今天编的这个小程序是哈姆雷特中的词频统计,即统计哈姆雷特中各个词语出现的频率。我第一次尝试了使用自顶向下的设计方法和自下向上的执行方法。期间出现了很多错误,在此记录,以免日后再犯。
编程前截取网上Hamlet其中的一段,要注意的是:保存为txt类型时,编码方式选择'utf-8'。如图:

接下来分析整个编程的题目,并列出步骤:
第一步,打开文件并读取,将每个单词都分割开。
第二步,考虑到大小写的问题,将所有的字母都换为小写。
第三步,统计每个单词出现的频率,并高至低输出。
由此,主函数main()为:

split()函数将文件中的单词读取并分割开来,得到splitwords的列表,swapcase()函数将全部单词转换为小写模式,得到新的列表。countTimes()函数统计每个单词出现的频率,以字典的形式输出。outputs()函数和sorts()函数排序输出。
代码如下:
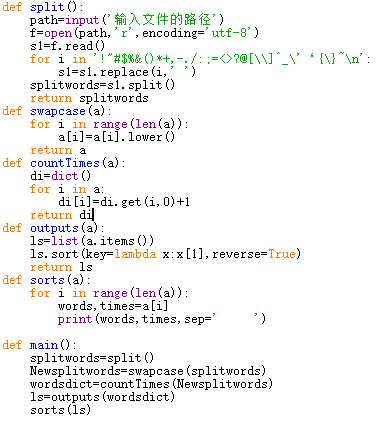
调试程序时发现了很多错误:
1.对象的使用方法上:如s1.replace后并没有将更新的字符串在赋给s1。return ls.sort直接返回,造成返回的结果为空值。应返回ls,而不是返回一个方法过程。
2.循环时,总是少加range。
3.定义的split()函数不能以'\n‘分割,需以空格分割。
程序结果如下,没有格式输出。

日后还要多加练习。