dumpRoot。
(1)如果当前节点的左孩子为空,则将其右孩子作为当前节点。
(2)如果当前节点的左孩子不为空,在当前节点的左子树中找到当前节点在中序遍历下的前驱节点。
a.如果前驱节点的右孩子为空,将它的右孩子设置为当前节点。当前节点更新为当前节点的左孩子。
b.如果前驱节点的右孩子为当前节点,将它的右孩子重新设为空。倒序记录从当前节点的左孩子到该前驱节点这条路径上的所有节点。当前节点更新为当前节点的右孩子。
(3)重复以上(1)、(2)直到当前节点为空。
Morris后序遍历的时间复杂度虽然比前面的思路一~思路八稍慢,但仍然是O(n)级别的,其中n为二叉树的节点数。但是空间复杂度获得了极大的提高,是O(1)级别的。关于Morris遍历时间换空间的思想,参见我的另一篇博文:https://blog.csdn.net/qq_41231926/article/details/82047811。虽然这篇博文分析的是Morris前序遍历,但其实Morris后序遍历同理。
以一个小例子来模拟Morris后序遍历的全过程,该例子如下:
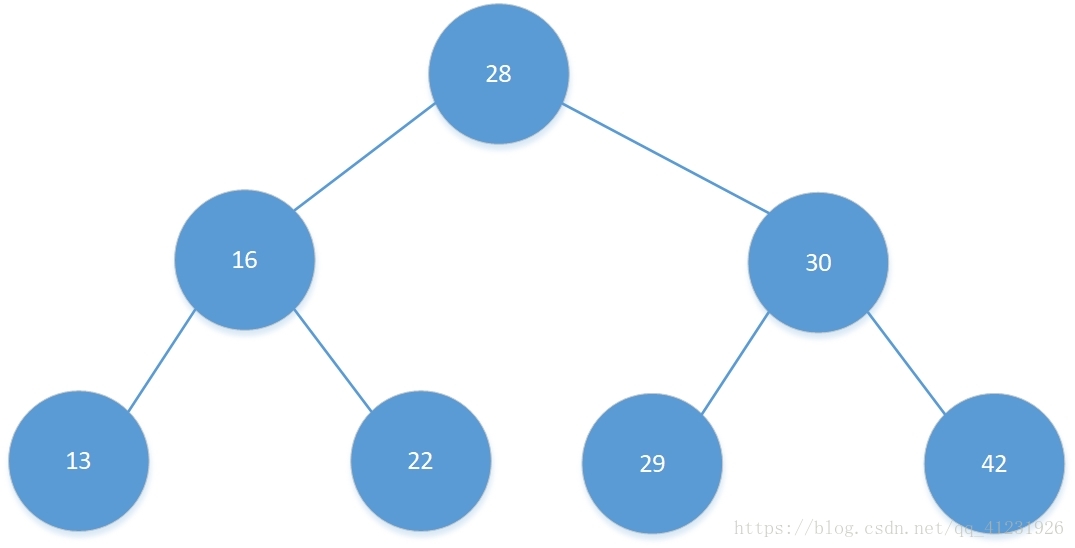
Morris后序遍历过程如下:

JAVA代码:
public class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<>();
if(root == null) {
return list;
}
TreeNode dummyRoot = new TreeNode(-1);
dummyRoot.left = root;
TreeNode cur = dummyRoot;
while(cur != null) {
if(cur.left == null) {
cur = cur.right;
}else {
TreeNode pre = cur.left;
while(pre.right != null && pre.right != cur) {
pre = pre.right;
}
if(pre.right == null) {
pre.right = cur;
cur = cur.left;
}else {
pre.right = null;
reverseOrder(cur.left, list);
cur = cur.right;
}
}
}
return list;
}
private void reverseOrder(TreeNode treeNode, List<Integer> list) {
int i = list.size();
while(treeNode != null) {
list.add(treeNode.val);
treeNode = treeNode.right;
}
int j = list.size() - 1;
while(i < j) {
Integer temp = list.get(i);
list.set(i, list.get(j));
list.set(j, temp);
i++;
j--;
}
}
}
LeetCode解题报告:
