Pool
sync.Pool的作用是存储那些被分配了但是没有被使用,而未来可能会使用的值,以减小垃圾回收的压力,Pool不太适合做永久保存的池,更适合做临时对象池。在Go语言的程序设计中,这是为了缓解高并发是垃圾回收的压力。在并发程序中,sync.Pool会维持一个channel队列,这个队列中的资源的个数是不固定的,并发的goroutine可在该队列中获取资源。我们不知道Pool中资源回收的时机。。。
有两个需要注意的要点:
一定要定义初始化函数,否则如果Pool是空的话,会返回
nil。如果队列中没有可用的资源了,但是此时有新的
goroutine需要申请新的资源,那么系统会给该goroutine重新分配新的资源
初始化方法:
type Pool struct {
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
// contains filtered or unexported fields
}我们需要自定义一个初始化的函数,当池中为空时,可以生成一个新的数据。
两个方法:
func (p *Pool) Get() interface{}:从池中获取数据,如果数据不存在,则新建一个func (p *Pool) Put(x interface{}):把数据放入池中
Cond
该模型可以理解成生产者和消费者模式的中的wait和signal操作,或者是读写者模式的操作。sync.Cond本身封装了这些条件。下面给出主要的几个函数:
func NewCond(l Locker) *Cond:用于创建条件,根据实际情况传入sync.Mutex或者sync.RWMutex的指针,一定要是指针,否则会发生复制导致锁的失效func (c *Cond) Broadcast():唤醒条件上的所有goroutinefunc (c *Cond) Signal():随机唤醒等待队列上的goroutine,随机的方式效率更高func (c *Cond) Wait():挂起goroutine的操作。一般的模式为:c.L.Lock() for !condition() { c.Wait() } ... make use of condition ... c.L.Unlock()在这里解释一下加锁的行为:加锁说明是临界区,以生产者消费者模式为例,此时的进程相当于获得了缓冲池,那么可定同时只能有一个生产者或者消费者获得,这必然是需要加锁的;如果不满足条件,那么这个线程处于阻塞状态,我们在这里直接使用
wait进行挂起操作。。。。
生产者消费者模式
假设有3个生产者,2个消费者。有一个缓冲池,缓冲池同时只能由一个参与者获得,缓冲池的大小是3。对于生产者和消费者的理解上,因为是源源不断的生产和消费的,所以在生产和消费的函数上需要添加死循环,死循环的思路来自这个博客。因为对数据池的操作是临界区,也就是同时只能有一个生产者或者消费者获得,所以一定要加锁处理。
代码:
package main
import (
"fmt"
"math/rand"
"runtime"
"sync"
"time"
)
// 循环队列
type queue struct {
length int // 最大容量
num int // 元素的个数
head int // 队头指针
end int // 队尾指针
buffer []int // 存放元素的缓冲区
}
func (q *queue) isEmpty() bool {
if q.num == 0 {
return true
}
return false
}
func (q *queue) isFull() bool {
if q.num == q.length {
return true
}
return false
}
func (q *queue) push(i int) bool {
if q.num == q.length {
return false
} else {
q.buffer[q.end] = i
q.num++
q.end = (q.end + 1) % q.length
return true
}
}
func (q *queue) pop() bool {
if q.num == 0 {
return false
} else {
q.head = (q.head + 1) % q.length
q.num--
return true
}
}
func (q *queue) front() int {
return q.buffer[q.head]
}
// 生产者
type producer struct {
id int // 生产者编号
}
// 生产者模型
func (p *producer) produce(q *queue, cond *sync.Cond) {
// 源源不断地生产,使用死循环模拟
for {
cond.L.Lock()
for q.isFull() { // 缓冲区满了,需要阻塞
fmt.Printf("Producer %d wait...\n", p.id)
cond.Wait()
}
// 随机0-2秒的时间,用于模式生产过程
t := rand.Intn(2000)
time.Sleep(time.Duration(t) * time.Millisecond)
fmt.Printf("proceduer %d produce %d\n", p.id, t)
q.push(t) // 加入缓冲池
cond.L.Unlock()
cond.Signal()
}
}
// 消费者
type consumer struct {
id int // 消费者编号
}
func (c *consumer) consume(q *queue, cond *sync.Cond) {
// 源源不断地消费,使用死循环模拟
for {
cond.L.Lock()
for q.isEmpty() {
fmt.Printf("Consumer %d wait...\n", c.id)
cond.Wait()
}
p := q.front()
q.pop()
// 随机0-2秒的时间,用于模式生产过程
t := rand.Intn(2000)
time.Sleep(time.Duration(t) * time.Millisecond)
fmt.Printf("Consumer %d consume %d\n", c.id, p)
cond.L.Unlock()
cond.Signal()
}
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU())
Cond := sync.NewCond(&sync.Mutex{}) // 注意取地址符号
Q := queue{3, 0, 0, 0, make([]int, 3)}
// 3个生产者
for i := 1; i <= 3; i++ {
p := &producer{i}
go p.produce(&Q, Cond)
}
// 2个消费者
for i := 1; i <= 2; i++ {
c := &consumer{i}
go c.consume(&Q, Cond)
}
<-time.After(20 * time.Second) // 设置20秒的定时
}运行结果:
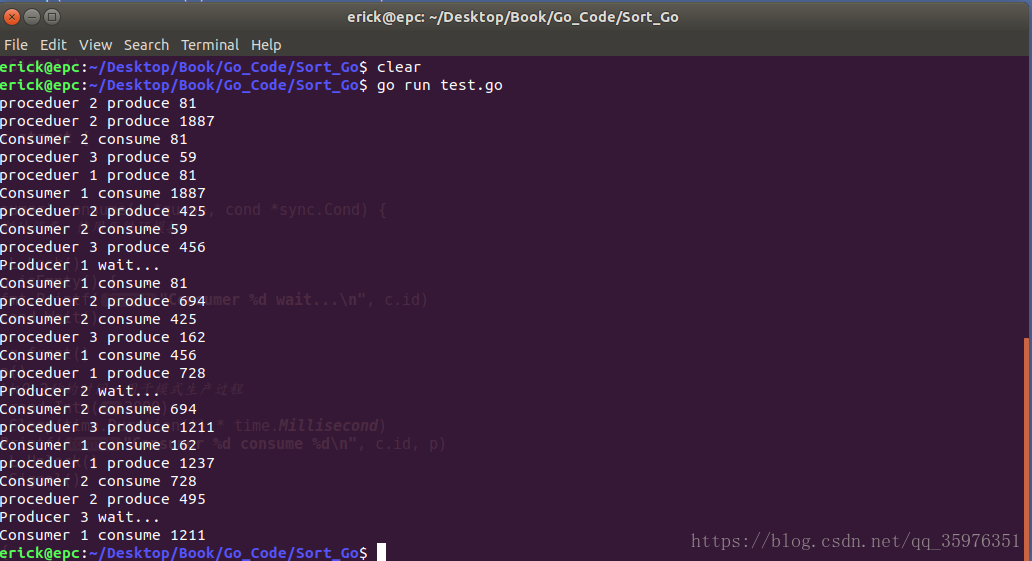
一些小的缺陷:上述的代码中,把生产时间也放在了临界区中了,这不太符合实际的情况;实际情况是只要放完了就立刻进行生产,然后等待放入,而不是等待到拿到临界区的资格后才进行生产。因为这只是一个实验代码,因此可以先忽略这一点。
小结:
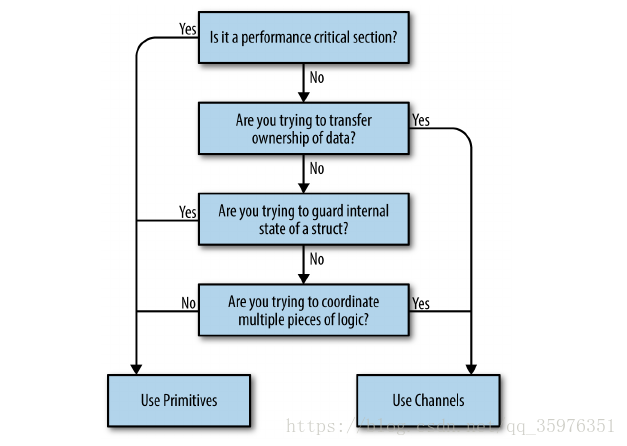
这里的代码用于解释一些包的使用方式,真正实际的编程环境中,根据需要合理的选择channel方式或者sync的方式,一般使用的策略是: