结构体是一种复合类型,其中包括很多的数据类型。
例如:
struct Stu//Stu是结构体标签,可省略
{
char name[20];
int age;
char sex[5];
char id[20];
};//分号不能省结构体成员
结构体成员可以是标量、数组、指针,甚至是其他结构体。
结构体成员的访问
1,用 结构体名称 x . +x成员名称,比如 :stu.name。
2,用 结构体指针 x -> x 成员名称,比如 :p->name。
结构体的自引用
错误示范:
struct Node
{
int data;
struct Node next;
};这样会无法确定结构体的大小。
正确的自引用方式应用指针
struct Node
{
int data;
struct Node* next;
};注意:
typedef struct
{
int data;
Node*nest;
}Node;这样写是不行的,后定义,先引用。
正确的方式:
sypedef struct Node
{
int datea;
struct Node* next;
}Node;结构体的不完整声明
例:
struct A
{
int _a;
struct B*pb;
};
struct B
{
int _b;
struct A*pa;
}`;
在结构体A中用了结构体B,在结构体B中用了结构体A
B在未声明的情况下不能被A引用
修改:
struct B;
struct A
{
int _a;
struct B*pb;
};
struct B
{
int _b;
struct A*pa;
}`;结构体变量的定义和初始化
结构体不能整体赋值,类似于数组
错误写法:
struct Node
{
int data;
char ch[10];
};
struct Node x;
x={3,"abc"};
正确写法:
struct Node
{
int data;
struct Node* next;
};
struct Node x={3,"abc"};嵌套结构体的初始化,大括号中套有大括号
struct x
{
int a;
int b;
};
struct Node
{
char ch[10];
struct x num;
struct Node* next;
};
struct Node y={"abcde",{3,4},NULL};结构体内存对齐
1,为什么要内存对齐?
并非所有的硬件平台都能够在任何地址读取任意的数据,部分平台在某些特定的地址只能读取对应类型的数据,举个例子:比如 x平台 在0x00000001出只能读取char型的数据,但你在该地址出定义的数据的数据类型为int,就会出现报错。
所以结构体内每个成员在存储的时候都要内存对齐,为的就是保证代码的平台移植性。
还有,为了读取未对齐的内存,处理器要进行两次内存访问,而对于已经对齐的内存只用进行一次内存访问。
总的来说,内存对齐就是一种用空间换时间的做法。为了节省空间,我们通常将占用内存小的成员集中在一起
2,内存对齐原则 (重点)
(1)第一个成员在与结构体变量偏移量为0的地址处。但这并不是第一个成员不用对齐。
(2). 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。 对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。 VS中默认的值为8 Linux中的默认值为4
(3). 结构体总大小为最大对齐数(每个成员变量除了第一个成员都有一个对齐数)的最小整数倍
(4). 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
以在vs环境下举几个例子:(默认对齐数为8)
struct S1
{
char c1;
int i;
char c2;
};
printf("%d\n", sizeof(struct S1));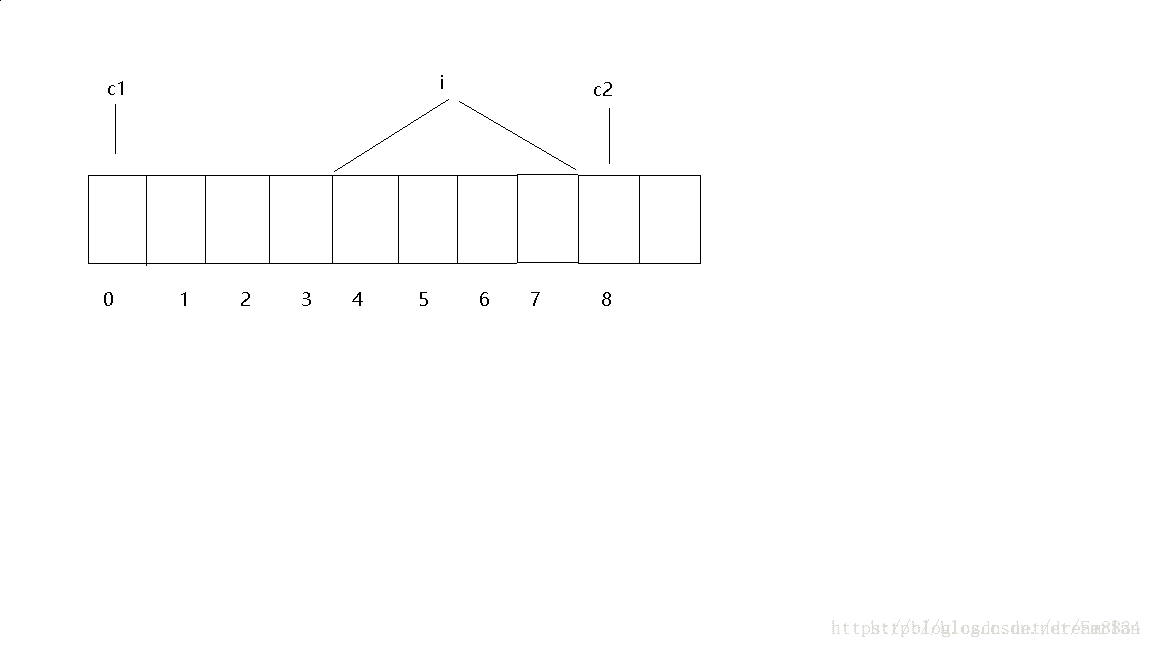
根据第一条规则第一个成员从0偏移量开始,所以c1在0处占据1个字节,而1是四个字节的。
根据第二个原则成员大小与默认对齐数8相比,4为对齐数,所以 1在对齐数的整数倍处对齐,1占据4-7。
c2是一个字节的所以根据第二个原则占据8的位置。
结构体总大小根据第三算则为最大对齐数的整数倍,所以为4的倍数,而8是4的整数倍,座椅总大小就是8。
嵌套结构体例子:
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));
struct S4
{
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));结构体s3的大小为16字节。 在s4中,s3的对齐数取齐内部最大对齐数8,所以s4大小为 1+7+16+8=32字节。
位段
位段的声明和结构是类似的,有两个不同:
1.位段的成员必须是 int、 unsigned int 或signed int 。
2.位段的成员名后边有个冒号和个数字。
3. 位段的空间上是按照需要以4个字节(int )或者1个字节(char )的⽅式来开辟的。
4. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使⽤位段。
例:
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
}位段的跨平台问题
1.int位段贝当成有符号数还是无符号数是不确定的。
2.位段中最大为的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。)
3.位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4.当一个结构包括两个位段,第二个俄日段成员比较大,无法容纳于第一个位段剩余的位时,时舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,但是可以很好的节省空间,但是有跨平台的问题存在。
枚举
顾名思义,枚举就是一一列举。
比如:
enum Day //枚举名称
{
Mon,
Tues,
Wed,
Thur, //枚举变量,默认初值为0,依次递增1。
Fri,
Sat,
Sun
}; //分号不能少枚举的优点:
1. 增加代码的可读性和可维护性
2. 很#define定义的标识符⽐较枚举有类型检查,更加严谨。
3. 防⽌了命名污染(封装)
4. 便于调试
在定义枚举变量时,不能直接令其等于某个值,而应该令枚举变量的值等于原先定义的某个枚举变量。
enum Color//颜色
{
RED=1,
GREEN=2,
BLUE=4
};
enum Color clr = GREEN;//只能拿枚举常量给枚举变量赋值,才不会出现类型的差异。
clr = 5;联合
在联合体内的所有成员共享同一块内存空间。
联合大小的计算
联合体的大小至少是最大成员的大小。
当最大成员的大小不是联合体最大对齐数的整数倍时,联合体的大小就要扩充至对齐数的整数倍。
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};Un1最大成员大小为5字节,但最大对齐数为4,故要扩充至8字节。
Un2最大成员大小为14字节,但最大对齐数为4,故要扩充至16字节。