这个算法写起来真的很简单,并且思路也好理解。
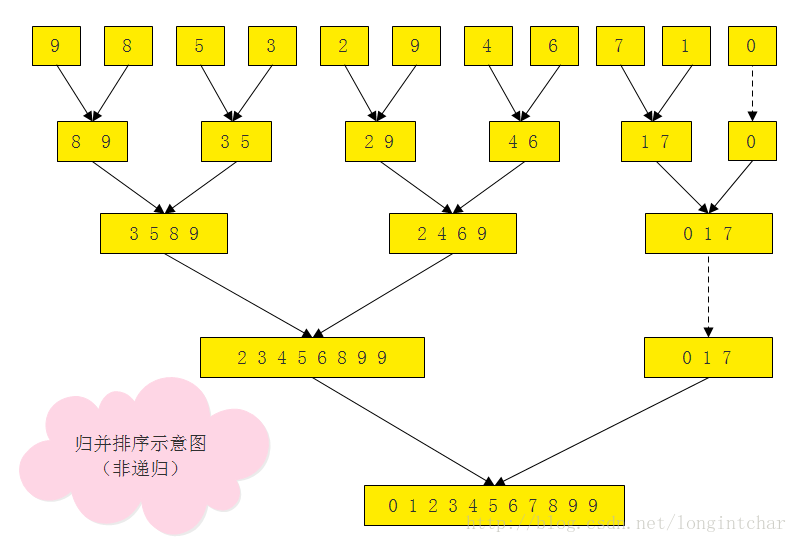
我们看附图

这就是我们的分治算法模型图 。
我们这么理解,我们知道当一个列表越长我们进行排序消耗就越大,那么我们把这个列表分为无数个小的列表,然后对他们进行排序,然后再组合,那么也会节省不少精力
我们直接看代码
首先我们的第一步是
分:
merger_sort
public static void merger_sort(int[] a,int[]temp,int start,int end){
/**
*@MethodName:merger_sort
*@Params:[a, temp, first, end]
* @param a:传入的原始数组,因为我们要通过原始数组获取分成小段的值
* @param temp:临时数组,用来保存拼接而成数组
* @param start:开始的头下表
* @param end:的尾下表
*@Return:void
*@Description:递归的方法
*/
if (start<end){//如果还没有分成最小的部分
int middle=(start+end)/2;//每次递归从中间分割
merger_sort(a,temp,start,middle);//左边的部分进行分割
merger_sort(a,temp,middle+1,end);//右边的部分进行分割
merger(a,temp,start,middle,end);//当执行到这个方法时我们将上面当前层的部分进行比较并拼接
}
}我们首先将列表分为最小的部分,我们就像上图一样想成一个层,merger方法就会将每层的两个数组进行排序并且拼接
我们看
归:
merger方法:
private static void merger(int[] a, int[] temp, int start, int middle, int end) {
int startRecord=start;
int middleTemp=middle+1;
// int endTemp=end;
int count=0;
while (start<=middle&&middleTemp<=end){//当两个列表都没比较完大小
if (a[start]<=a[middleTemp]){//如果左侧当前下标的值小
temp[count++]=a[start++];//我们将左侧当前下标的值存入temp临时数组
}
else//如果右侧当前下标的值小
temp[count++]=a[middleTemp++];//我们将右侧当前下标的值存入temp临时数组
}
while(start<=middle){//当右边数组全存入而左边的数组未存完
temp[count++]=a[start++];
}
while(middleTemp<=end){//当左边数组全存入而右边的数组未存完
temp[count++]=a[middleTemp++];
}
for (int i=0;i<count;i++){
//将相应的tmp的值存入a数组,这
// 里不用担心打乱a的顺序而导致后面的操作无法进行,我们当前的操作都是操作先这层原本在a中区域的下标的
a[startRecord++]=temp[i];
}
}
最后循环或许难以理解为什么不会打乱顺序看图:

我们来看非递归的算法实现:
非递归有点像反向的递归
递归的思路是先分成一段一段的,而非递归是我们直接将数组的每个元素都当做一个序列,然后从跨度为1开始依次合并最后成为排好序的序列
我们看代码 :
package merge2;
//非递归方法
/*
* 非递归的方法和递归的方法有点像反向的
* 思路:我们一开始就将列表中每个元素当成一部分,我们将其依次合并最后返回一个排好序的数组
*
* */
class Merger {
public static void main(String[] args) {
int[] a=new int[]{4,23,15,3,52,1,52,3,542,35,42};
merge_in(a);
for (int i:a){
System.out.println(i);
}
}
public static void merge_in(int[] a){
//从跨度为1开始进行合并,每次合并完再给跨度乘2进行合并直到停止合并
int span =1;
int[] temp=new int[a.length];
while (span<a.length){//停止条件是当跨度大于我们的长度时停止
merge_method(a,temp,span,a.length);
span*=2;
}
}
private static void merge_method(int[] a, int[] temp, int span, int length) {
int index =0;//存储当前的下标
int j;
while(index<length-2*span+1){//如果坐标符合要求,我们就两两归并,这里的条件其实是i+2s-1<=n,
merger(a,temp,index,index+span-1,index+2*span-1); //两两归并
index=index+2*span;//到下一个要归并的两个序列的首序列
}
if (index<length+1-span-1) {//如果剩下的序列还大于一个间隔我们也归并,最后减1是因为从0开始索引
merger(a,temp,index,index+span-1,length-1); //两两归并
}
else //如果只剩单个序列,我们就把它放最后,就算一直他是单个,在最后一次归并时只会剩余它和另一个,
// 然后进行归并通过上面的if语句
for (j=index;j<length;j++){
temp[j]=a[j];
}
}
private static void merger(int[] a, int[] temp, int start, int middle, int end) {
int startRecord=start;
int middleTemp=middle+1;
// int endTemp=end;
int count=0;
while (start<=middle&&middleTemp<=end){//当两个列表都没比较完大小
if (a[start]<=a[middleTemp]){//如果左侧当前下标的值小
temp[count++]=a[start++];//我们将左侧当前下标的值存入temp临时数组
}
else//如果右侧当前下标的值小
temp[count++]=a[middleTemp++];//我们将右侧当前下标的值存入temp临时数组
}
while(start<=middle){//当右边数组全存入而左边的数组未存完
temp[count++]=a[start++];
}
while(middleTemp+1<=end){//当左边数组全存入而右边的数组未存完
temp[count++]=a[middleTemp++];
}
for (int i=0;i<count;i++){
//将相应的tmp的值存入a数组,这
// 里不用担心打乱a的顺序而导致后面的操作无法进行,我们当前的操作都是操作先这层原本在a中区域的下标的
a[startRecord++]=temp[i];
}
}
}排序归并的方法并没有不同,
我们的核心思路:从一开始每次乘2合并知道跨度大于列表长度时就完成了,
merge_method就是用来寻找要组合的下标并进行合并
这个方法有三个情况
第一种:
当前索引的序列能够和下个序列长度进行合并,我们合并

第二种“:
当第一种情况不够,但是剩余的序列长度大于一个跨度,也就是有一个长度为跨度的序列和一个长度不足跨度的序列,当最后时,如果不能直接两两合并,也就是出现了这种情况

第三种:
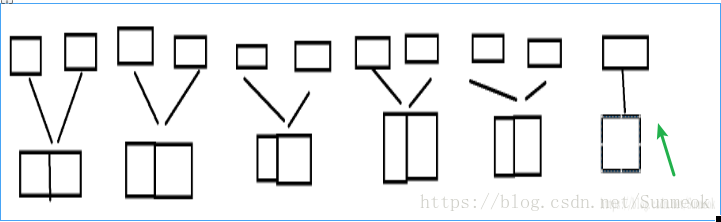
只剩下一个序列,这里的序列不一定为1,注意是不足跨度长度的序列,我们把他放到最后,就算一直没法合并,等到最后时,也会处理。
时间复杂度:稳定算法
递归排序:
它就像一个完全二叉树,因此最外层的递归进行了logn次(完全二叉树的深度为logn),因此递归的时间复杂度为O(logn),里面还要进行排序比对,比对的时间复杂度为O(n),由于比对在递归中嵌套,所以时间复杂度为O(nlogn)
非递归排序:
首先每次乘二找跨度因此这里的时间复杂度为O(logn),然后进行比对的时间复杂度为O(n),而且比对是嵌套在跨度乘二这个方法里的,因为时间复杂度为O(nlogn)