前言:
上篇文章:《新浪微博爬虫分享(一天可抓取 1300 万条数据)》、《新浪微博分布式爬虫分享》
Github地址:SinaSpider
Q群讨论:
更新完《QQ空间爬虫分享(2016年11月18日更新)》,现在将新浪微博爬虫的代码也更新一下吧。
这次主要对爬虫的种子队列和去重策略作了优化,并更新了Cookie池的维护,只需拷贝代码即可实现爬虫分布式扩展,适合大规模抓取。
使用说明:
- 需要安装的软件:Python2、Redis、MongoDB; 需要安装的Python模块:scrapy、requests、lxml。
- 进入cookies.py,填入你的微博账号(已有两个账号示例)。
- 进入settings.py,如果你填入的账号足够多,可以将
DOWNLOAD_DELAY = 10和CONCURRENT_REQUESTS = 1注释掉。另外可以修改存放种子和去重队列的机器,可以存放在两台不同的机器上面。 - 运行launch.py启动爬虫,也可在命令行执行
scrapy crawl SinaSpider(Linux只能采用后者)。 - 分布式扩展:将代码拷贝到一台新机器上,运行即可。注意各子爬虫要共用一个去重队列,即将settings.py里面的
FILTER_HOST设成同一台机的IP。
代码说明:
- 爬虫基于scrapy+redis架构进行开发、优化。
- 爬虫支持断点续爬。
- 非常简易地,便可实现分布式扩展。
- 使用Redis的“位”进行去重,1G的内存可满足80亿个用户ID的瞬间去重。
- 将种子优化到不足40个字符,大大降低了Redis的内存消耗,也提高了各子爬虫从Redis取种子的速度。
- 维护了一个Cookie池,各子机器共用一个Cookie池,断点续爬不会重复获取Cookie,当某个Cookie失效时会自动更新。
注:本项目用代码提交请求进行登录,不会遇到验证码。但是有个情况:如果一次性获取几十个Cookie,新浪会检测到你的IP异常(大约多久会被检测出来?以前是一分钟左右,现在好像几十秒,我们就用这几十秒登陆完所有账号,放心 代码登录很快的),大约十个小时后会给你的IP恢复正常。IP被检测为异常会怎样?不会影响爬虫的抓取,只是你再登录账号时会被要求输入验证码,日志如[Sina_spider3.cookies] WARNING: Failed!( Reason:为了您的帐号安全,请输入验证码 )。
如果我的账号还没登录完就出现这种情况怎么办?可以先将爬虫停了,机器换个IP继续获取Cookie,放心 已获取到Cookie的账号会自动跳过。当然如果你不喜欢受这个限制,可以用打码平台或着自己写个程序把验证码搞定。其实只是第一次启动爬虫才是需要获取那么多Cookie,之后只有等哪个Cookie失效了才会去更新。
数据说明:
用户发表的微博:
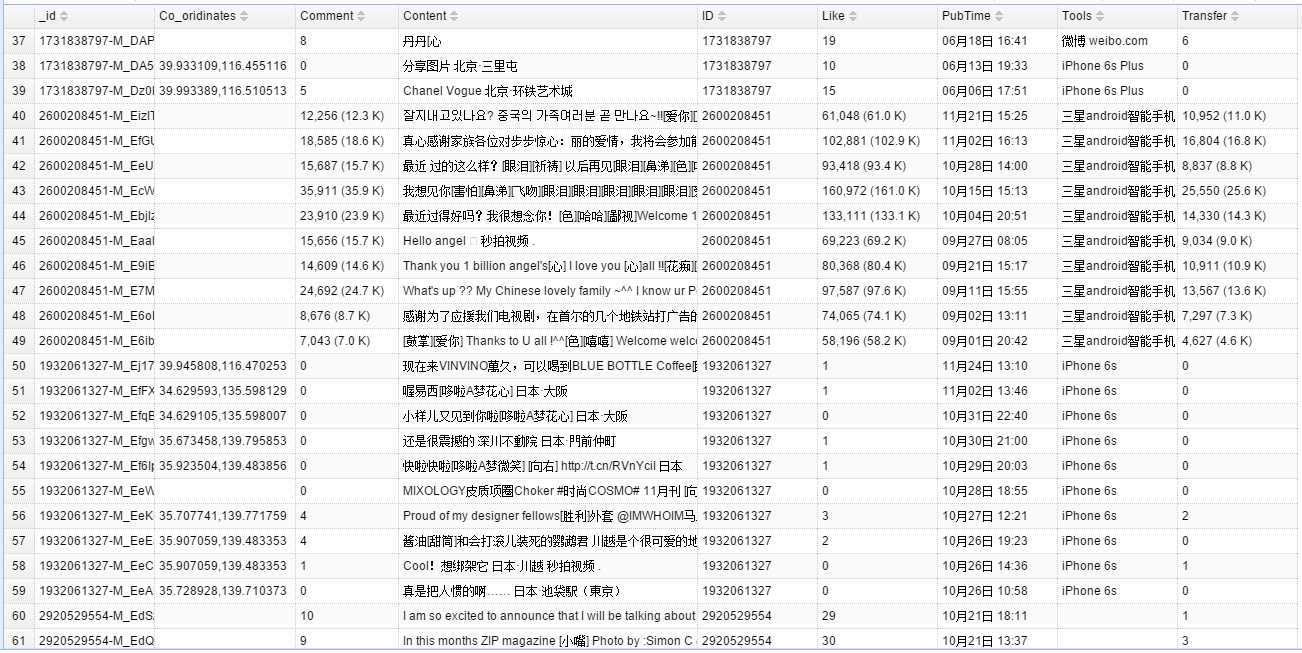
_id : 用户ID-微博ID
ID : 用户ID
Content : 微博内容
PubTime : 发表时间
Co_oridinates : 定位坐标
Tools : 发表工具/平台
Like : 点赞数
Comment : 评论数
Transfer : 转载数
用户的个人信息:
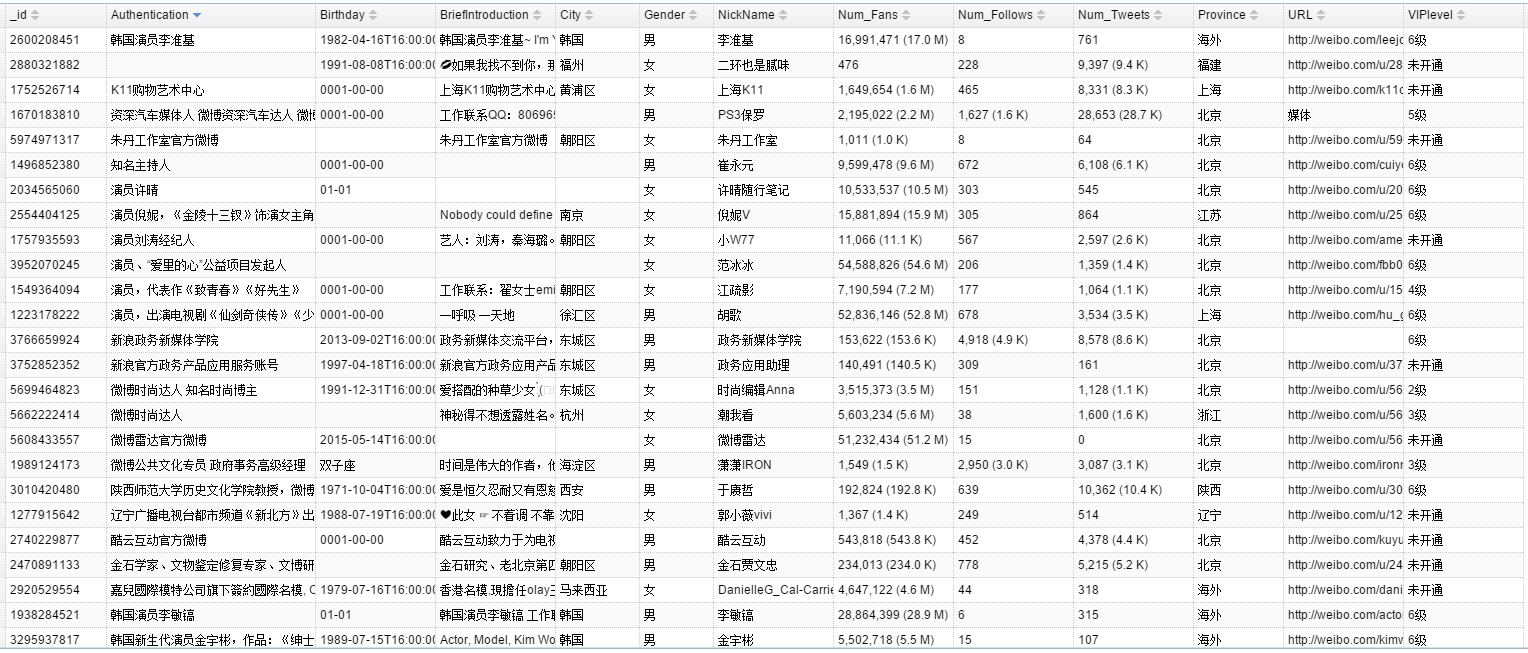
_id: 用户ID
NickName: 昵称
Gender: 性别
Province: 所在省
City: 所在城市
BriefIntroduction: 简介
Birthday: 生日
Num_Tweets: 微博数
Num_Follows: 关注数
Num_Fans: 粉丝数
SexOrientation: 性取向
Sentiment: 感情状况
VIPlevel: 会员等级
Authentication: 认证
URL: 首页链接
2016年12月15日更新:
有人反映说爬虫一直显示爬了0页,没有抓到数据。
- 把settings.py里面的LOG_LEVEL = ‘INFO’一行注释掉,使用默认的”DEBUG”日志模式,运行程序可查看是否正常请求网页。
- 注意程序是有去重功能的,所以要清空数据重新跑的话一定要把redis的去重队列删掉,否则起始ID被记录为已爬的话也会出现抓取为空的现象。清空redis数据 运行cleanRedis.py即可。
- 另外,微博开始对IP有限制了,如果爬的快 可能会出现403,大规模抓取的话需要加上代理池。
2017年3月23日更新:
微博从昨天下午三点多开始做了一些改动,原本免验证码获取Cookie的途径已经不能用了。以前为了免验证码登录,到处找途径,可能最近爬的人多了,给封了。
那么就直面验证码吧,走正常流程登录,才没那么容易被封。此次更新主要在于Cookie的获取途径,其他地方和往常一样(修改了cookies.py,新增了yumdama.py)。
加了验证码,难度和复杂程度都提高了一点,对于没有编程经验的同学可能会有一些难度。
验证码处理主要有两种:手动输入和打码平台自动填写(手动输入配置简单,打码平台输入适合大规模抓取)。
手动方式流程:
1. 下载PhantomJS.exe,放在python的安装路径(适合Windows系统,Linux请找百度)。
2. 运行launch.py启动爬虫,中途会要求输入验证码,查看项目路径下新生成的aa.png,输入验证码 回车,即可。
打码方式流程:
1. 下载PhantomJS.exe,放在python的安装路径。
2. 安装Python模块PIL(请自行百度,可能道路比较坎坷)
3. 验证码打码:我使用的是 http://www.yundama.com/ (真的不是打广告..),将username、password、appkey填入yumdama.py(正确率挺高,weibo.cn正常的验证码是4位字符,1元可以识别200个)。
4. cookies.py中设置IDENTIFY=2,运行launch.py启动爬虫即可。
2017年4月5日更新:
微博从4月1日开始对IP限制更严了,很容易就403 Forbidden了,解决的办法是加代理。从16年12月更新代码后爬微博的人多了许多,可能对weibo.cn造成了挺多无效访问。所以此次代码就不更新了,过滤一些爬虫新手,如果仍需大量抓取的,在middleware.py中加几行代码,带上代理就行了,难度也不大。没加代理的同学将爬虫速度再降低一点,还是能跑的。
可能有挺多同学需要微博数据写论文,在群里找一下已有数据的同学吧,购买代理也不便宜。
(我也没怎么跑微博,手上也没什么数据)
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/53379904)