在采集服务器用户log信息 上传到 MacComputer 中 分享下自己的经验
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全
我建议在开始项目之前一定要仔细的查看官方文档,以避免浪费很多时间,或者导致很简单的的问题提工单
我使用的是flume采集日志 信息到DataHup归档到 MaxComputer
官方给出的 方式有好几种 可以根据业务不同使用不同的采集 方式 ,如 Fluentd插件 Logstash插件 等
Flume 采集log信息 官网案列
准备工作
1)拥有Linux系统。
2)拥有一定的开发经验。
3)拥有阿里云官网实名认证账号,并且创建好账号Access Key。
教程任务
1)安装JDK和Flume,开通MaxCompute和Datahub。
2)下载并部署Datahub Sink插件。
3)创建需要上传的本地文件,创建Datahub Topic。
4)配置Flume作业配置文件。
5)启动Flume,将数据上传至Datahub。
6)配置Connector将数据归档至MaxCompute。
实施前注意
看完上边官网案列,大概流程或许已经明白,我们在实际操作中可能会遇到很多的问题
1 我们应该需要什么样的上传格式,案列中使用的逗号" , " 来 区分字段是否符合我们的需要
2 flume 配置文件中不得出现中文注释,我们要确保正确的 access ID和access key 均是字符串形式 ,endpoint可以在文档中查询
3 使用dataconnector 自动归档,MaxComputer表字段必须 与DataHup 一致
我们要在datahup中 创建 project > > 创建 topic , 如果需要归档到 maxcomputer中建议新建topic时候从maxcomputer 导入,所以要先在maxcomputer 中新建 表(建议分区表),如果使用非自定义分区,建表时候还需按文档添加分区字段 >> 在 datahup 中使用maxcomputer 中的表导入,此时注意创建分区,分区选项提供三种方式,自选 >> 创建dataconnector 即可自动离线归档
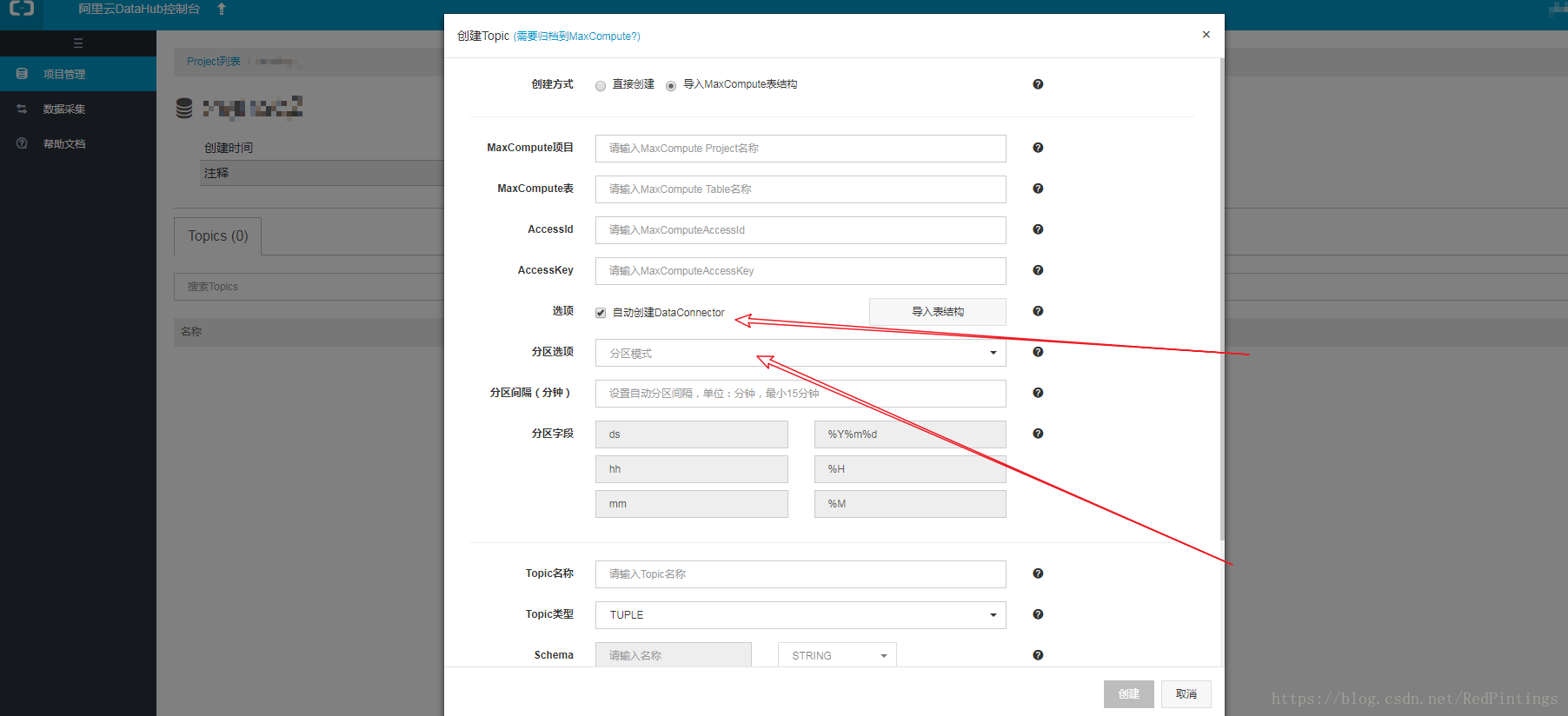
顺序 maxcomputer按照分区字段和内容字段新建 表 >> 在datahup 中按maxcomputer创建topic 表,分区,及关联 >>
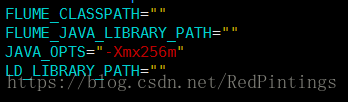
按照官网配置教程或许 配置 flume 在运行会出现内存溢出的错误 可以在 ${FLUME_HOME}/flume/bin/flume-ng 进行 调整
数据实时处理:
如果我们的日志信息 与我们要存表的字段不符,我们可以通过datahup SDK 进行数据的实时处理, 阿里云 DataHup SDK
建议在看完文档 后实施开发时候 参考githup 上的方法,git上边比较新,一些新的参数SDK 上并没有及时更正
PythonSDK 中订阅数据获取Cursor,可以通过四种方式获取:OLDEST, LATEST, SYSTEM_TIME, SEQUENCE
建议用前三种,第四种官方没有具体实践,无论使用那种方式 ,获取的数据都不重复,主要注意的是 limit_num参数 。
订阅最多返回1000条数据,其他详见 while True 实例代码。
可以对数据进行 订阅后实时处理 并上传到DataHup 离线归档到 MaxComputer上,DataHup Git
PS : 阿里云PyODPS 技术支持(公共云)钉钉群: 11701793