Faster RCNN是Kaming He与RCNN作者共同完成的一项工作,也是目前在目标检测领域非常知名并应用广泛的一种深度学习框架。自2016年被提出以后成为了Detection领域的baseline,众多的算法都是在Faster RCNN的基础上进行的改进,同时介绍结果时也是一Faster RCNN的结果为标准。Faster RCNN实现了RCNNs系列中目标检测的端到端检测的过程。我现在做的工作也是基于Faster RCNN的,我在使用Faster RCNN训练自己的数据时的过程和方法已经记录在我的博客 [深度学习] RCNNs系列(1) Ubuntu下Faster RCNN配置及训练和测试自己的数据方法里,下面我们来详细介绍一下这个深度学习框架。
一、背景介绍
整个RCNNs系列框架对目标检测这个问题的处理流程都是:(1)提出proposal;(2)使用CNN对proposal区域进行特征提取;(3)对proposal的位置区域进行识别回归从而完成检测流程。
经过RCNN,SPPnet和Fast RCNN的发展,目标检测领域已经取得了极大的进步,然而我们都知道深度学习的一个好处也是目标就是端到端的学习。尽管Fast RCNN已经把上面提到的第2、3步进行了整合,然而proposal的提出还是靠selective search,第1步还没有整合到深度学习框架中。我们这里介绍的Faster RCNN的主要贡献就是把proposal的提出也归一化的深度网络中,从而彻底把目标检测问题(不管训练还是测试)用一个端到端的卷积神经网络进行处理。
二、Faster RCNN介绍
Faster RCNN主要由两部分组成:(1)一个用于提出proposal的卷积神经网络(Regiin Proposal Network, RPN);(2)一个Fast RCNN的detector。按照惯例,我们先来看一下Faster RCNN的整体架构,如下图所示:
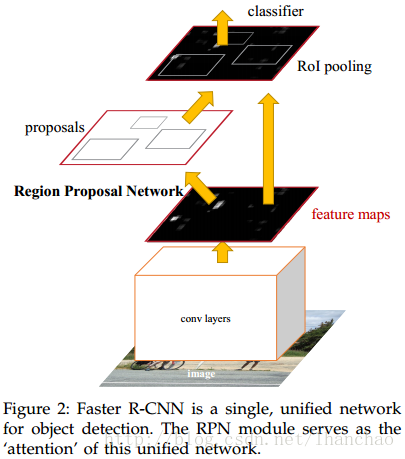
继承自Fast RCNN,Faster RCNN首先用卷积网络对整幅图像进行特征提取,然后使用RPN网络进行proposal的提出,最终将proposal对应的特征图区域放入Fast RCNN的detector中进行分类和回归。
2.1 Region Proposal Networks
RPN网络要做的就是把一幅输入图像转换成若干个矩形框,每个矩形框有一个对应是否是目标物体的分值(objectness score)。其实RPN网络非常的简单,就是在已有的公有卷积层(RPN和后面的detector公用的)上加上了一个n*n(文中n=3)的卷积层,并在该卷积层的基础上有两个1*1的兄弟卷积层(sibling layers,一个classify,一个regression)。
我们都知道目标检测的难点之一在于目标的大小和形状各异,如果使用固定大小的图像或者固定大小的filter其检测效果会很不理想,因此作者首先回顾了一下已有的一些目标检测时proposal的提取方法,如下图所示:
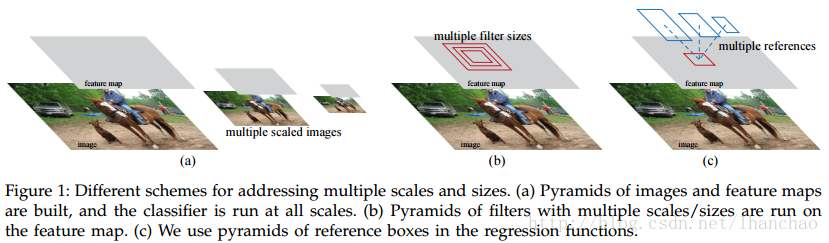
图中a和b是目前已有的方法,即使用不同尺度的图像或者filter以适应不同大小的物体,然而这样做的缺点是需要多次计算,计算要求比较高。图中c是作者提出的anchors,这就是RPN网络的精髓。
2.1.1 Anchors
Anchor机制是Faster RCNN中最出彩的创新点,所以理解Anchor机制是理解整个Faster RCNN中最重要的一部分。这一部分有点绕,我也是反反复复看了好多遍才彻底搞定,下面我们来详细介绍一下Anchor机制。
前面我们说RPN网络的本质就是一个n*n的卷积层后面跟两个1*1的兄弟卷积层,这是RPN网络实现后的结构,而我们需要理解的是RPN网络这样做的意义。
我们都知道卷积层做卷积的时候其实是把filter窗口在上一层的输出上进行以stride为步长的平移,然后在计算,这样的平移做法正好与目标检测领域很早以前应用的滑动窗口技术不谋而合,因此我们可以把
(也可以这样理解,我们确定anchor所做的工作其实是ROIPooling的一个逆过程,ROIPooling中我们是知道确切的目标区域,然后把这个目标区域划分为若干块分别进行Pooling(例如把目标区域划分为
作者在文章中使用了9个anchor,也就是说每个
RPN网络示意图下图所示(以ZF网络为示例):

2.1.2 RPN损失函数
为了训练RPN网络,作者设计了一个多任务的loss:一个是用于表示分类的loss(判断是不是object),另一个是用于表示位置回归的loss。
由于一幅feature map中所有位置都有9个anchor,因此会产生很多的anchor,在训练过程中,需要给产生的anchor打标签以进行监督训练。在训练过程中,作者将产生的anchor中与任意ground truth的IoU(Intersection-over-Union)>0.7的看做正样本,将与任意ground truth的IoU都小于0.3的看做负样本,IoU处于0.3到0.7的样本不参与训练。
多任务的Loss函数如下所示:
公式中
公式中其余参数的设计可以参考论文,我这里就不详细介绍了。
2.1.3 训练RPN
由于一幅图像产生的anchor中正样本数量远远小于负样本的数量,因此在训练RPN网络的时候,是随机挑选图像中生成的256个anchor,其中正样本128个,负样本128个。如果正样本数量总共少于128,则剩余的用负样本代替。
在训练过程只能怪,RPN网络中所有卷积层都使用以0为均值,0.01为标准差的高斯分布初始化参数,前面公有的卷积层(即主干层,如VGG16中conv5_3之前的所有卷积层)直接用imagenet上训练好的模型参数初始化,因此训练RPN其实就是一个微调的过程。作者在PASCAL VOC中进行了80k的迭代训练,其中60k用0.001的学习率,剩余20k用0.0001的学习率。momentum为0.9,weight decay为0.0005。
2.2 Sharing Features for RPN and Fast R-CNN
Fast R-CNN阶段与Fast RCNN一文中基本没有什么区别,论文里没有细说我这里也就不细讲了。这里要讲的是Faster RCNN的创新点,因为Faster RCNN加入了RPN提出proposal的过程,因此他把整个detection过程完全的使用卷积神经网络完成。Faster RCNN的region proposal和detection阶段共用了前面的主干卷积层(例如VGG16中conv1到conv5中的卷积层),这样在计算的过程中可以只用CNN提取一次图像的特征,就可以完成目标的检测。
在这一节,我要讲的主要有两点:
(1)Faster RCNN的RPN和detection阶段的训练过程;
(2)Faster RCNN中RPN的结果是如何应用在detection阶段的。
对于第1点,论文中已经讲的非常的清楚,我这里主要是重复一下:
Step1:RPN网络的训练,用Imagenet上已经训练好的model(这里的model就是平时用来做classification的,如VGG 16等)来初始化公用的卷积层,单独训练RPN网络;
Step2:detection阶段的训练,使用step1中生成的proposals单独训练detection阶段的网络,当然公用的卷积层参数的初始化是直接用Step1中的结果;
Step3:RPN网络的再训练,使用Step2中的训练结果初始化公用卷积层,对RPN网络进行再训练;
Step4:detection阶段的再训练,使用Step3中生成的proposals以及Step3中训练的参数再次初始化公用卷积层,再次单独训练detection阶段。
对于第2点,是论文中没有讲清楚的,也是我最开始一直犯迷糊的一个地方,就是Fast RCNN阶段是怎么样跟RPN阶段链接起来的。其实原理非常简单,RPN阶段最终保留的就是一些anchor(即proposals),现在你不要想anchor是通过什么样的方式生成的,你只需知道最终RPN生成了proposals。把这些proposals利用位置对应,对应到主干卷积层生成的特征图中(例如VGG16中则对应到conv5_3生成的feature map),对该特征图的位置进行ROI Pooling以及后续的一系列识别和回归的操作。
(我最开始想不明白的地方就是,RPN生成的proposal对应的不是特征图中
三、 尾声
论文中其余的部分就是将Faster RCNN在实现时的一些具体参数的设置,我这里就忽略了。我这里主要讲的就是Faster RCNN的创新点,其实整个算法是在RCNN,SPPnet以及Fast RCNN的基础上建立起来的,只要明白了前面的算法,Faster RCNN的新东西也就我上面介绍的几点:(1)RPN提出proposals,使得整个detection是端到端的;(2)anchor机制的引入和理解;(3)RPN的detection阶段共享特征的方式,以及detection阶段和RPN阶段的连接方式。如果有兴趣可以直接阅读论文原文,参照我的博客中的理解,相信应该有更深的体会。
如有问题,欢迎交流。