大纲
1、需求分析
1.1 数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
1.2 非结构化数据查询方法
1.2.1顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
1.2.2 全文检索(Full-text Search)
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
1.3如何实现全文检索
可以使用Lucene实现全文检索。Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
1.4 全文检索的应用场景
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
(1)互联网全文检索引擎(比如百度, 谷歌, 必应)
(2)站内全文检索引擎(淘宝, 京东搜索功能)
(3)优化数据库查询(因为数据库中使用like关键字是全表扫描也就是顺序扫描算法,查询慢)
2、Lucene shix实现全文检索的流程
2.1 索引和搜索的流程图
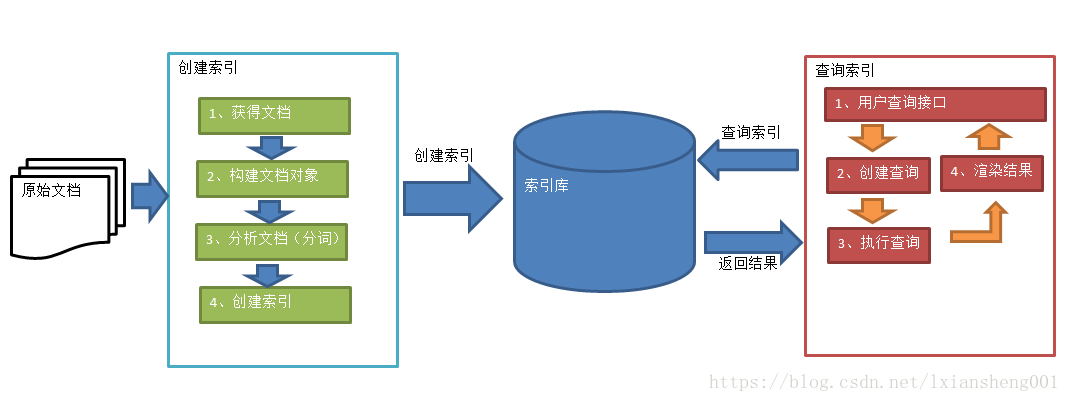
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容-->采集文档--->创建文档--->分析文档--->索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面--->创建查询--->执行搜索,从索引库搜索--->渲染搜索结果
3、获取原始wend文档
创建文档对象
分析文档
创建索引
2 Lucene 结构

2.3 索引
域名:词 这样的形式,
它里面有指针执行这个词来源的文档
索引库: 放索引的文件夹(这个文件夹可以自己随意创建,在里面放索引就是索引库)
Term词元: 就是一个词, 是lucene中词的最小单位
2.4 wend文档
Document对象,一个Document中可以有多个Field域对象,Field域对象中是key value键值对的形式:有域名和域值,
一个document就是数据库表中的一条记录, 一个Filed域对象就是数据库表中的一行一列
这是一个通用的存储结构.
创建索引和所有时所用的分词器必须一致
2.5 域的详细介绍
是否分词:
分词的作用是为了索引
需要分词: 文件名称, 文件内容
不需要分词: 不需要索引的域不需要分词,还有就是分词后无意义的域不需要分词
比如: id, 身份证号
是否索引:
索引的的目的是为了搜索.
需要搜索的域就一定要创建索引,只有创建了索引才能被搜索出来
不需要搜索的域可以不创建索引
需要索引: 文件名称, 文件内容, id, 身份证号等
不需要索引: 比如图片地址不需要创建索引, e:\\xxx.jpg
因为根据图片地址搜索无意义
是否存储:
存储的目的是为了显示.
是否存储看个人需要,存储就是将内容放入Document文档对象中保存出来,会额外占用磁盘空间, 如果搜索的时候需要马上显示出来可以放入document中也就是要存储,这样查询显示速度快, 如果不是马上立刻需要显示出来,则不需要存储,因为额外占用磁盘空间不划算.
2.6 域的各种类型
| Field类 |
数据类型 |
Analyzed 是否分析 |
Indexed 是否索引 |
Stored 是否存储 |
说明 |
| StringField(FieldName, FieldValue,Store.YES)) |
字符串 |
N |
Y |
Y或N |
这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) |
重载方法,支持多种类型 |
N |
N |
Y |
这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader)
|
字符串 或 流 |
Y |
Y |
Y或N |
如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
注意:lucene底层的算法,钱数是要分词的,因为要根据价钱进行对比
例如: 大于12.5元的小于100元的商品搜索出来
3、 索引库的维护
3.1 索引库的添加
3.2 索引库的修改
3.3 索引库的删除
4、 索引库的查询(重点)
4.1 使用query的子类查询
4.1.1 termQuery
4.1.2 BumericRangeQuery
4.1.3 BooleanQuery
4.1.4 MatchAllDocsQuery
4.2 使用queryparser查询
4.2.1 QueryParser
4.2.2 MultiFieldQueryParser