对Alpha-zero很感兴趣,所以耐心阅读了mastering the game of go without human knowledge
Deepmind 官网的介绍:AlphaGo Zero: Learning from scratch
在阅读的过程中,对蒙特卡洛树搜索算法不甚了解,下面翻译了youtube上一位英国教授的网络课程视频。
同时,我在CSDN资源中上传了自己研究AlphaGo的两篇文章后,写的两个版本的AlphaGo算法结构和MCTS结构的对比分析的文章,名为”AlphaGo VS AlphaGo Zero 对比分析讲解”,有兴趣的读者可以下载。
蒙特卡洛树搜索(MCTS)算法
MCTS算法是一种决策算法,每次模拟(simulation)分为4步:
1. Tree traversal:
其中,
2. Node expansion
3. Rollout (random simulation)
4. Backpropagation
步骤1,2的流程图如下:
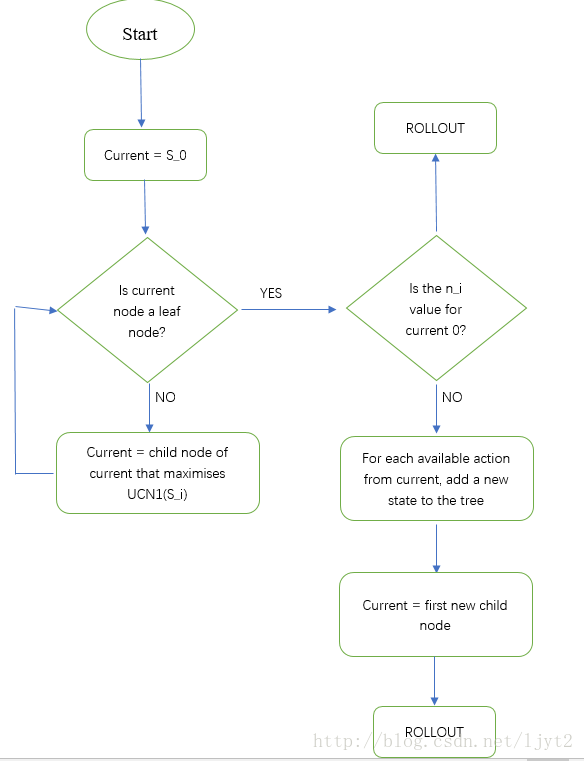
步骤3 Rollout 的细节:
Rollout(S_i):
loop forever:
if S_i is a terminal state:
return value(S_i)
A_i = random(available-actions(S_i))
S_i = simulate(A_i,S_i)讲一个具体的例子:
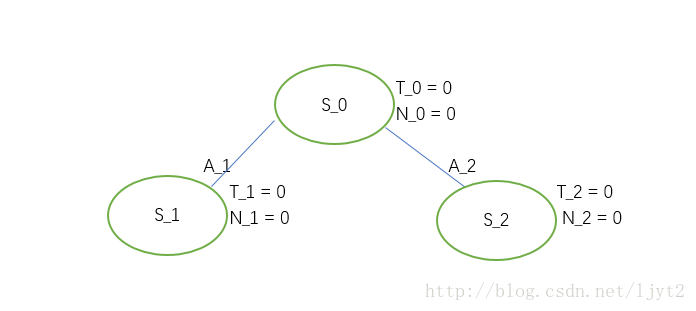
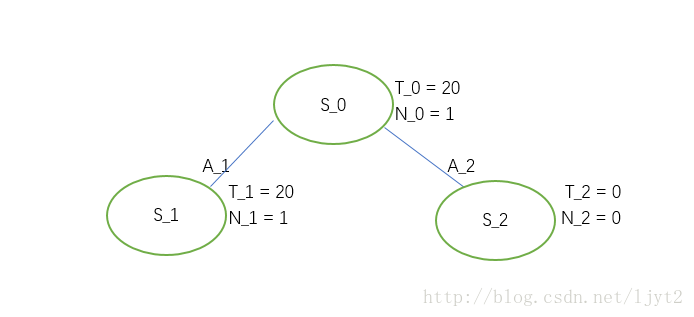
- 树的初始状态:
T 表示总的 value, N 表示被访问的次数(visit count)。A表示动作(action).
第一次迭代(iteration):
从状态
这种情况下,我们就按顺序取第一个,即
按照步骤1,2的流程图,我们现在需要判断目前的结点
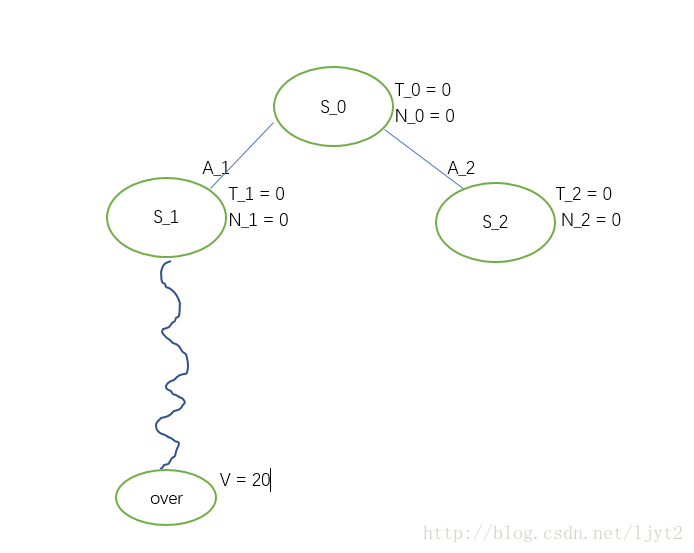
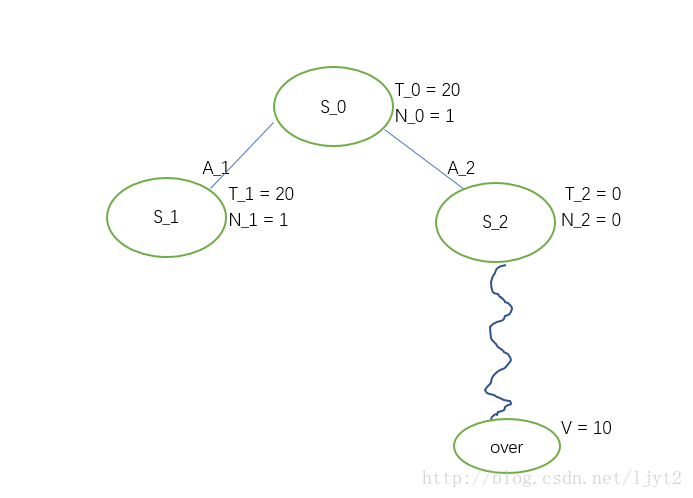
Rollout其实就是在接下来的步骤中每一步都随机采取动作,直到停止点(围棋中的对局结束),得到一个最终的value。
假设Rollout最终值为20.
接下来,进行步骤4 Backpropagation,即利用Rollout最终得到的value来更新路径上每个结点的T,N值。
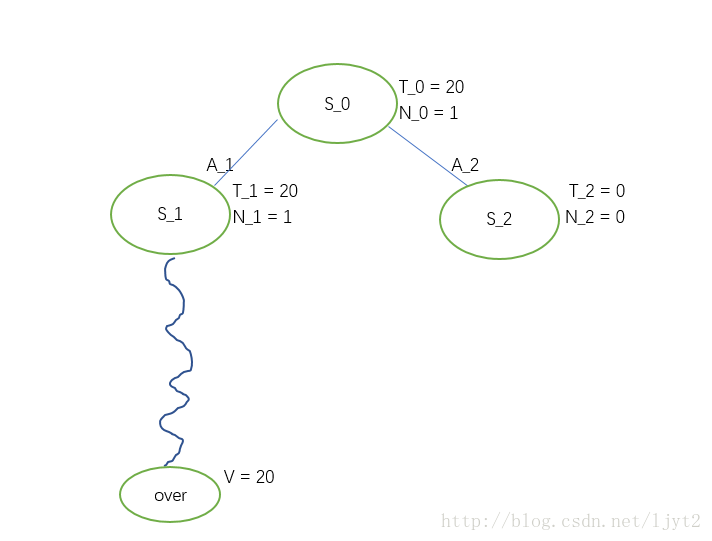
之后把Rollout的结果删除:
MCTS的想法就是要从
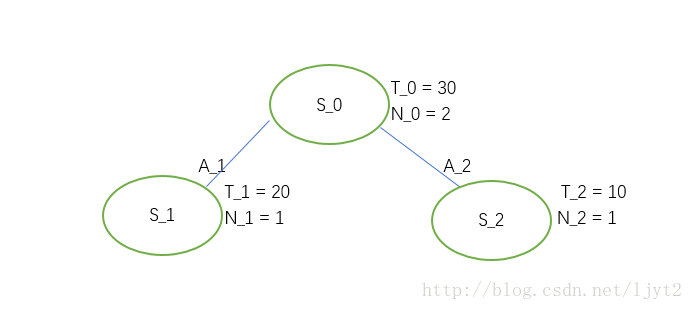
第二次迭代:
我们从
首先,计算下面两个结点
所以,选动作
同上,现在要判断结点
之后进行Backpropogation:
第三次迭代:
首先,计算UCB1值:
执行动作
是否是叶节点? 是。
被访问次数是否为0?否。
按照流程图所示,现在进入Node expansion步骤。同样假设只有两个动作可选。
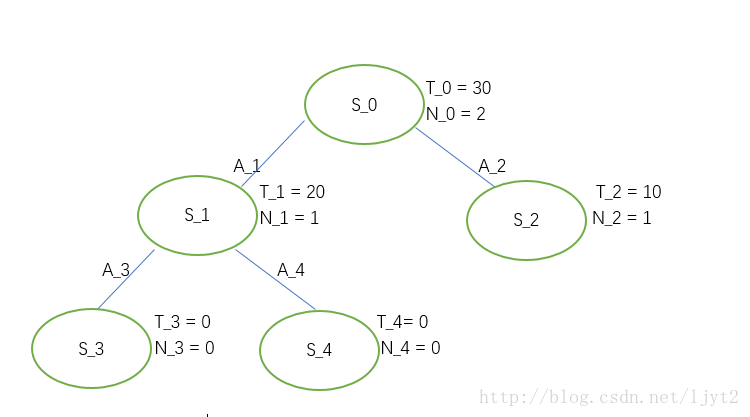
选择
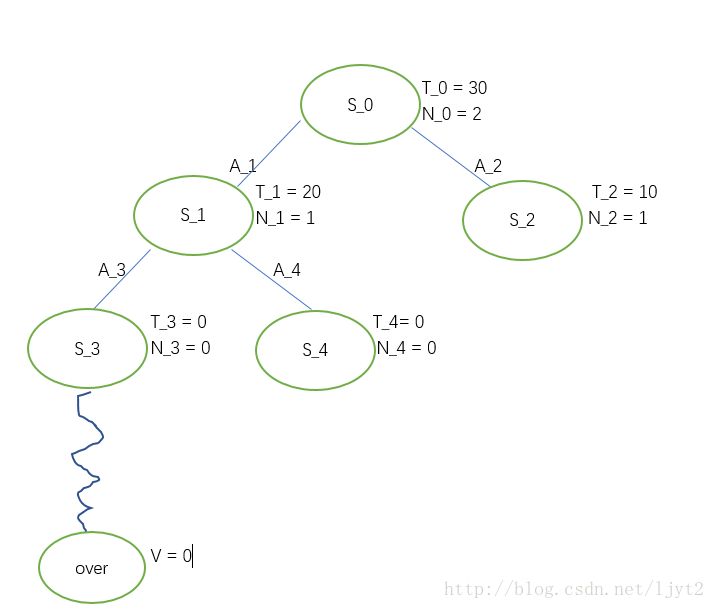
更新路径上每个结点的值,之后删除Rollout的值:
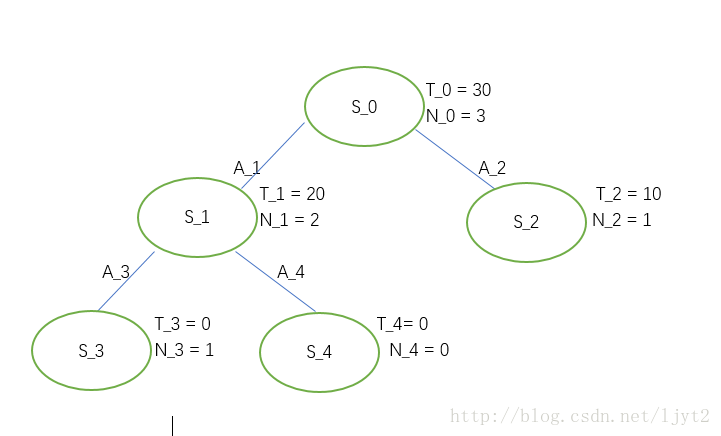
第四次迭代:
首先,计算UCB1值:
选择
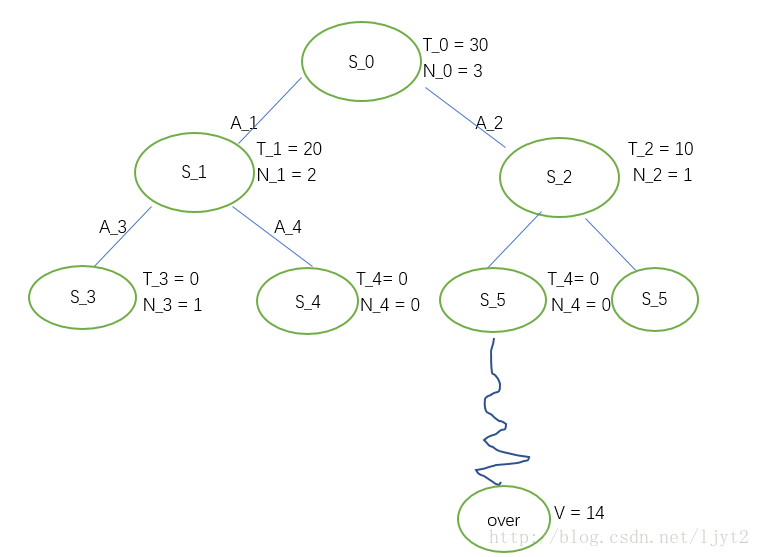
更新路径上的结点:
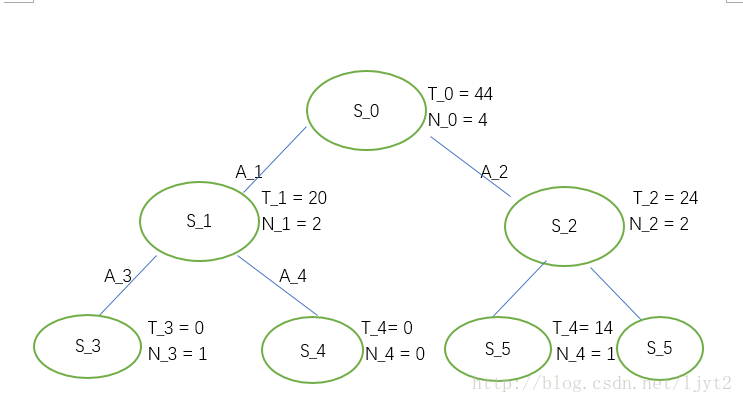
假设我们设定最大迭代次数为4,则我们的迭代完毕。这时,利用得到的树来决定在
以上就是MCTS的过程,是翻译自youtube.。
以上内容如有错误,皆由博主负责,与youtube上教授无关。