前言:
生活中的数据总体分为两种:结构化数据和非结构化数据。
(1)结构化数据: 有固定长度或者类型的数据,例如:数据库中的数据, 元数据(就是操作系统中的数据,有大小有名称有类型);
查询方式:
1、顺序扫描法: 拿着需要搜索的关键字,然后逐行匹配内容,直到找到和关键字匹配的内容. 例如:windows中搜索文件的算法;sql语句中使用like;
优点: 只要内容中包含要搜索的关键字,就一定能找到需要的内容
缺点: 效率非常缓慢。
2、数值检索,可以建立一张排序好的索引表,以二分法实现查找,速度很快。
(2)非结构化数据: 没有固定长度和类型的数据, 例如: 邮件,word文档等磁盘上的文件。
查询方式:
1、顺序扫描法:拿着需要搜索的关键字,然后逐行匹配内容,直到找到和关键字匹配的内容.
2、全文检索算法(倒排索引算法): 首先将搜索的内容中的词抽取出来,组成索引(字典中的目录), 搜索时根据关键字先去查询索引,然后通过索引来查找文档(字典中的内容).
优点: 查询效率高,速度快
缺点: 全文检索算法是用空间来换取时间, 因为通过内容创建索引,索引是个单独的文件,所以又额外占用了磁盘空间, 但是这种算法查询效率高,节省时间
一、简介:
Lucene是apache下的全文检索引擎工具包,工具包就是一堆jar包,不能独立运行,但是可以用它jar包中的API,创建像百度,谷歌这样的搜索引擎系统.
lucene和全文检索引擎系统区别:
lucene:是一个工具包,就是一堆jar包, 不能独立运行,但是可以使用它来创建搜索引擎系统
全文检索引擎系统:也叫做搜索引擎系统, 它可以独立放到tomcat下运行, 它对外提供搜索服务,比如百度,谷歌.
二、应用领域:
. 1:互联网全文检索引擎 : 例如 百度, 谷歌, 必应;
. 2:站内全文检索 : 比如: 京东还有淘宝的搜索功能;
. 3:数据库搜索使用模糊查询会使用关键字like, 而like内部使用的算法是顺序扫描法,效率非常低,所以一般对于大量的文本数据会使用lucene来优化查询。
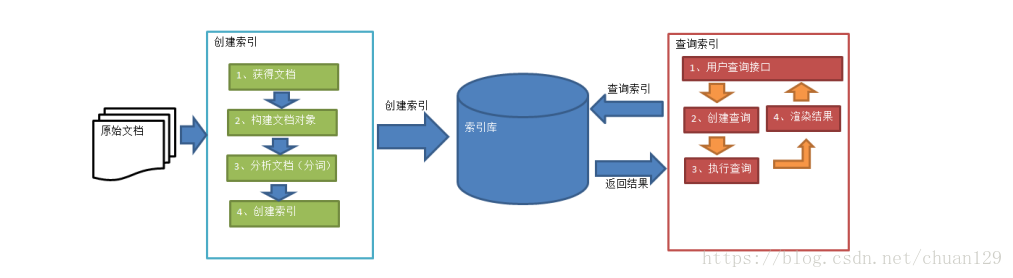
三、架构搭建:

创建文档和域的时候要考虑的问题:

1、是否分词: 分词的目的是为了索引
分词: 需要创建索引并且这个属性分词后有意义,则分词,比如内容,比如名称
不分词: 不需要创建索引的可以不分词, 还有属性是一个整体,分开后无意义的不需要分词 比如: 身份证号, 主键id
2、是否索引: 索引的目的就是为了搜索
索引: 需要使用这个字段进行搜索,就需要索引
不索引: 不需要使用这个字段进行搜索,则不索引
3、(document)是否存储: 存储是为了显示,是否存储要根据需求,不需要显示就可以不存储
存储: 需要直接显示出来的就存储
不存储: 不需要直接显示出来的
因为存储需要占用磁盘空间,所以这个需要考虑存储的需求和性价比
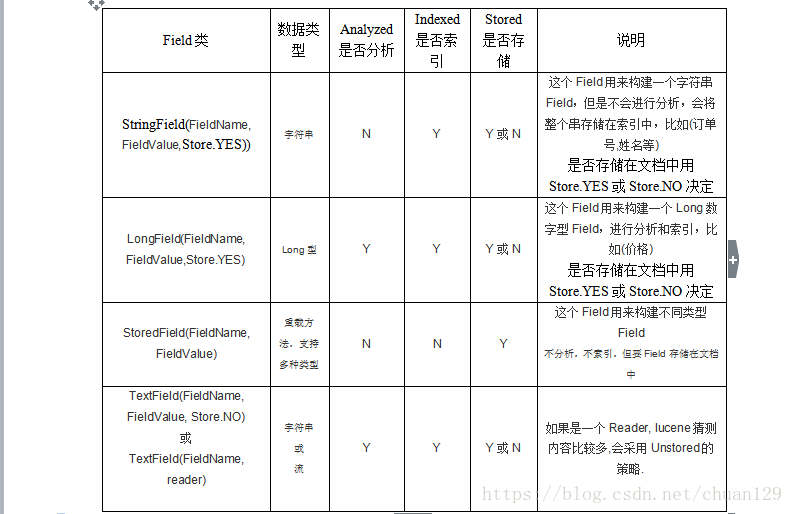
需要记住有哪些属性,面试的时候可能会问。
功能一:创建索引库
1、导包
下载Lucene工具包 :http://lucene.apache.org/ ,导入需要使用的jar包;
2、创建索引库
@Test
public void testIndexCreate() throws Exception{
//1. 从系统的硬盘中提取需要创建索引和文档的文件
File dir = new File("E:\\01.参考资料\\searchsource");
//文档集合,用于下面存储文件的各项内容
List<Document> docList = new ArrayList<Document>();
//2. 遍历目录中文件
for(File file : dir.listFiles()){
String fileName = file.getName();
String filePath = file.getPath();
String fileContext = FileUtils.readFileToString(file);
long fileSize = FileUtils.sizeOf(file);
//创建文档对象,用户存储文档中的各项内容
Document doc = new Document();
/**
* 改造Field
* 是否分词: 分词, 因为需要根据名称进行搜索, 并且这个名称分词后有意义
* 是否索引: 索引, 因为需要根据名称进行搜索,所以需要索引
* 是否存储: 存储, 因为需要显示名称
*/
TextField fileNameField = new TextField("fileName", fileName, Store.YES);
/**
* 改造Field
* 是否分词: 不分词, 因为路径分词后无意义
* 是否索引: 不索引, 不需要根据路径进行搜索, 因为人们也记不住每个文件的路径.
* 是否存储: 存储, 因为需要原始文件存放的路径
*/
StoredField filePathField = new StoredField("filePath", filePath, Store.YES);
/**
* 改造Field
* 是否分词: 分词, 因为内容分词后有意义,并且需要根据内容进行查找
* 是否索引: 索引, 因为需要根据内容进行查找
* 是否存储: 不存储,因为相对来讲, 内容所占磁盘空间大, 而又不需要直接显示出来,所以存储白白浪费磁盘空间.
*/
TextField fileContextField = new TextField("fileContext", fileContext, Store.NO);
/**
* 改造Field
* 是否分词: 分词, 因为lucene底层封装的数字算法, 不用认为干预,只要记住数字要分词就行了
* 是否索引: 索引, 因为希望根据数字范围进行查询
* 是否存储: 存储, 因为要直接显示出来
*/
LongField fileSizeField = new LongField("fileSize", fileSize, Store.YES);
//将所有域放入文档对象中
doc.add(fileNameField);
doc.add(filePathField);
doc.add(fileContextField);
doc.add(fileSizeField);
//将文档放入文档集合中
docList.add(doc);
}
//3. 创建分词器
//StandardAnalyzer是标准分词器,标准分词器对英文分词效果非常好, 对中文是单字分词,也就是一个字就作为一个词
Analyzer analyzer = new StandardAnalyzer();
//4. 创建目录对象:因为需要指定索引和文档存储的位置
//FSDirectory file system 是存储到硬盘上
//RAMDirectory 存储到内存中
Directory directory = FSDirectory.open(new File("E:\\dic"));
//5. 创建索引写的初始化对象
//第一个参数是你所使用的lucene的版本号, 第二个参数指定分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//6. 创建索引和文档的写对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//7. 遍历文档集合,需要一个一个存储
for(Document doc : docList){
//8. 存储
indexWriter.addDocument(doc);
}
//9. 提交
indexWriter.commit();
//10 关闭
indexWriter.close();
}
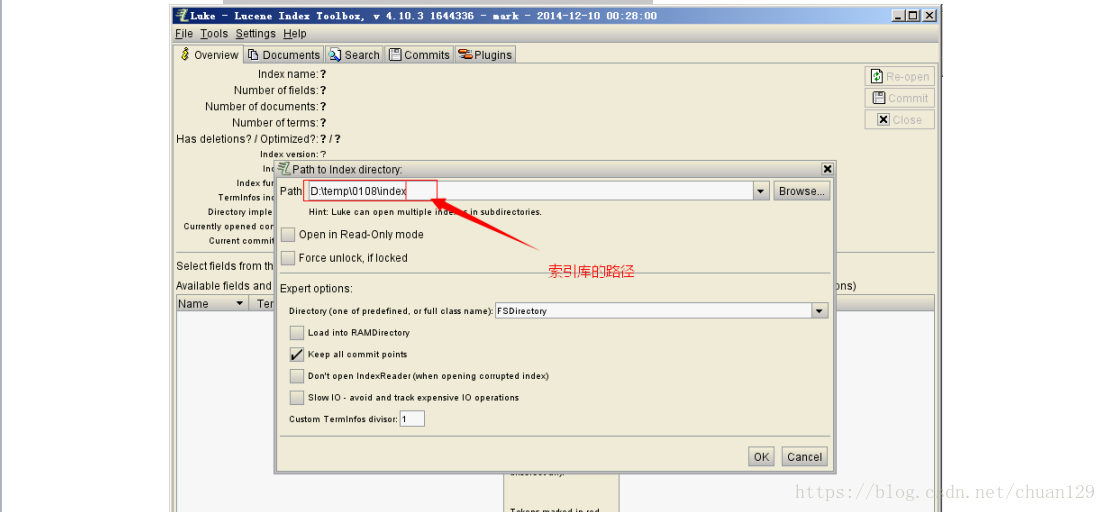
3、使用Luke工具查看索引文件
4、删除文档
@Test
public void testIndexDel() throws Exception{
Analyzer analyzer = new StandardAnalyzer();
//1. 创建目录对象:因为需要指定索引和文档存储的位置
//FSDirectory file system 是存储到硬盘上
//RAMDirectory 存储到内存中
Directory directory = FSDirectory.open(new File("E:\\dic"));
//2. 创建索引写的初始化对象
//第一个参数是你所使用的lucene的版本号, 第二个参数指定分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//3. 创建索引和文档的写对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//4. 删除所有(一般不会删除所有)
//indexWriter.deleteAll();
//4. 根据名称进行删除
//term叫做词元:就是一个单词, 这里指定要删除的词, 第一个参数:域名, 第二个参数:要删除的单词
indexWriter.deleteDocuments(new Term("fileName", "apache"));
//5. 提交
indexWriter.commit();
//6 关闭
indexWriter.close();
}
5、更新文档
@Test
public void testIndexUpdate() throws Exception{
Analyzer analyzer = new StandardAnalyzer();
//1. 创建目录对象:因为需要指定索引和文档存储的位置
//FSDirectory file system 是存储到硬盘上
//RAMDirectory 存储到内存中
Directory directory = FSDirectory.open(new File("E:\\dic"));
//2. 创建索引写的初始化对象
//第一个参数是你所使用的lucene的版本号, 第二个参数指定分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//3. 创建索引和文档的写对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//4. 更新
Document doc = new Document();
doc.add(new TextField("fileName", "think in java", Store.YES));
indexWriter.updateDocument(new Term("fileName", "apache"), doc);
//5. 提交
indexWriter.commit();
//6 关闭
indexWriter.close();
}
Lucene不提供制作用户搜索界面的功能,需要根据自己的需求开发搜索界面。
功能二:查询索引
一、常用查询
@Test
public void testIndexSearch() throws Exception{
//1. 搜索时需要分词,并且要和创建索引时用同样的分词器
Analyzer analyzer = new IKAnalyzer();
//2. 创建查询对象
//第一个参数叫做默认搜索域:如果查询语法中指定了搜索的域那么就去指定的域名中搜索,
//如果只写了查询的关键字没指定搜索的域则去默认搜索域中进行搜索
QueryParser queryParser = new QueryParser("fileContext", analyzer);
Query query = queryParser.parse("fileName:apache");
//3. 创建目录流对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("E:\\dic"));
//4. 创建文档和索引的读取对象
IndexReader indexReader = IndexReader.open(directory);
//5. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//6. 搜索并获取结果对象, 第一个参数,搜索语法对象, 第二个参数:一共显示多少条
TopDocs topDocs = indexSearcher.search(query, 5);
//一共查询到多少条数据
System.out.println("====count=====" + topDocs.totalHits);
//7. 获取查询出的结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历结果集
for(ScoreDoc scoreDoc : scoreDocs){
//文档的id
int docID = scoreDoc.doc;
//通过文档ID读取指定的文档对象
Document document = indexReader.document(docID);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("======================");
}
//关闭
indexReader.close();
}
二、数值范围查询
@Test
public void testNumericRangeQuery() throws Exception{
//1. 搜索时需要分词,并且要和创建索引时用同样的分词器
Analyzer analyzer = new IKAnalyzer();
//2. 查询大于等于0kb 小于等于100kb的文件
//第一个参数:搜索的域名, 第二个参数:最小值, 第三个参数:最大值
//第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query query = NumericRangeQuery.newLongRange("fileSize", 0l, 100l, true, true);
//3. 创建目录流对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("E:\\dic"));
//4. 创建文档和索引的读取对象
IndexReader indexReader = IndexReader.open(directory);
//5. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//6. 搜索并获取结果对象, 第一个参数,搜索语法对象, 第二个参数:一共显示多少条
TopDocs topDocs = indexSearcher.search(query, 5);
//一共查询到多少条数据
System.out.println("====count=====" + topDocs.totalHits);
//7. 获取查询出的结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历结果集
for(ScoreDoc scoreDoc : scoreDocs){
//文档的id
int docID = scoreDoc.doc;
//通过文档ID读取指定的文档对象
Document document = indexReader.document(docID);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("======================");
}
//关闭
indexReader.close();
}
三、组合查询
@Test
public void testBooleanQuery() throws Exception{
//1. 搜索时需要分词,并且要和创建索引时用同样的分词器
Analyzer analyzer = new IKAnalyzer();
//2. 查询大于等于0kb 小于等于100kb的文件 并且 名称中包含web关键字的查出来
//查询大于等于0kb 小于等于100kb的文件
//第一个参数:搜索的域名, 第二个参数:最小值, 第三个参数:最大值
//第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 0l, 100l, true, true);
QueryParser queryParser = new QueryParser("fileName", analyzer);
Query query2 = queryParser.parse("web");
//Occur.MUST 必须 相当于and
//Occur.SHOULD 或者 相当于or
//Occur.MUST_NOT不是必须 相当于 not
//注意:单个MUST_NOT 和 多个只有MUST_NOT 不起作用
BooleanQuery query = new BooleanQuery();
query.add(numericQuery, Occur.MUST);
query.add(query2, Occur.MUST);
//3. 创建目录流对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("E:\\dic"));
//4. 创建文档和索引的读取对象
IndexReader indexReader = IndexReader.open(directory);
//5. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//6. 搜索并获取结果对象, 第一个参数,搜索语法对象, 第二个参数:一共显示多少条
TopDocs topDocs = indexSearcher.search(query, 5);
//一共查询到多少条数据
System.out.println("====count=====" + topDocs.totalHits);
//7. 获取查询出的结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历结果集
for(ScoreDoc scoreDoc : scoreDocs){
//文档的id
int docID = scoreDoc.doc;
//通过文档ID读取指定的文档对象
Document document = indexReader.document(docID);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("======================");
}
//关闭
indexReader.close();
}
四、查询所有
@Test
public void testMatchAllQuery() throws Exception{
//1. 搜索时需要分词,并且要和创建索引时用同样的分词器
Analyzer analyzer = new IKAnalyzer();
//2. 查询出所有文档
MatchAllDocsQuery matchAllDocsQuery = new MatchAllDocsQuery();
//3. 创建目录流对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("E:\\dic"));
//4. 创建文档和索引的读取对象
IndexReader indexReader = IndexReader.open(directory);
//5. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//6. 搜索并获取结果对象, 第一个参数,搜索语法对象, 第二个参数:一共显示多少条
TopDocs topDocs = indexSearcher.search(matchAllDocsQuery, 5);
//一共查询到多少条数据
System.out.println("====count=====" + topDocs.totalHits);
//7. 获取查询出的结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历结果集
for(ScoreDoc scoreDoc : scoreDocs){
//文档的id
int docID = scoreDoc.doc;
//通过文档ID读取指定的文档对象
Document document = indexReader.document(docID);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("========= ============");
}
//关闭
indexReader.close();
}
五、多个域查询
@Test
public void testMultiFieldQueryParser() throws Exception{
//1. 搜索时需要分词,并且要和创建索引时用同样的分词器
Analyzer analyzer = new IKAnalyzer();
//2. 从多个域中进行查询(多个域是或者的关系)
String[] fields = {"fileName", "fileContext"};
MultiFieldQueryParser multiFieldQueryParser = new MultiFieldQueryParser(fields, analyzer);
Query query = multiFieldQueryParser.parse("apache");
//3. 创建目录流对象,指定索引库的位置
Directory directory = FSDirectory.open(new File("E:\\dic"));
//4. 创建文档和索引的读取对象
IndexReader indexReader = IndexReader.open(directory);
//5. 创建搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//6. 搜索并获取结果对象, 第一个参数,搜索语法对象, 第二个参数:一共显示多少条
TopDocs topDocs = indexSearcher.search(query, 5);
//一共查询到多少条数据
System.out.println("====count=====" + topDocs.totalHits);
//7. 获取查询出的结果集
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
//遍历结果集
for(ScoreDoc scoreDoc : scoreDocs){
//文档的id
int docID = scoreDoc.doc;
//通过文档ID读取指定的文档对象
Document document = indexReader.document(docID);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("======================");
}
//关闭
indexReader.close();
}
功能三:支持中文分词
因为Lucene自带中文分词器无法满足中文分词,所以需要借助第三方——ik分词器。是中国团队开发的一个开源的第三方中文分词器, 可以按照语法进行分词.
原理: 里面有多个filter, 每个过滤器作用不一样, 有去掉空格的, 有去掉停用词, 有去掉标点符号的等.
1、将jar包、配置文件、扩展词典和停用词典添加到classpath下
注意:mydict.dic和ext_stopword.dic文件的格式改为UTF-8,注意是无BOM 的UTF-8 编码。

2、修改分词器代码

创建,删除,更新都需要改
Lucene重原理,轻使用。