倒排索引
lucnce采用倒排索引,例如:对
{“_id”:1,”name”:”欧阳红叶”,”age”:18}
{“_id”:2,”name”:”欧阳晴明”,”age”:17}
两条数据,会建立如下索引:
| word | index |
|---|---|
| 欧阳 | 1[1],2[1],0,0 #当前词在id=1的doc中出现1次,offset为0,在id=2的doc中出现一次,offset为0 |
| 红叶 | 1[1],0 #当前词在id=1的doc中出现1次,offset为0 |
| 晴明 | 2[1],0 #当前词在id=2的doc中出现1次,offset为0 |
索引模块
首先对文本进行索引分析,然后建立索引。
1. 索引分析模块Analyzer:
https://www.elastic.co/guide/en/elasticsearch/reference/5.x/analysis.html
1)分解器(Tokenizer) :
英文分解器会把中文分解成一个一个的字,安装中文分解器就可以了,例如对于文本“英文分解器”:
英文分解器分解后:“英”、“文”、“分”、“解”、“器”,
中文分解器分解后 “英文”、“分解”、“分解器”
2)词元过滤器(token filters)
- 停用词过滤器:
英文中对于分解器分解出的 the 、a 、is 等这些词,不对其建索引
中文对于分解器分解出的 的、了、吗 等这些词,不对其建索引
大写转小写过滤器:
如 对于 ElasticSearch ,分解器分解出”Elastic” “Search” 两个词,将转成”elastic” “search”自定义词库过滤器?:
对于一些非常规的,比如某些专业领域的词汇如石油行业的“构造井”,分词器可能不能准确的分解出,或者流行词如“蓝瘦香菇”等。这时可以自定义词库。
(1)在IK的cofig/custom目录下创建shiyou_words.dic文件,每个自定义的词单独一行
(2)在ik的配置文件config/IKAnalyzer.cfg.xml中做如下配置:
<entry key="ext_dic">custom/shiyou_words.dic;custom/liuxingci.dic</entry>- 索引建立模块Indexer
1)在建立索引过程中,分析处理过的文档将被加入到索引列表。事实上,Lucene为此仅提供了一个非常简单的API,而后自行内生地完成了此过程的所有功能
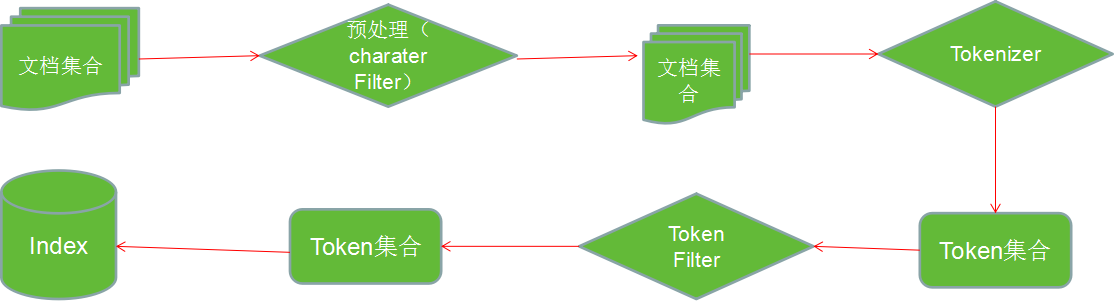
索引和搜索
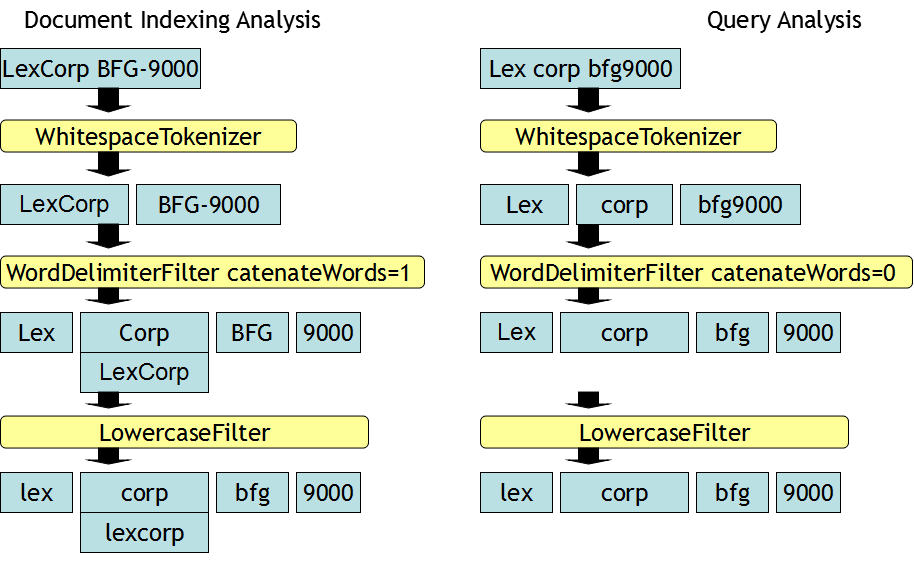
搜索过程同样首先要对搜索的关键词做分析,同索引分析一样,要经过tokenizer和多个token filters。
然后再通过解析后的tokens进行搜索。
热更新IK词库(不必重启es服务)
(1)只需将plugins/IK/config/ik/IKAnalyzer.cfg.xml``中的配置项xxx的值,配置为一个动态页面 tomcat/webapps/ROOT“目录下,创建自定义词库文件hot.dic,然后将(1)中配置项的值改为“`http://hostname:8080/hot.dic即可。
(2) 将词库文件放在http服务器上,例如tomcat服务器:
在