selenium是一套比较火的开源自动化测试框架
selenium中元素定位有八种方式:
- id定位:
- class定位
- Name定位
- Tagname定位
- xpath定位
- css定位
- linkText定位
- partial_link定位
以上每种方式都有find_element()方法与之对应,下面代码中有示例
下面以代码实例展示,python版本为3.4.3,请求网页为新浪财经网
(1)前期导入模块
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
from selenium.webdriver.support import expected_conditions as EC # #该模块包含一些判断条件,比如用来判断元素是否存在
from selenium.webdriver.common.by import By
from time import sleep(2)定义url并获取url内容
url = "http://finance.sina.com.cn/money/globalindex/" #新浪财经环球股指
browser = webdriver.Firefox()
browser.get(url)(3)8种定位方式
1.id定位
print("id定位:获取上证指数行情")
element = browser.find_element_by_id("hq_sh000001")
#element = browser.find_element("id", "hq_sh000001")
print(element.text)结果为:
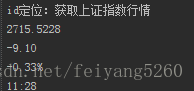
2.class定位
print("class定位:获取意见反馈")
element = browser.find_element_by_class_name("text_info")
#element = browser.find_element("class name", "text_info")
print(element.text)结果为:

3.name定位
print("name定位:获取description中属性为content的值")
element = browser.find_element_by_name("description")
#element = browser.find_element("name", "description")
print(element.get_attribute("content"))结果为:

4.tagname定位
print("tagname定位:获取标签input中属性为name的值")
element = browser.find_element_by_tag_name("input")
#element = browser.find_element("tag name", "input")
print(element.get_attribute("name"))结果为:

5.xpath定位
print("xpath定位:获取英国富时100指数最新价")
sleep(2) #等待一段时间,以防未加载完成,从而报错
locator = (By.XPATH, "/html/body/div[5]/div[5]/div[1]/div[1]/dl/dd[2]/div/ul/li[1]")
# WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息)
#这里超时时长和sleep()等待时常不同,在超时时间以内,只要判断数据已加载,便继续进行下一步操作
element = WebDriverWait(browser, 5).until(EC.presence_of_element_located(locator)) # 显式等待,等待的时间是固定的,这里等待5s
#element = browser.find_element_by_xpath("/html/body/div[5]/div[5]/div[1]/div[1]/dl/dd[2]/div/ul/li[1]")
#element = browser.find_element("xpath", "/html/body/div[5]/div[5]/div[1]/div[1]/dl/dd[2]/div/ul/li[1]")
print(element.text)结果为:

6.css定位
print("css定位:获取英国富时100指数最新价")
element = browser.find_element_by_css_selector("#hq_b_UKX > ul:nth-child(1) > li:nth-child(1)")
#element = browser.find_element("css selector", "#hq_b_UKX > ul:nth-child(1) > li:nth-child(1)")
print(element.text)结果为:

7.linkText定位
print("linkText定位:点击打开新浪首页")
element = browser.find_element_by_link_text("新浪首页")
#element = browser.find_element("link text", "新浪首页")
element.click() #会点击进入新浪首页8.partial_link定位:同上,只不过只需要局部匹配
print("partial_link定位:点击打开新浪首页")
element = browser.find_element_by_partial_link_text("新浪首")
#element = browser.find_element("partial link text", "新浪首")
element.click() #会点击进入新浪首页(4)关闭并退出浏览器
browser.close()
browser.quit()总结:
1. 当页面元素有id属性时,最好尽量用id来定位。但由于现实项目中很多程序员其实写的代码并不规范,会缺少很多标准属性,这时就只有选择其他定位方法。
2. xpath很强悍,但定位性能不是很好,所以还是尽量少用。如果确实少数元素不好定位,可以选择xpath或cssSelector。
3. 当要定位一组元素相同元素时,可以考虑用tagName或name。
4. 当有链接需要定位时,可以考虑linkText或partialLinkText方式。