第十二课任务一
1,打印某行到某行之间的内容http://ask.apelearn.com/question/559
2,sed转换大小写 http://ask.apelearn.com/question/7758
3,sed在某一行最后添加一个数字http://ask.apelearn.com/question/288
4,删除某行到最后一行 http://ask.apelearn.com/question/213
5,打印1到100行含某个字符串的行 http://ask.apelearn.com/question/1048
6,awk 中使用外部shell变量http://ask.apelearn.com/question/199
7,awk 合并一个文件 http://ask.apelearn.com/question/493
8,把一个文件多行连接成一行 http://ask.apelearn.com/question/266
9,awk中gsub函数的使用 http://ask.apelearn.com/question/200
第十二课预习任务二
10,awk 截取指定多个域为一行 http://ask.apelearn.com/question/224
11,过滤两个或多个关键词 http://ask.apelearn.com/question/198
12,用awk生成以下结构文件 http://ask.apelearn.com/question/5494
13,awk用print打印单引号 http://ask.apelearn.com/question/1738
14,合并两个文件 http://ask.apelearn.com/question/945
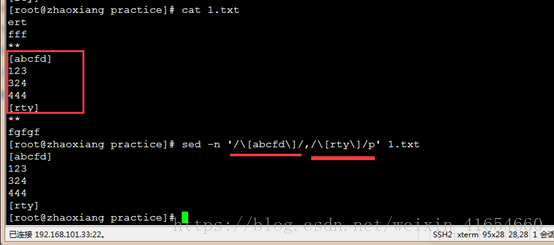
1,过滤红色框框中(行-行)的内容
sed -n '/\[abcfd\]/,/\[rty\]/p' 1.txt 过滤[abcfd]-[rty]之间的行
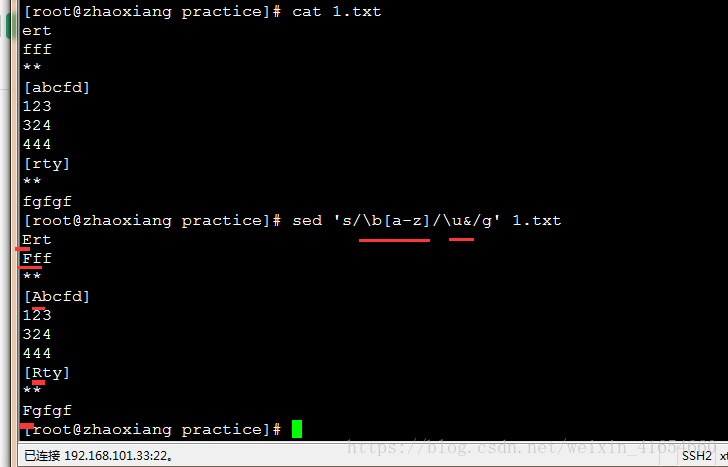
2,使用sed转换大小写字母
提示\u表示大写,\l表示小写
把每个单词的第一个字母变成大写
\b 表示单词的边界,& 表示 第一个 // 里面的内容
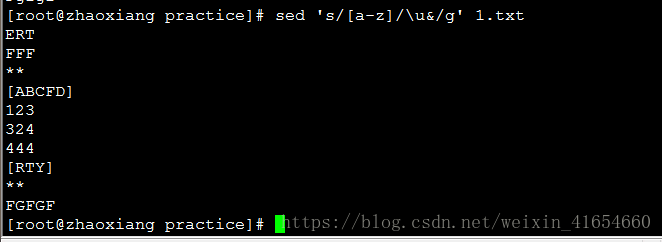
把所有小写变大写,
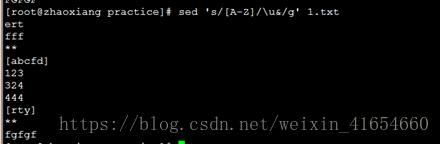
把所有的小写变成大写
3,文章某一行后添加12,这里代表从第一个字符为4开始的行添加12
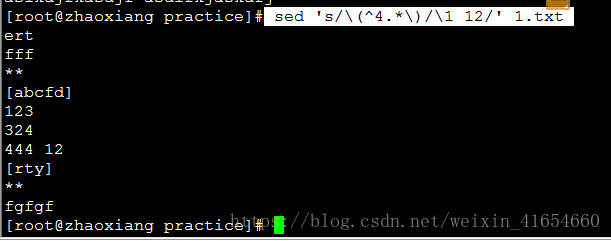
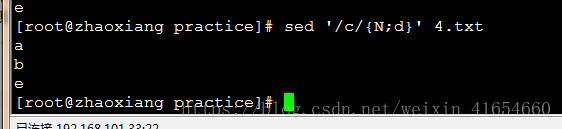
4,sed删除某关键字的下一行到最后一行
sed '/c/{p;:a;N;$!ba;d}' 4.txt 删除字符匹配d之后的行
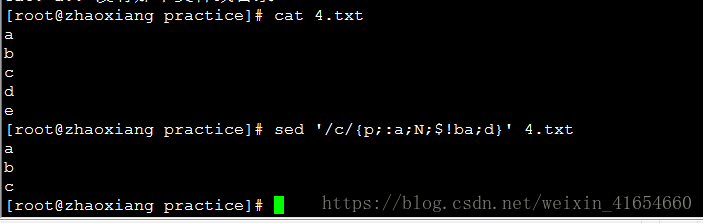
删除c和c的下一行
5,使用sed打印1到100行包含某个字符串的行
例如打印有324的行
sed -n '1,100{/324/p}' 1.txt

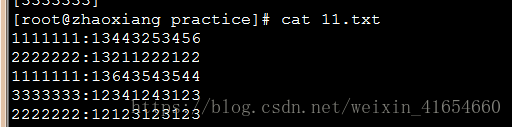
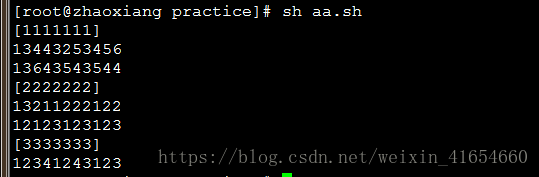
6,awk中使用外部shell变量
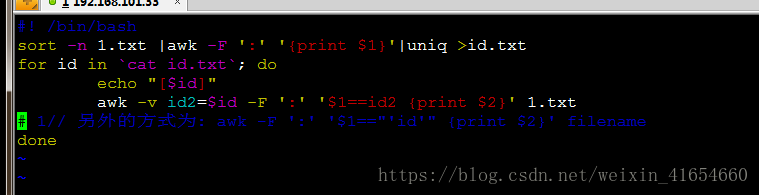
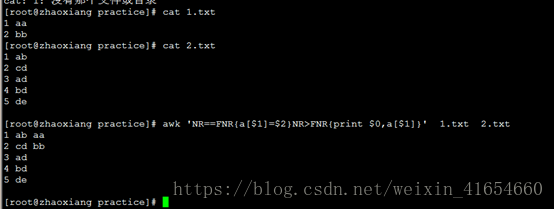
7,合并1,2两个文件
awk 'NR==FNR{a[$1]=$2}NR>FNR{print $0,a[$1]}' 1.txt 2.txt
NR==FNR 就表示读取1.txt的时候。 同理NR>FNR表示读取2.txt的时候
8,把一个文件多行连接成一行
cat 1.txt |xargs

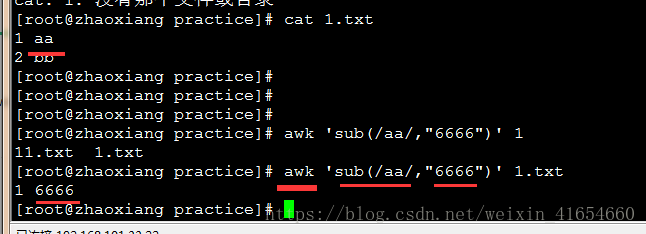
9,awk中gsub函数的使用
awk 'sub(/aa/,"6666")' 1.txt 将出现aa字符的用6666替代
10,把所选段放到一行
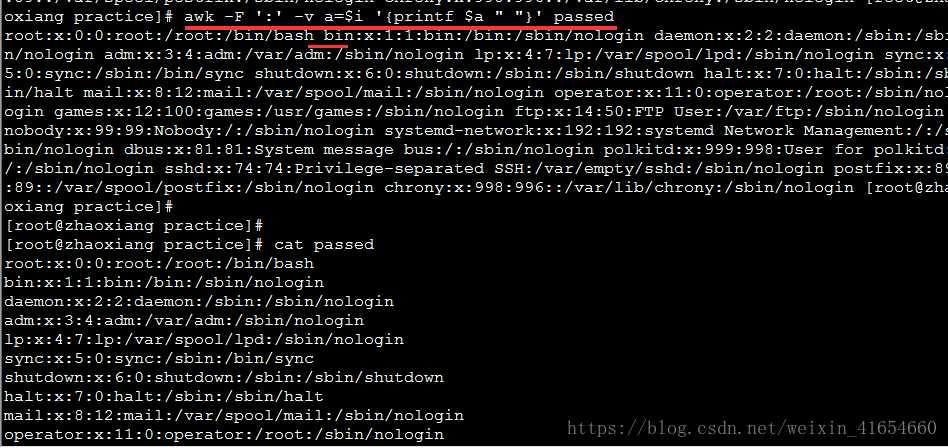
awk -F ':' -v a=$i '{printf $a " "}' passed //这里用了空格号隔开
11,过滤一个或者多个关键字
grep -E '123|abc' filename // 找出文件(filename)中包含123或者包含abc的行
egrep '123|abc' filename //用egrep同样可以实现
awk '/123|abc/' filename // awk 的实现方式
例如grep -E 'ab|cd' 2.txt
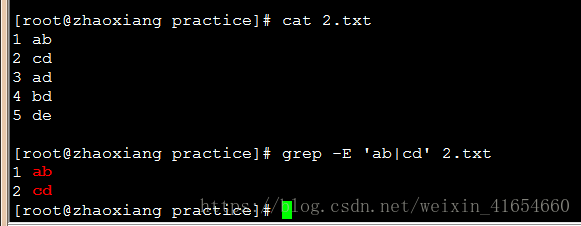
awk '/ab/||/cd/{print}' 2.txt 或者中间用或符号连接

12,用awk编写生成以下结构文件的程序
( 最后列使用现在的时间,时间格式为YYYYMMDDHHMISS) 各列的值应如下所示,每增加一行便加1,共500万行。
1,1,0000000001,0000000001,0000000001,0000000001,0000000001,0000000001,2005100110101
2,2,0000000002,0000000002,0000000002,0000000002,0000000002,0000000002,2005100110101
这里做测试用的10,
awk 'BEGIN{for(i=1;i<=10;i++)printf("%d,%d,%010d,%010d,%010d,%010d,%010d,%010d,%d\n",i,i,i,i,i,i,i,i,strftime("%Y%m%d%H%M%s"))}'

13,Awk用print打印单引号,双引号
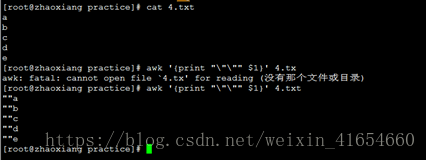
打印$

14,合并两个文件
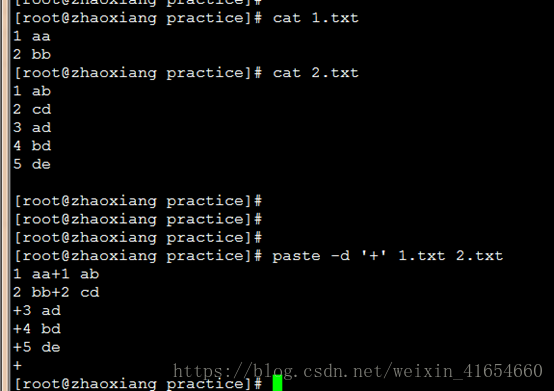
或者用awk
awk 'NR==FNR {a[FNR]=$0} NR>FNR {print a[FNR],$0}' 1.txt 2.txt

增加一个+号
awk 'NR==FNR {a[FNR]=$0} NR>FNR {print a[FNR],"'"+"'",$0}' 1.txt 2.txt
NR==FNR {a[FNR]=$0}打开文件
NR,表示awk开始执行程序后所读取的数据行数
FNR,与NR功用类似,不同的是awk每打开一个新文件,FNR便从0重新累计
NR==FNR,第一个文件,以$0为下标
NR>FNR

15,awk的BEGIN和END http://blog.51cto.com/151wqooo/1309851
16,awk的参考教程 http://www.cnblogs.com/emanlee/p/3327576.html