进行Web页面自动化测试,对页面上的元素进行定位和操作是核心。而操作又是以定位为前提的,因此,对页面元素的定位是进行自动化测试的基础。
页面上的元素就像人一样,有各种属性,比如元素名字,元素id,元素属性(class属性,name属性)等等。webdriver就是利用元素的这些属性来进行定位的。(本文以百度首页为例)
- Friebug
- Chrome开发者工具(F12)
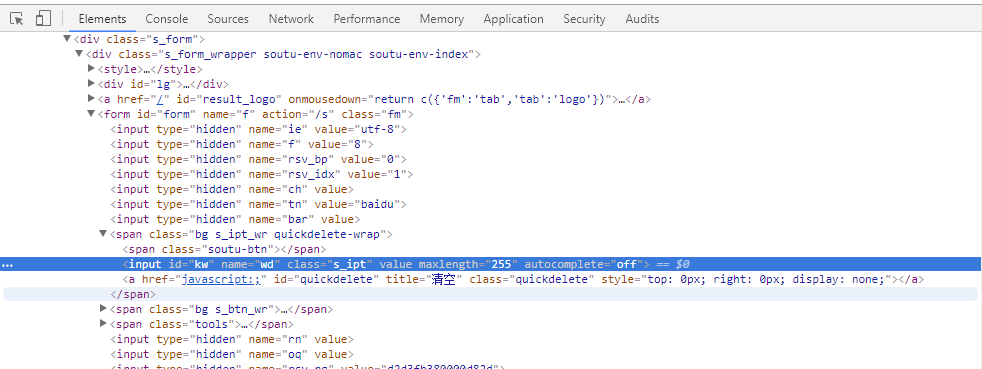
这样可以成功的查看元素的属性。
图中显示输入框的属性为:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
selenium的webdriver提供了八种基本的元素定位方法,前面六种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
1.通过id定位:find_element_by_id()
从上面的元素属性中,可以看到有个id属性:id="kw",所以可以通过它的id属性单位到这个元素。定位到搜索框后,可以用send_keys()方法输入内容到搜索框。
eg:driver.find_element_by_id("kw").send_keys("by_id")
2.通过name定位:find_element_by_name()
同理:name属性:name="wd",通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
eg:driver.find_element_by_name("wd").send_keys("by_name")
3.通过class定位:find_element_by_class_name()
同理:class属性:class="s_ipt",通过它的class属性单位到这个元素。
eg:driver.find_element_by_class_name("s_ipt").send_keys("by_class_name")
4.通过tag定位:find_element_by_tag_name()
从元素属性中,可以看到每个元素都有tag(标签)属性,就是最前面的input
在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错
eg:driver.find_element_by_tag_name("input").send_keys("by_tag_name")
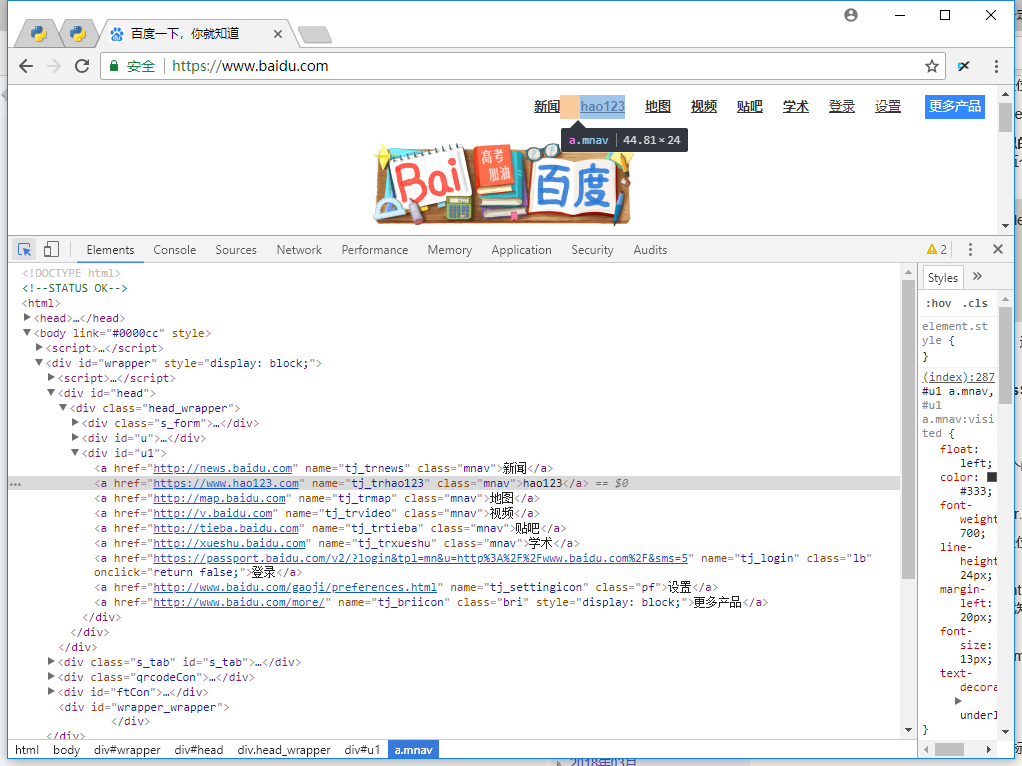
通过上图可以获取超链接hao123的属性:<a href="https://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
5.通过link定位:find_element_by_link_text()
对于超链接的元素我们通过超链接上的文字信息来定位元素。并用方法click()点击进入链接。
eg:driver.find_element_by_link_text("hao123").click()
6.通过partial_link定位:find_element_by_partial_link_text()
这个方法是上一个方法的扩展。当你不能准确知道超链接上的文本信息或者只想通过一些关键字进行匹配时,可以使用这个方法来通过部分链接文字进行匹配。
eg:driver.find_element_by_partial_link_text("ao123").click()
7.通过xpath定位:find_element_by_xpath()
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。
在正式开始使用XPath进行定位前,我们先了解下什么是XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
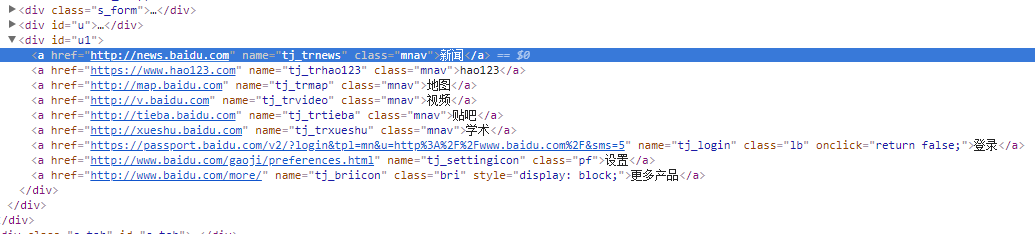
我们以图中HTML代码为例,要引用对应的对象,XPath语法如下:

Xpath功能很强大,所以也可以写得更加复杂一些。
8.通过css定位:find_element_by_css_selector()
# 第一步导入需要的模块 from selenium import webdriver import time # 第二步打开浏览器 driver = webdriver.Chrome() # 第三步打开百度 driver.get("http://www.baidu.com") # 1. 操作浏览器对象-id driver.find_element_by_id("kw").send_keys("by_id") time.sleep(1) # 清空文本框 driver.find_element_by_id("kw").clear() # 2. 操作浏览器对象-name driver.find_element_by_name("wd").send_keys("by_name") time.sleep(1) driver.find_element_by_id("kw").clear() # 3. 操作浏览器对象-class_name driver.find_element_by_class_name("s_ipt").send_keys("by_class_name") time.sleep(1) driver.find_element_by_id("kw").clear() driver.refresh() # 4. 操作浏览器对象-tag_name, tag同名的很多,运行肯定报错,所以注释掉不运行。 #driver.find_element_by_tag_name("input").send_keys("by_tag_name") # 5. 操作浏览器对象-link_text driver.find_element_by_link_text("hao123").click() time.sleep(1) # 回退到上一个页面 driver.back() time.sleep(1) # 6. 操作浏览器对象-partial_link_text driver.find_element_by_partial_link_text("ao123").click() time.sleep(1) driver.back() time.sleep(1) # 7. 操作浏览器对象-xpath driver.find_element_by_xpath(".//*[@id='kw']").send_keys("by_xpath") time.sleep(1) driver.find_element_by_id("kw").clear() # 8. 操作浏览器对象-xpath driver.find_element_by_css_selector("#kw").send_keys("by_css_selector") time.sleep(1) # 退出, close用于关闭当前窗口,quit用于结束进程,关闭所有窗口,当测试结束时,要用quit driver.close() driver.quit()