本文章博客地址:https://blog.csdn.net/qq21497936/article/details/80242112
SQL不完全手册(二):高级语句
接上一部分:《SQL不完全手册(一):概念和基础语句》
https://blog.csdn.net/qq21497936/article/details/80207610
高级语句
1.指定查询返回的记录条数:top
SQL语法:
SELECT TOP number|percent column_name(s)
FROM table_name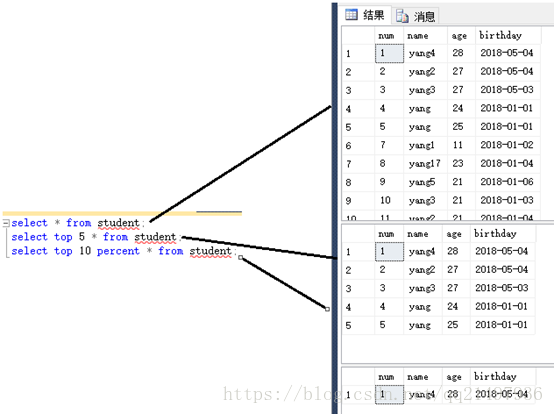
mysql语法
SELECT column_name(s)
FROM table_name
LIMIT numberoracle语法
SELECT column_name(s)
FROM table_name
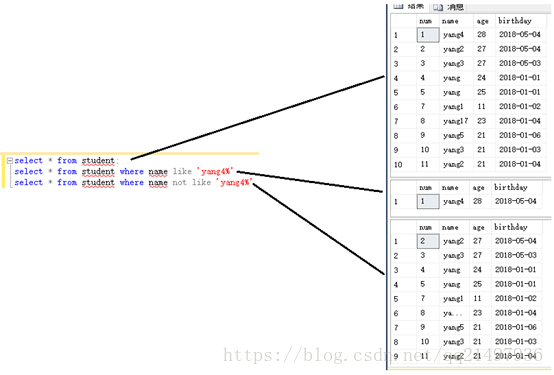
WHERE ROWNUM <= number2.搜索指定匹配或不匹配条件:(NOT) LIKE
SELECT * FROM tabel_name
WHERE colume_name (NOT) LIKE 'N%'
3.搜索指定匹配使用的通配符:% _ [charlist] [^charlist][!charlist]
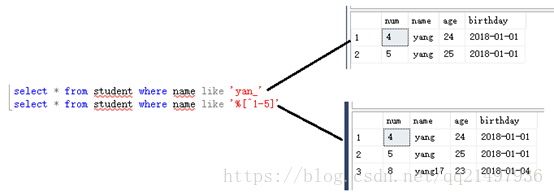
表3:使用LIKE时可使用的通配符
通配符 |
描述 |
% |
替代一个或多个字符 |
_ |
仅替代一个字符 |
[charlist] |
字符列中的任何单一字符 |
[^charlist] 或者 [!charlist] |
不在字符列中的任何单一字符 |
4.规定多个值:where in
指定列的值包含的in后的括号中的所有数据。

5.介于两值之间:where between and
指定两个值之间的数据范围,这些数据可以是数值、文本或者日期
SELECT column_name(s)
FROM table_name
WHERE column_name
BETWEEN value1 AND value2

6.别名:AS(alias)
表名别
SELECT column_name(s)
FROM table_name
AS alias_name列别名
SELECT column_name AS alias_name
FROM table_name

使用列别名(输出的时候,列名改为别名了)

7.多表查询:table1*table2…
常用的方法
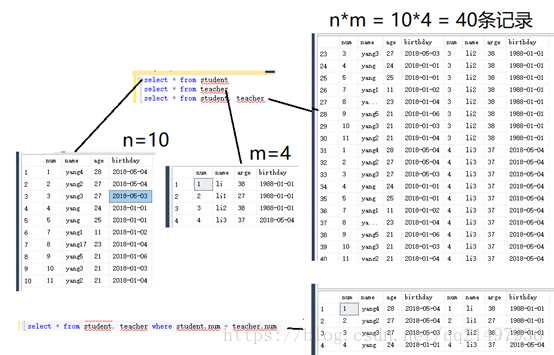
8.内连接:inner join,left join, right join,full join
inner join:如果表中有至少一个匹配,则返回行;(与join相同)
left join:即时右表中没有匹配的行,也从左表返回所有的行;
right join:即时左表中没有匹配的行,也从右表返回所有行;
full join:只要其中一个表中存在匹配,就返回行;
select * from student join teacher on student.num = teacher.num
select * from student inner join teacher on student.num = teacher.num
select * from student left join teacher on student.num = teacher.num
select * from student right join teacher on student.num = teacher.num
select * from student full join teacher on student.num = teacher.num

9.合并两个或多个select语句的结果集:sql union,sql union all
sql union语法(相当于对结果进行distinct了,相同列值只出现一次)
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
sql union all语法(相当于对结果未进行distinct了,每列值都出现)
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2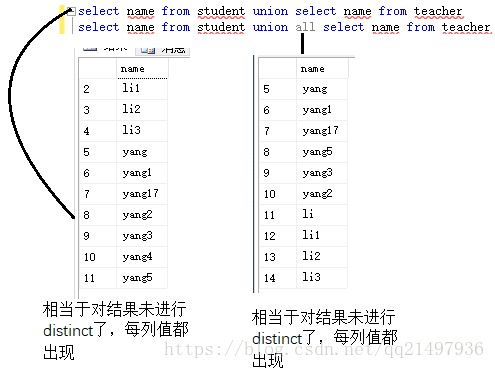
10.从表中查询结果集,将结果集插入另一个表:sql selectinto
select into语句常用语创建表的备份复件或者用于对记录进行存档。
语法:
SELECT *
INTO new_table_name [IN externaldatabase]
FROM old_tablename或者只希望把列插入新表
SELECT column_name(s)
INTO new_table_name [IN externaldatabase]
FROM old_tablename备份表,备份列,如下图:
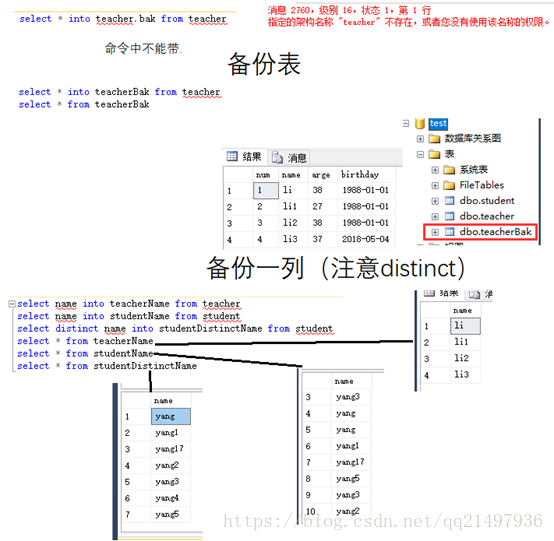
11.索引的使用:sql create index
在表中创建所以,以便更加快速高效的查询数据,用户无法看到索引,它们只能被用来加速搜索/查询。
注意:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是由于索引本身也需要更新。因此理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
创建索引
SQL CREATE INDEX语法
在表上创建一个简单的索引,语序使用重复的值
create index index_name on table_name(column_name)SQL CREATE UNIQUE INDEX语法
在表上创建一个唯一的索引,唯一的索引意味着两个行不能有相同的索引值
create unique index index_name on table_name(cloumn_name)实例
默认升序索引
create index aIndex on A(id)降序索引
create index aIndex on A(id desc)索引多个列
create index aIndex on A(id, name)删除索引
microsoft SQLJet(以及Microsoft Access)的语法
drop index index_name on table_namems sql server
drop index table_name.index_nameibm db2/oracle
drop index index_namemysql
alter table table_name drop index index_name12.修改表:ALTER TABLE
用于在已有的表中添加、修改或删除列
添加列
alter table table_name
add column_name datetype删除列
alter table table_name
drop column column_name修改列的数据类型
alter table table_name
alter column column_name datatype13.生成一个唯一的自增数字标识:SQL AUTOINCREMENT
mysql语法
create table demoAuto(
id int not null auto_increment
name varchar(255),
primary key(id)
)auto_increment的开始值是1,每条新纪录递增1,可修改起始值,如下:
alter table demoAuto auto_increment=100插入新纪录是,没必要指定自增的id值
insert into demoAuto(name) values('yang')sql server语法
my sql使用identity关键字来执行 auto-increment 任务。
create table demoAuto(
id int primary key identity,
name varchar(255)
)
若需要起始值为10,每隔20递增,则定义的时候使用identity(10,20)
access的语法
create table demoAuto(
id int primary key autoincrement,
name varchar(255)
)oracle语法
在oracle代码复杂,必须使用create sequence对创建auto-increment字段
CREATE SEQUENCE seq_auto
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10上面代码,创建名为seq_auto的序列对象,以1起始,以1递增,缓存10个对象以提高性能。
14.视图:SQL VIEW
视图是可视化的表,基于SQL语句的结果集的可视化表,视图包含行和列,就像一个真实的表,视图中的字段来自一个或多个数据库中真实的表中的字段(可使用别名替换显示),可向视图添加SQL函数、where以及join语句,也可以提交数据,就像某些来自于某个单一的表。
注意:数据库的设计和结构不会受视图的中函数、where或join语句的影响。
创建视图
create view view_name as select_syntax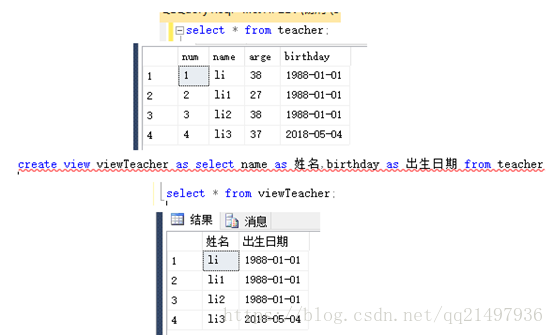
更新视图
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition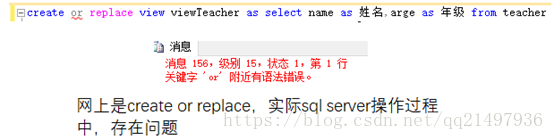
撤销视图
sql drop view
drop view teacherView15.日期数据类型:Date
表4:sql server 日期函数
函数 |
描述 |
getdate() |
返回当前日期和时间 |
datepart() |
返回日期/时间的单独部分 |
dateadd() |
在日期中添加或减去指定的时间间隔 |
datediff() |
返回两个日期之间的时间 |
convert() |
用不同的格式显示日期/时间 |
sql server Date数据类型
date:格式 yyyy-mm-dd
dateTime:格式yyyy-mm-dd hh:mm:ss
smallDateTime:格式yyyy-mm-dd hh:mm:ss
timeStamp:唯一的数字

表5:mysql重要的内建日期函数
函数 |
描述 |
now() |
返回当前日的日期和时间 |
curDate() |
返回当前的日期 |
curTime() |
返回当前的时间 |
date() |
提取日期或日期/时间表达式的日期部分 |
extract() |
返回日期/时间按的单独部分 |
date_add() |
给日期添加指定的时间间隔 |
date_sub() |
从日期减去指定的时间间隔 |
datediff() |
返回两个日期之间的天数 |
date_format() |
用不同的格式显示日期/时间 |
16.sql的null值处理:SQL IS NULL,IS NOT NULL ISNULL()、NVL()、IFNULL()和COALESCE()
SQL IS NULL,IS NOT NULL
如果表中的某个列是可选的,那么可以不向该列添加值,插入新纪录则该字段将以NULL值保存。
NULL值得处理方式与其他值不同。
NULL用作为止的或不适用的值的占位符。
注:无法比较NULL和0,它们是不等价的。
select * from student where birthday is null;
select * from student where birthday is not null;SQL ISNULL()、NVL()、IFNULL()和COALESCE()函数
sql server/ms access
ISNULL定义如何处理null
SELECT ProductName,UnitPrice*(UnitsInStock+ISNULL(UnitsOnOrder,0))
FROM Productsoracle
SELECT ProductName,UnitPrice*(UnitsInStock+NVL(UnitsOnOrder,0))
FROM Productsmysql
SELECT ProductName,UnitPrice*(UnitsInStock+IFNULL(UnitsOnOrder,0))
FROM Products
SELECT ProductName,UnitPrice*(UnitsInStock+COALESCE(UnitsOnOrder,0))
FROM Products17.数据库的数据类型
sql server的数据类型
Character字符串
数据类型 |
描述 |
存储 |
char(n) |
固定长度的字符串,最多8000个字符 |
n |
varchar(n) |
可变长度的字符串,最多8000个字符 |
|
varchar(max) |
可变长度的字符串,最多1073741824个字符 |
|
text |
可变长度的字符串,最多2GB字符数据 |
unicode
数据类型 |
描述 |
存储 |
nchar(n) |
固定长度的unicode数据,最多4000个字符 |
|
nvarchar(n) |
可变长度的unicode数据,最多4000个字符 |
|
nvarchar(max) |
可变长度的unicode数据,最多53687912个字符 |
|
ntext |
可变长度的unicode数据,最多2GB字符数据 |
binary
数据类型 |
描述 |
存储 |
bit |
允许0、1或NULL、 |
|
binary(n) |
固定长度的二进制数据,最多8000字节 |
|
varbinary(n) |
可变长度的二进制数据,最多8000字节 |
|
varbinary(max) |
可变长度的二进制数,最多2GB字节 |
|
image |
可变长度的二进制数据,最多2GB字节 |
number
数据类型 |
描述 |
存储 |
tinyint |
允许从0到255的所有数字 |
1字节 |
smallint |
允许从-32768到32767的所有数字 |
2字节 |
int |
允许从-2147483648到2147483647的所有数字 |
4字节 |
bigint |
允许介于-9223372036854775808和9223372036854775807之间的所有数字 |
8字节 |
decimal(p,s) |
固定精度和比例的数字,允许从-10^38+1到10^38-1之间的数字。 p参数指示可以存储的最大位数(小数点左侧和右侧)。p必须是1到38之间的值,默认是18。 s参数指标小数点右侧存储的最大位数,s必须是0到p之间的值,默认是0 |
5-17字节 |
numeric(p,s) |
固定精度和比例的数字,允许从-10^38+1到10^38-1之间的数字。 p参数指示可以存储的最大位数(小数点左侧和右侧)。p必须是1到38之间的值,默认是18。 s参数指标小数点右侧存储的最大位数,s必须是0到p之间的值,默认是0 |
5-17字节 |
smallmoney |
允许从-2147483648到2147483647的货币数据 |
4字节 |
money |
许介于-9223372036854775808和9223372036854775807之间的货币数据 |
4字节 |
float(n) |
从-1.79E+308到1.79E+308的浮动精度数字数据。参数n指示该字段保存4字节还是8字节。float(24)保存4字节,而float(53)保存8字节。n的默认值是53 |
4或8字节 |
real |
从-3.04E+38到3.40E+38的浮动精度数字数据 |
4字节 |
date
数据类型 |
描述 |
存储 |
dateTime |
从1753年1月1日到9999年12月31日,精度为3.33毫秒 |
8bytes |
dateTime2 |
从1753年1月1日到9999年12月31日,精度为100纳秒 |
6-8bytes |
smallDateTime |
从1900年1月1日到2079年6月6日,精度为1分钟 |
4bytes |
date |
仅存储日期。从0001年1月1日到9999年12月31日 |
3bytes |
time |
仅存储事件。精度为100纳秒 |
3-5bytes |
datetimeoffset |
与dateTime2相同,外加时区偏移 |
8-10bytes |
timestamp |
存储唯一的数字,每当创建或修改某行时,该数字会更新。timestamp基于内部时钟,不对应真实事件 |
其他类型数据
数据类型 |
描述 |
sql_variant |
存储最多8000字节不同数据类型的数据,除了text、ntext以及timestamp |
uniqueIdentifier |
存储全局标识符(GUID) |
xml |
存储xml格式化数据,最多2GB |
cursor |
存储对用于数据库操作的指针的引用 |
table |
存储结果集,供稍后处理 |
《SQL不完全手册(三):函数》:https://blog.csdn.net/qq21497936/article/details/80262309
原博主博客地址:https://blog.csdn.net/qq21497936
本文章博客地址:https://blog.csdn.net/qq21497936/article/details/80242112