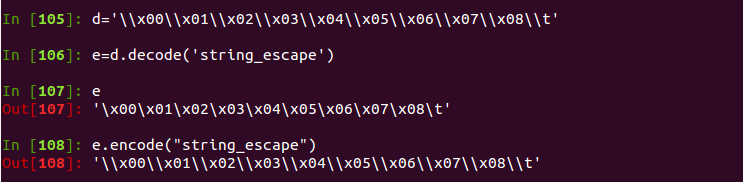
Python的编码问题基本是每个新手都会遇到的坎,但只要完全掌握了就跳过了这个坑,万变不离其中,这不最近我也遇到了这个问题,来一起看看吧。
事情的起因是review同事做的一个上传功能,看下面一段代码,self.fp是上传的文件句柄
fpdata = [line.strip().decode('gbk').encode('utf-8').decode('utf-8') for line in self.fp]
data = [''.join(['(', self.game, ',', ','.join(map(lambda x: "'%s'" % x, d.split(','))), ')']) for d in fpdata[1:]]这段代码暴露了2个问题
1.默认编码使用gbk,为什么不用utf8?
2..encode(‘utf-8’).decode(‘utf-8’)完全没有必要,decode(‘gbk’)之后就已经是unicode了
我建议上传文本编码为utf8,于是代码变成这样?
fpdata = [line.strip() for line in self.fp if line.strip()]
data = [''.join(['(', self.game, ',', ','.join(map(lambda x: "'%s'" % x, d.split(','))), ')']) for d in fpdata[1:]]可测试时报UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe4 in position 0: ordinal not in range(128),这个异常估计新手看到很头疼,这是什么意思呢?
就是说:在将ascii字符串decode为unicode时碰到了oxe4这个比特,这不在ascii的范围内,所有decode错误。
交代一下项目背景,我们用Python2.7,这是django工程,self.game是unicode对象,明白人一看就是sys.setdefaultencoding的问题,其实就是下面这个问题
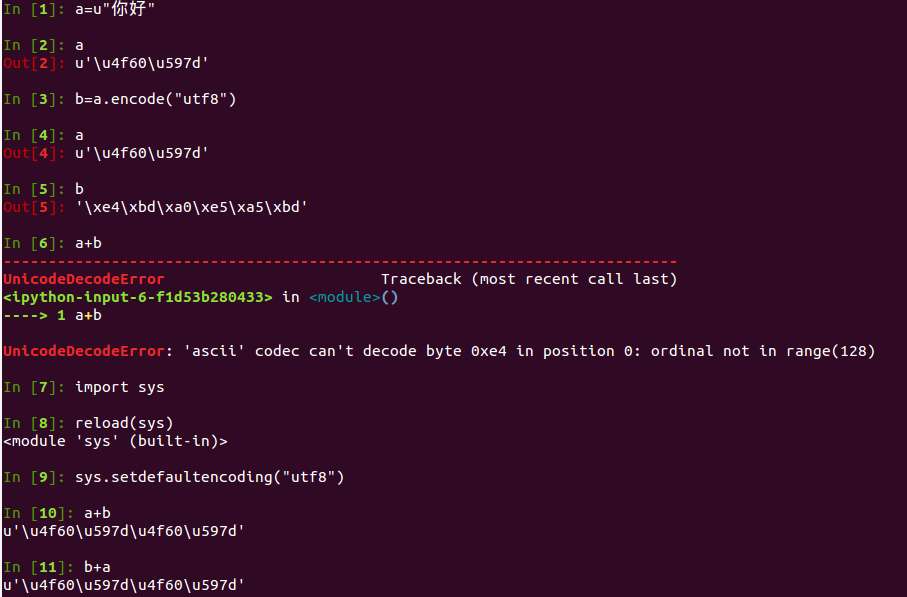
哎呀,可我明明在settings.py中设置默认编码了呀,查看了一下,才发现闹了个笑话

看看到底发生了什么?由于fpdata都是utf8字符串,而self.game是unicode对象,字符串join时会将utf8字符串解码为unicode对象,但系统不知道你是utf8编码,默认使用ascii去解码,这出错也就不足为奇了。
这也是为什么在碰到编码问题时,老手建议增加sys.setdefaultencoding(“utf8”)操作,但为什么要加这么一个操作呢?我们从底层看看发生了什么?
当字符串连接unicode对象时,也就是a+b时,会调用PyString_Concat
# stringobject.c
void
PyString_Concat(register PyObject **pv, register PyObject *w)
{
register PyObject *v;
if (*pv == NULL)
return;
if (w == NULL || !PyString_Check(*pv)) {
Py_CLEAR(*pv);
return;
}
v = string_concat((PyStringObject *) *pv, w);
Py_DECREF(*pv);
*pv = v;
}
static PyObject *
string_concat(register PyStringObject *a, register PyObject *bb)
{
register Py_ssize_t size;
register PyStringObject *op;
if (!PyString_Check(bb)) {
if (PyUnicode_Check(bb))
return PyUnicode_Concat((PyObject *)a, bb);
if (PyByteArray_Check(bb))
return PyByteArray_Concat((PyObject *)a, bb);
PyErr_Format(PyExc_TypeError,
"cannot concatenate 'str' and '%.200s' objects",
Py_TYPE(bb)->tp_name);
return NULL;
}
...
}如果检测到b是unicode对象,会调用PyUnicode_Concat
PyObject *PyUnicode_Concat(PyObject *left,
PyObject *right)
{
PyUnicodeObject *u = NULL, *v = NULL, *w;
/* Coerce the two arguments */
u = (PyUnicodeObject *)PyUnicode_FromObject(left);
v = (PyUnicodeObject *)PyUnicode_FromObject(right);
w = _PyUnicode_New(u->length + v->length);
Py_DECREF(v);
return (PyObject *)w;
}
PyObject *PyUnicode_FromObject(register PyObject *obj)
{
if (PyUnicode_Check(obj)) {
/* For a Unicode subtype that's not a Unicode object,
return a true Unicode object with the same data. */
return PyUnicode_FromUnicode(PyUnicode_AS_UNICODE(obj),
PyUnicode_GET_SIZE(obj));
}
return PyUnicode_FromEncodedObject(obj, NULL, "strict");
}由于a不是unicode对象会调用PyUnicode_FromEncodedObject将a转换为unicode对象,传递的编码是NULL
PyObject *PyUnicode_FromEncodedObject(register PyObject *obj,
const char *encoding,
const char *errors)
{
const char *s = NULL;
Py_ssize_t len;
PyObject *v;
/* Coerce object */
if (PyString_Check(obj)) {
s = PyString_AS_STRING(obj);
len = PyString_GET_SIZE(obj);
}
/* Convert to Unicode */
v = PyUnicode_Decode(s, len, encoding, errors);
return v;
}
PyObject *PyUnicode_Decode(const char *s,
Py_ssize_t size,
const char *encoding,
const char *errors)
{
PyObject *buffer = NULL, *unicode;
if (encoding == NULL)
encoding = PyUnicode_GetDefaultEncoding();
/* Shortcuts for common default encodings */
if (strcmp(encoding, "utf-8") == 0)
return PyUnicode_DecodeUTF8(s, size, errors);
else if (strcmp(encoding, "latin-1") == 0)
return PyUnicode_DecodeLatin1(s, size, errors);
else if (strcmp(encoding, "ascii") == 0)
return PyUnicode_DecodeASCII(s, size, errors);
/* Decode via the codec registry */
buffer = PyBuffer_FromMemory((void *)s, size);
if (buffer == NULL)
goto onError;
unicode = PyCodec_Decode(buffer, encoding, errors);
return unicode;
}我们看到当encoding是NULL时,encoding是PyUnicode_GetDefaultEncoding(),其实这个就是我们sys.getdefaultencoding()的返回值,Python默认就是ascii
static char unicode_default_encoding[100 + 1] = "ascii";
const char *PyUnicode_GetDefaultEncoding(void)
{
return unicode_default_encoding;
}这里unicode_default_encoding是个静态变量,且分配了足够的空间让你指定不同的编码,估计100个字符肯定是够了
我们在看看sys模块的getdefaultencoding和setdefaultencoding
static PyObject *
sys_getdefaultencoding(PyObject *self)
{
return PyString_FromString(PyUnicode_GetDefaultEncoding());
}
static PyObject *
sys_setdefaultencoding(PyObject *self, PyObject *args)
{
if (PyUnicode_SetDefaultEncoding(encoding))
return NULL;
Py_INCREF(Py_None);
return Py_None;
}PyUnicode_SetDefaultEncoding不用想也知道设置unicode_default_encoding数组就可以了,Python用的是strncpy
int PyUnicode_SetDefaultEncoding(const char *encoding)
{
PyObject *v;
/* Make sure the encoding is valid. As side effect, this also
loads the encoding into the codec registry cache. */
v = _PyCodec_Lookup(encoding);
if (v == NULL)
goto onError;
Py_DECREF(v);
strncpy(unicode_default_encoding,
encoding,
sizeof(unicode_default_encoding) - 1);
return 0;
onError:
return -1;
}之前我们在sys.setdefaultencoding(“utf8”)时是reload(sys)的,这是因为在Python site.py中有这么一个操作
if hasattr(sys, "setdefaultencoding"):
del sys.setdefaultencoding当然你完全可以定制site.py,修改setencoding,使用locale的设置,也就是将if 0修改为if 1。一般windows的设置locale编码为cp936,服务器一般都是utf8
def setencoding():
"""Set the string encoding used by the Unicode implementation. The
default is 'ascii', but if you're willing to experiment, you can
change this."""
encoding = "ascii" # Default value set by _PyUnicode_Init()
if 0:
# Enable to support locale aware default string encodings.
import locale
loc = locale.getdefaultlocale()
if loc[1]:
encoding = loc[1]
if 0:
# Enable to switch off string to Unicode coercion and implicit
# Unicode to string conversion.
encoding = "undefined"
if encoding != "ascii":
# On Non-Unicode builds this will raise an AttributeError...
sys.setdefaultencoding(encoding) # Needs Python Unicode build !所以Python的编码是不难的,
要想玩转Python的编码你需要知道
1.unicode与utf8,gbk的区别,以及unicode与具体编码的转换
2.字符串与unicode连接时会转换为unicode, str(unicode)会转换为字符串
3.当不知道具体编码会使用系统默认编码ascii,可通过sys.setdefaultencoding修改
如果能解释下面现象应该就能玩转Python让人讨厌的编码问题
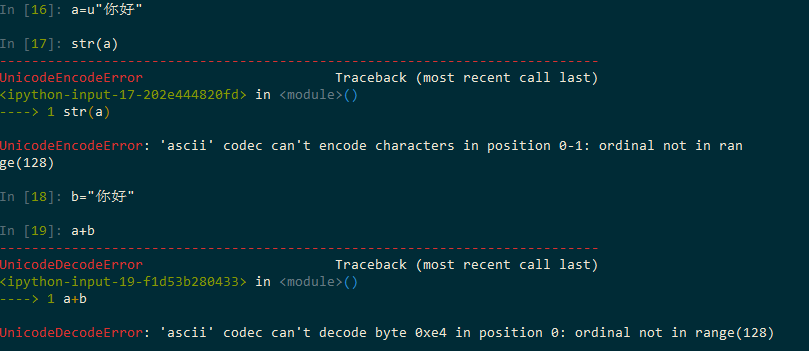
当然这里面还有坑,比如经常在群里看到已经sys.setdefaultencoding(“utf8”)了,但print时候还是报错,这个其实是print造成的,print会根据sys.stdout.encoding再转一次码。
解决办法:
export LANG="en_US.UTF-8"当然也听到不少朋友建议不要用sys.setdefaultencoding,这会让你遇到不少坑,对这点我是持保留意见的,军刀在手就看各位怎么用了,是杀敌1000自损800还是所向披靡。
当然这的确有坑,比如a==b,c是一个字典,c[a]可能并不等于c[b],因为==会转换编码,但字典并不会。
这里还要提一下下面这个东西 https://docs.python.org/2/library/codecs.html
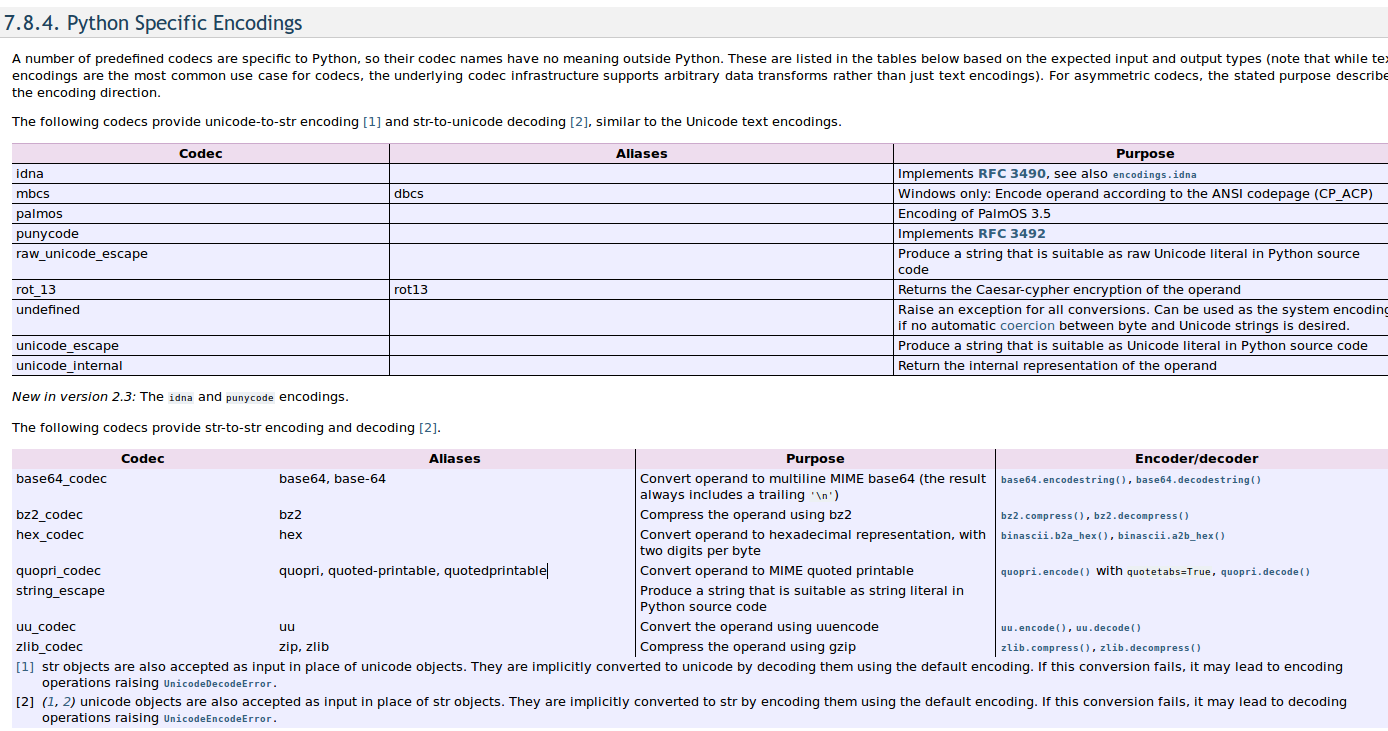
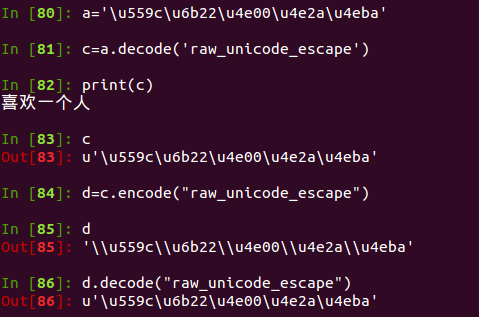
unicode_eacape就是提供unicode和string的转换
我们看到a已经是unicode表示了,但我们需要的是python中unicode字符,所以decode(‘raw_unicode_escape’),还比如写接口返回的json字符串
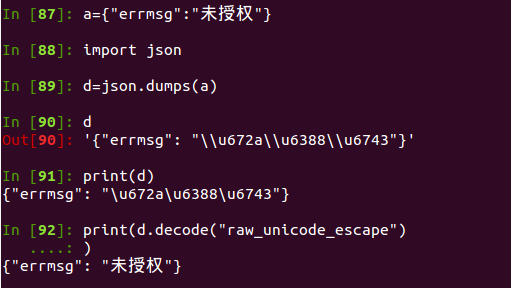
string_escape是提供string和python中字符串字面量之间的转换。