原文地址:点这里
合理的使用缓存可以极大地提高网站资源的利用率,还可以节约带宽从而降低服务器成本。但是很多站点针对缓存的策略并不合理,甚至是完全无作为,如果是这样,就完全没有发挥出缓存的优势,而不合理的策略反而很大程度上会导致网站在访问时会发生由于静态资源的竞争关系而导致依赖的静态资源不同步的问题(简单地说,就是页面发生了崩坏)。
以下为两个最佳静态资源缓存实践的例子:
资源内容长时间内稳定不变
// 设置缓存时间为1年
Cache-Control: max-age=31536000资源的内容非常稳定,长时间内都不会发生变更,那么我们就可以声明浏览器/CDN可以长时间缓存该资源(31536000秒,即一年),只要用户不手动清理浏览器缓存,一年内源服务器都不再会收到(当前浏览器/CDN)对该资源的请求。
接下来看一看实际的应用场景:
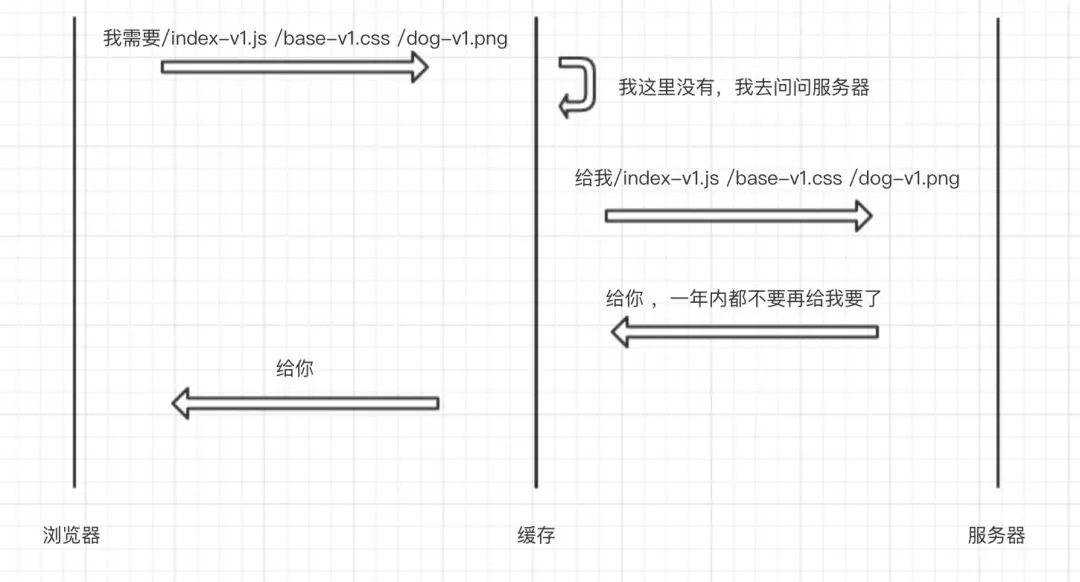
第一天
浏览器请求了/index-v1.js、/base-v1.css以及/dog-v1.png这三个资源,时序图如下:
第二天
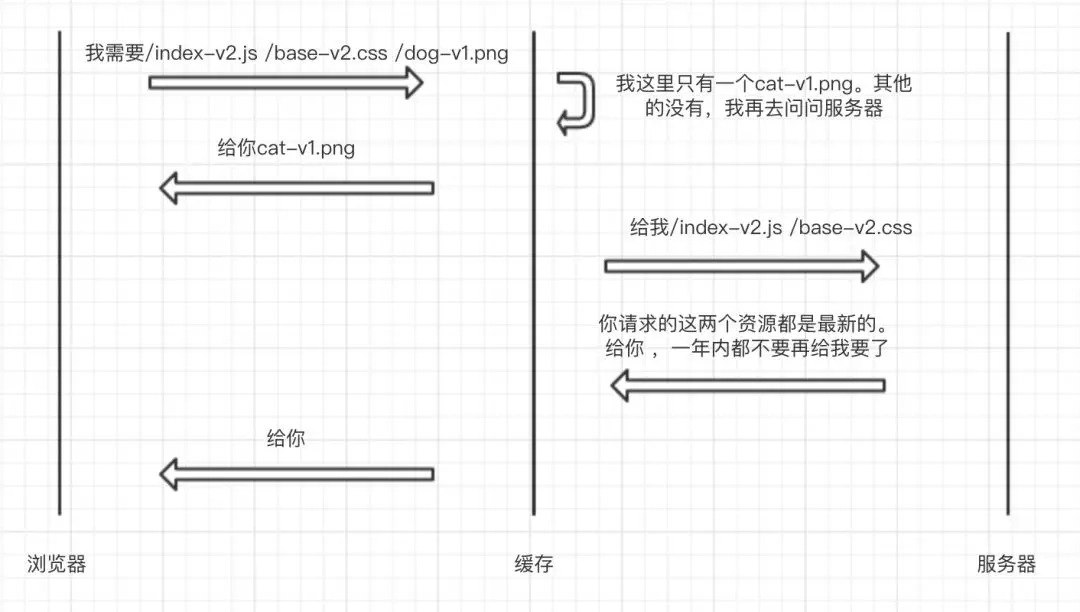
这次浏览器请求了/index-v2.js、/base-v2.css以及/dog-v1.png这三个资源,时序图如下:
此处注意:index.js和base.css与第一天请求的版本号不同。
一年后
在一年的时间里,浏览器再也没有请求过/index-v1.js、/base-v1.css以及/dog-v1.png这三个资源,浏览器缓存就会把它们给删掉,时序图如下:

所以在这个例子中,为了让缓存发挥最大效率,你要做的并不是更改文件的内容,而是应该更改资源的URL:
<script src="/index-v3.js"></script>
<link rel="stylesheet" href="/base-v3.css">
<img src="/dog-v3.jpg" alt="…">每一个静态资源URL都应该跟随其内容的修改而改变。例如示例index-v1.js中的v1,你对它的命名不需要有任何限制。它可以是一个版本号,最后修改的日期,或者根据内容计算出来的散列值。
绝大多数服务器端的框架都提供了工具来实现这一点,同样的在nodejs中有很多优秀的库来实现这个功能,比如gulp-rev、webpack、fis3。
资源经常发生变更
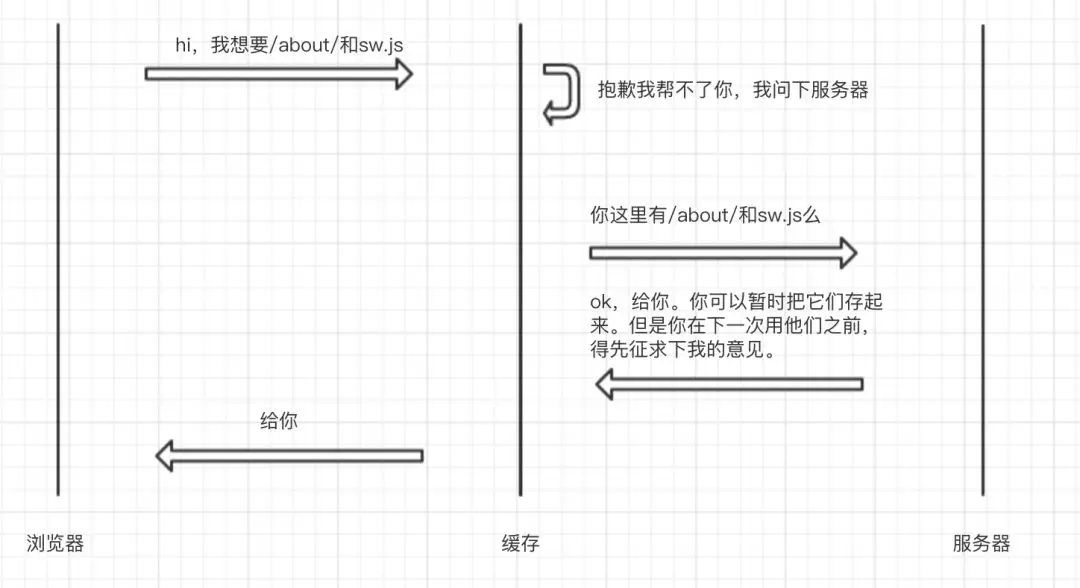
Cache-Control: no-cache资源的内容经常发生变化,没有服务器的确认,任何本地缓存的资源都是不可信的,那么我们就可以声明不读取该资源的缓存,需要调用该资源时每次都尝试向源服务器获取。
第一天
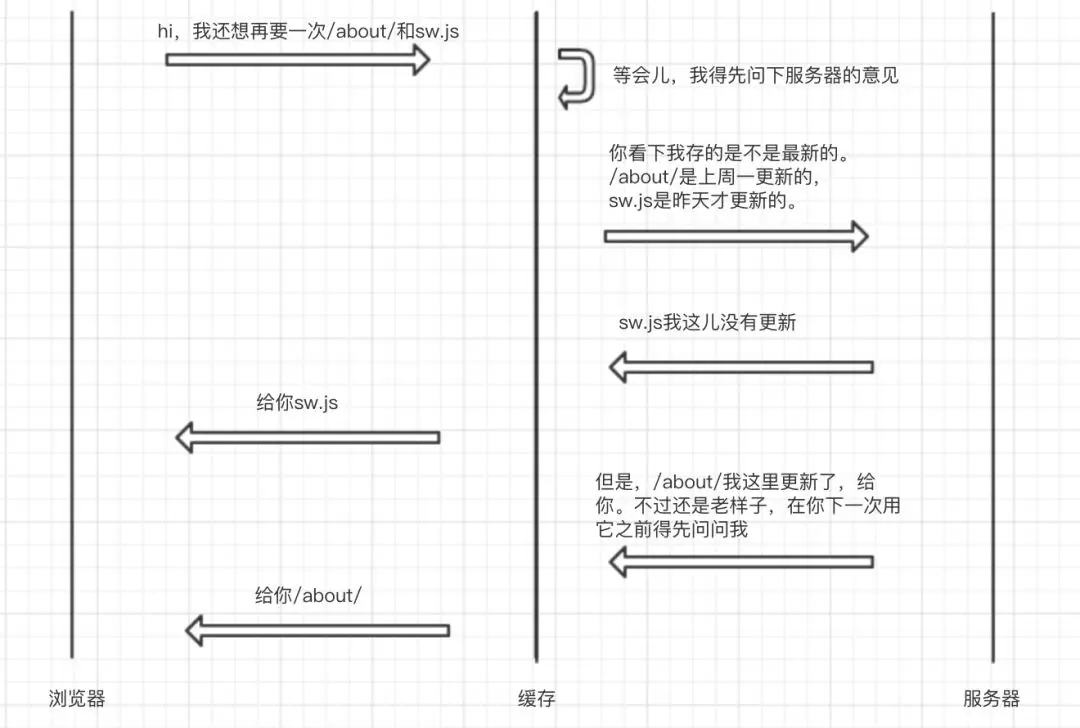
第二天
注意:
no-cache并不意味着不缓存。它的意思是在使用缓存资源之前,它必须经过服务器的检查(revalidate也可以实现这个功能)。
no-store才是告诉浏览器不要缓存它。此外,must-revalidate并不意味着必须重新认证,它的前提是资源还在max-age的缓存期内,否则必须重新认证。
在此模式下 ,你也可以将ETag(你选择的版本ID)或者Last-modified日期添加到响应首部中。客户端下次获取资源时,他会分别通过If-None-Match(与ETage对应)和If-Modified-Since(与Last-Mofied对应)两个请求首部将值发送给服务器。如果服务器发现两次值都是对等的,就是返回一个HTTP 304。
如果没有发送ETag和Last-Modified,那么服务器将始终返回完整的资源内容。
但是这种方法有个缺点,就是它每次都会去服务器做一次验证,涉及到了网络提取,所以它不如第一个例子那样可以完全绕过网络。
下面来看一个页面崩坏的例子:
在经常修改内容的静态资源上使用max-age
当前页面包含文件/article/、/styles.css和/script.js,他们的缓存策略如下:
// 十分钟内不需要重新认证,超过十分钟就需要重新认证
Cache-Control: must-revalidate, max-age=600当页面文件发生变更时,文件路径会发生变化(如文件名会包含文件算出的哈希),在十分钟内,浏览器将会一直使用缓存住的内容,而不会去服务器请求最新的资源 ;超过十分钟,在可用的前提下使用If-Modified-Since和If-None-Match重新进行服务器认证。
这个描述看起来没毛病,那么我们来看一下实际使用中会发生什么:
第一次请求
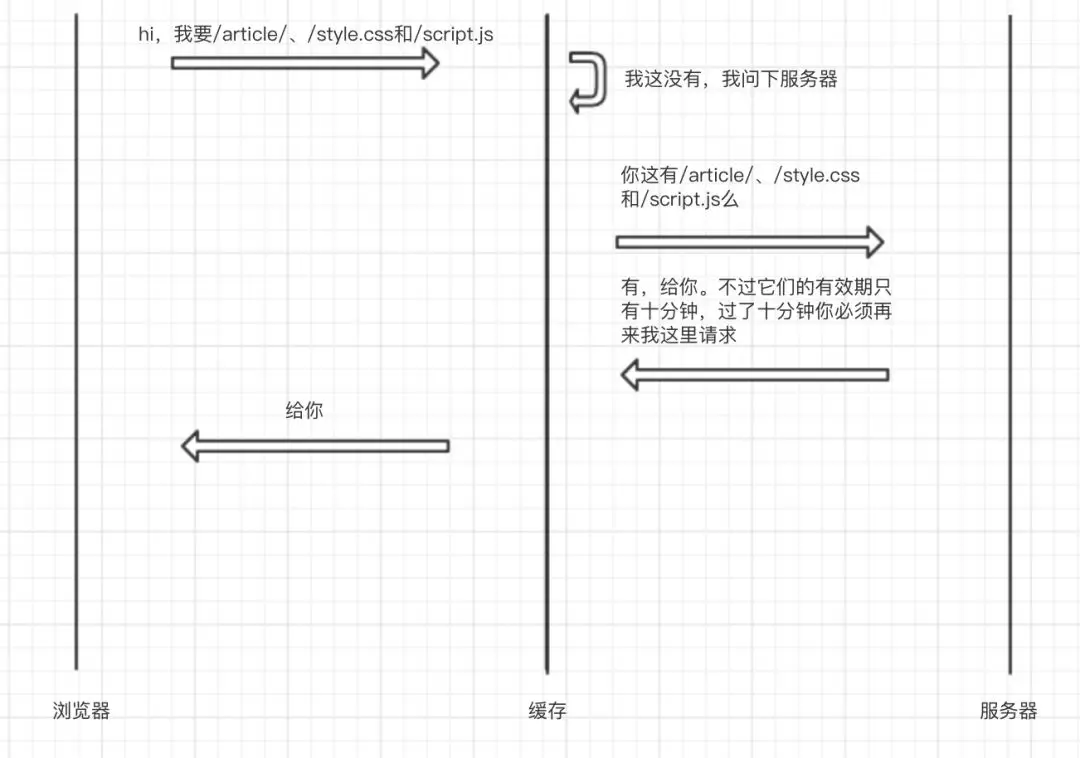
几分钟后
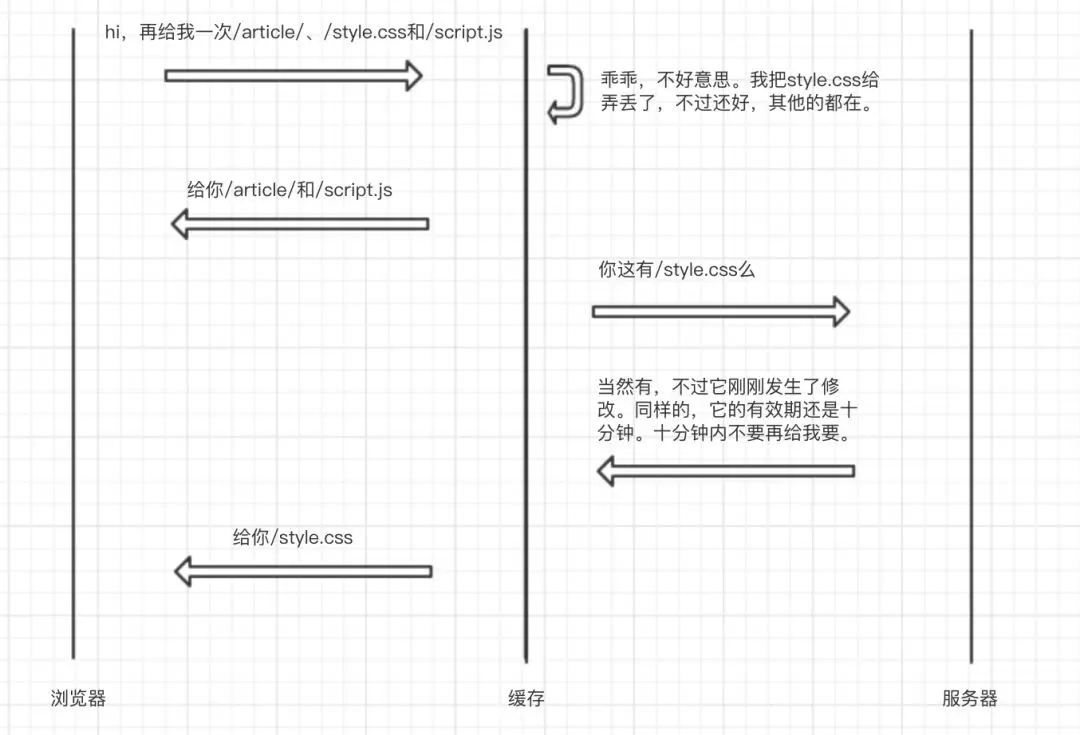
最终

想象一下,在线上环境你永远不知道浏览器前面坐着的是什么样的人,他很有可能无意中胡乱地用鼠标点点点(比如删掉了style.css的本地缓存),就打乱了浏览器的静态资源缓存机制,导致页面发生了错乱,而且真的很难追踪(删除行为无法记录)。
在上面的例子中,服务器实际上已经更新了HTML、CSS和JS,但是页面最后使用的是缓存中旧的HTML和JS,以及刚从服务器下载的最新的CSS,多个静态资源版本之间不匹配的问题随之出现,进而导致了页面的崩坏。
通常,当需要对HTML进行重大修改时,我们会更改CSS文件来适配新的DOM结构,并且更新JS来配置样式和DOM的修改。这些资源都是相互依赖的,但携带缓存信息的HTTP首部可不管你这些有的没的。最终,用户很有可能会得到一个/两个静态资源新版本,而其他资源都是旧版本。
max-age是相对于服务器响应时间的,所以如果所有上述资源都在同一时间请求,即便它们都被设置为了相同的max-age时长,它们仍然存在很小的竞争可能性(毕竟有的资源先返回有的资源后返回)。如果你的某些页面不包含JS,或者包含不同的CSS,它们的缓存失效时间就有可能会不同步。更恶心的是,浏览器始终会从缓存中删除和获取资源,它并不知道这些资源中哪个是相互依赖的,只要过了缓存时间它就会毫不犹豫地删掉一个,并不会删掉这个过期文件所依赖的其他资源。把上面的种种可能性加在一起,就会大概率出现静态资源版本不匹配的问题。
不过还好,我们还有法子来解决这个问题:
强制刷新浏览器或者清除缓存
在强制刷新浏览器或者清除缓存后,请求的页面以及页面内的所有资源会忽略之前的max-age,去服务器做重新认证。因此,如果用户由于max-age出现问题之后,只需要强制刷新或者清缓存就可以修复问题。当然,强迫用户这样做只会让它们降低对你网站的信任度,认为你的网站不靠谱。
原文在这里写了使用serviceWorker来解决上面的页面崩坏问题,按笔者的理解,serviceWorker就是对有依赖关系的资源进行了捆绑,一旦其中一个过期,则所有的资源都要重新获取;但问题是serviceWorker并不是所有浏览器都支持,即使chrome和firefox也仅在最近的版本才开始支持,所以在这里就不贴出来了,有兴趣的同学可以去原贴看一下。
在内容经常修改但是URL不变的静态资源上使用max-age在通常意义上来说不是一个好点子,但事实却不总是如此。
假如一个页面的max-age为三分钟,并且在这个页面上不需要考虑静态资源的竞争关系,即在这个页面上不存在任何的静态资源依赖,那么在这种情况下就可以尽情使用max-age,当然,代价是网站的修改要在三分钟之后才可以被看到。
不过要是页面存在静态资源竞争关系的话,这种法子不好用了,比如我现在有两个文章A和B,我现在文章A中添加一个新的章节,然后在文章B中增加了一个指向文章A新增章节的超链接。然后我从文章B中访问这个链接,假如文章A的max-age没有过期,那么我访问到的文章A里将会发现文章并没有那个新增的章节。此时只能等max-age过期或者强制刷新浏览器,再或者清除缓存了。所以,一定要谨慎使用这种方法。
正确使用缓存可以代理巨大的性能收益并且有效节省服务器带宽。既支持版本号类型的静态资源缓存方式也支持服务器重新认证(no-cache、304)的方式。如果你觉得自己很勇敢,那么大可混合使用max-age,但是前提你得确定自己的HTML中没有静态资源竞争关系。
最后简单汇总一下合理的缓存策略:HTML使用每次服务端验证的方式来保证资源是最新的,CSS和JS则可以使用设置max-age,但发生变更后更新资源路径(如重新计算文件的哈希,并把哈希值加入文件名中)的方式来保证资源是最新的,当然,这样做需要在HTML中同步更新依赖CSS和JS的资源路径(虽然之前的CSS和JS仍在缓存期内,但实际页面已经正确使用了更新后的资源)。