1.计算&组合
练习:如果函数的参数在代入函数之前并不进行强制求值,pow5(pow5(pow5(pow5(5))))展开后共计算多少次乘法。
解答:设a为5*5*5*5*5,共计算5*5*5次a,即625次乘5;如果强制求值,先算一次a,再去算a的5次方,再算这个结果的5次方,再来一次5次方,总共进行20次乘法。
2.过程
一个再复杂的流程,最终都会由这样的三部分组成:
顺序
分支(选择)
循环
理解递归:
int pow(int x, 1) { return x; }
int pow(int x, 2) { return pow(x, 1) * x; }
int pow(int x, 3) { return pow(x, 2) * x; }
...
int pow(int x, 5) { return pow(x, 4) * x; }int pow(int x, int y) {
int prod=1;
for(int i = 0; i < y; i++) {
prod *= x;
}
return prod;
}int pow(int x, int y) {
return (y == 1) ? x : pow(x, y-1) * x;
}练习:试写出求求斐波那契数函数的循环、递归和尾递归版本的实现
解答:
递归:
int fibo(int n)
{
return n==0||n==1? 1 : fibo(n-1)+fibo(n-2);
}
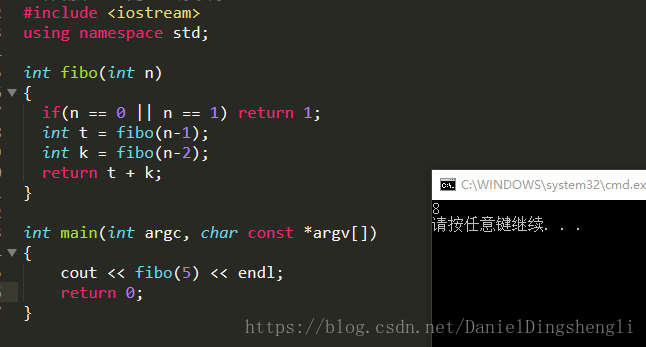
尾递归:
int fibo(int n)
{
if(n == 0 || n == 1) return 1;
int t = fibo(n-1);
int k = fibo(n-2);
return t + k;
}
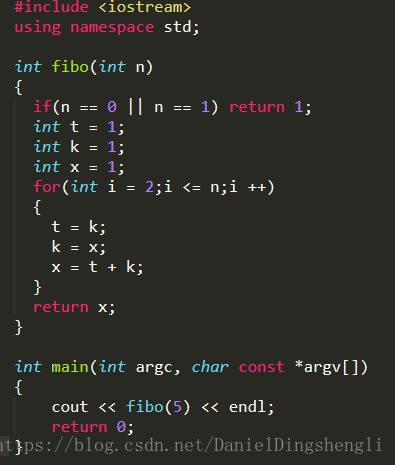
循环:
int fibo(int n)
{
if(n == 0 || n == 1) return 1;
int t = 1;
int k = 1;
int x = 1;
for(int i = 2;i <= n;i ++)
{
t = k;
k = x;
x = t + k;
}
return x;
}
3.编码
当你去规定一种解释二进制序列的方法的时候,其实你就是在定义一种编码。
Unicode
有人想,不如把所有的编码都统一了吧,于是就出现了Unicode。
现行版本的Unicode加入了世界上能够找到的绝大多数语言的符号(嗯,包括emoji),然后将这些符号分类整理,统一编码。于是,在理想情况下,大家都使用Unicode字符集的话,就不会出现乱码的错误了。
Unicode包含的字符量足够的多,于是就要设计比ASCII更充分大的表示方式才能够容纳所有的符号。最初选择的是每个字符使用16位的二进制串来表示,这样的话一个中文字符虽然会超出8位范围之外,还是能够表示得出来,这种方法被称为UTF-1610。
然而不久就发现,符号的数量(就算仅仅是中文字符)远远多于65536个,于是又进一步地扩充到了32位,可以表示到上亿个字符了,目前为止还要很久才会资源枯竭,这种方法类似地,被称为UTF-3211。
然而UTF-32有个很致命的缺点。
对于西方人来说,并没有CJKV地区的人的需求,1个字节就能足够表示他们的符号,而UTF-32硬生生地为了统一,要求字母字符也要用4个字节来表示,这样就让空间整整大了4倍,而且另外3倍的空间完全是浪费掉的,没有任何作用。
但是,为了兼容,没办法
4.序列
界定一个序列,必须要知道的是两点,第一个是他的起始元素,第二个就是这个序列的长度。
一般来说,当这个序列的长度固定不变,并且每个元素是挨在一起的时候,我们常把它叫做array1。
关于array,我非常不喜欢“数组”这个翻译,因为这里面并不一定是数,也有可能是符,所以我会尽可能地使用array来表示它.
串是用序列的最终位置确定整个序列的边界(标记为”\0“)。
语法糖 Syntactic Sugar5,意为使用起来更加方便简单的语法。
迭代器让你忽略不同类型的序列(array,string和list)之间的差异,只利用他们的迭代器做一些公共的操作。
#include <iostream>
template <typename Sequence>
void print(const Sequence& sequence) {
for(auto iter = begin(sequence); iter != end(sequence); iter++)
std::cout << *iter << std::endl;
}练习:最长公共子序列
解答:另文给出
5.引用
你要取一个序列中的特定位置的元素,一种办法是直接取出来,复制给某一个变量。另外一种就是记录一个位置信息,每次要用的时候再去取。
复制——如果我们定义两个变量a和b,其实就是处在内存的不同位置上。当我们选择把a赋值给b的时候,相当于把a所处空间的内容,依次放到b所对应的空间中去。(复制其实可以简单到只是一块块地把字节放到另外一个地方就可以了)。
指针——
using matrix_t = array<array<int, 100>, 100>; // alias to matrix_t
matrix_t matrix {};
matrix_t* matrix_pointer = &matrix;引用——

智能指针——
#include <memory>
std::shared_ptr<std::string> f()
{
auto s = make_shared<string>("Example");
return s;
}
std::shared_ptr<std::string> r = f();
std::cout << *r;
std::string s = *f();智能指针,当然就是比普通的“指针”更智能了。其中非常重要的一个点就是能够自动管理对象的生命周期。shared_ptr允许一个对象被多个指针所持有,只有当所有智能指针都被正常释放以后,才会自动释放该对象的资源。
我们来看上面代码中的f,在其中构造了一个字符串,同时是作为一个智能指针构造的。在f返回的时候,智能指针s被复制作为返回值,然后作为f的局部变量被释放。这个时候,f的返回值(比如变量r)的还是存活的,所以f中构造的字符串继续存活,直到r被正常释放。
shared_ptr通过引用计数的方式来管理对象的生命周期,也即通过统计引用者的数量来决定资源是否需要释放。这种方式简单高效,配合C++能够自动管理对象生命周期的特性,提供了一种灵活而又简便的引用机制。
循环引用——
struct Node {
int value;
shared_ptr<Node> next;
};
void f() {
auto first = make_shared<Node>(1, null_ptr);
auto second = make_shared<Node>(2, first);
first->next = second;
}
f();
//对应的两个Node对象不会被回收。因为两个对象之间相互被引用着,他们各自的引用计数都没有恢复成0,
//所以无法被回收。于是这两个尴尬的对象就又成为了被泄漏的内存资源。6.数据
结构——
房子、汽车、学生,这些概念性的实体(Entity)都有一些自己本身的属性(Property),以及与其他实体之间的关系(Relation)。 我们可以给这些实体的属性和关系贴上一个个标签,把他们与所属的实体之间关联起来。这样就组成了我们现在看到的结构。
当然,他还是数据,但是这些数据通过我们贴上不同的标签以及把他们关联组合,就变成了更加具有实际意义的内容。换句话说,我们给一块二进制内存区赋予了语义(Semantics)。
递归数据结构——
void printList(ListNode* list) {
if(list == nullptr) return;
std::cout << list->value;
printList(list->next);
}构造器——
struct List{
int value;
shared_ptr<List> next;
List(int _value, shared_ptr<List> _next):
value(_value), next(_next) {}
}这里的构造器是说,我接受两个参数(_next, _value),然后用这两个参数去初始化C++结构(struct)中的字段。
make_shared<List>(value, next);递归结构上的操作——
shared_ptr<List> transform(shared_ptr<List> list, std::function<int(int)> transformer) {
//td::function<int(int, int)>,接收两个整数,返回他们的乘方,结果也是整数。
if(list == nullptr) return nullptr;
return make_shared<List>(transformer(list->value), transform(list->next, tranformer))
}
//transform接收一个List和一个int(int)类型的transformer,然后在这个List上递归地对每一个元素执行transformer,得到一个新的结果,然后组成一个新的List。
// => {-1, -2, -3, -4, -5}
transform(make_list(1,2,3,4,5), [](int i) -> int { return -i; });作为数据的过程——
像操作数据一样操作代码。
我们是不是可以定义一些过程,然后对这个过程进行调用,去做一些复杂的计算?同时,当我们需要进一步利用这些过程的时候,可以把它们直接当成数据拿来用的。有些时候我们可能并不只是需要拿已经就有的过程来简单地做抽象,所以更有必要提供一种方式让我们随时都能够创建一个过程。于是C++给我们提供了Lambda表达式。
7.状态
程序中的很多数据往往是在不停地变化的,比如时间,比如与用户的交互,又比如,一些程序运行中产生和保存的数据。当一些可变的数据或者对象是发生改变的时候,我们就可以说它们从一个状态转换到了另一个状态。
8.闭包
闭包就是能够读取其他函数内部变量的函数。
闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
9.并发
并发,在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
并行:当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。