1.什么是fpm,怎么启动、关闭、重启,fpm
FPM是FastCGI Process Manager的缩写,由全称我们可以知道其和FastCGI有关,就是一个FastCGI的进程管理器。对于FastCGI我们可以理解成一个协议,儿FPM是其在PHP中的一个实现。
FPM的出现实现了PHP应用的分布式部署,这样使得PHP和web服务器可以在不同的机器上。当然与其说是FPM不如说是FastCGI的出现。最初FPM并没有被PHP的官方正式应用于PHP中,只是作为PHP的一个补丁应用。但是自从PHP5.3.3版本以后FPM被正式捆绑进PHP中,作为了PHP的一部分。这样我们配置起来比较方便,只需在PHP编译的时候添加—enable-fpm选项即可
php-5.6.9]# ./configure –enable-fpm
Fpm的简单配置
Fpm在php编译的时候添加—enable-fpm选项即可启动fpm,此外在编译的时候还有两个选项分别是 –with-fpm-user=USER 和—with-fpm-group=GROUP,用来设定fpm所属的用户和用户组。如果不指定这两项,那默认的用户和用户组都是nobody。当然这两项也可以在fpm的配置文件php-fpm.conf(其所在目录为PHP安装目录/etc/php-fpm.conf)中修改。
user = nobody
//所属用户
group = nobody
//所属组
listen = 127.0.0.1:9000
//fpm所在服务器的ip地址和监听的端口号,默认为9000
pm = dynamic
//设置进程管理器是如何管理子进程的,dynamic动态管理至少会有一个子进程被创建,其数量有个最大值由pm.max_children来设定,而创建的数量由pm.start_servers来设定;static 静态管理设置固定数量的子进程随着服务启动而被创建;ondemand 在服务启动的时候并不创建子进程只是当有请求的时候才根据情况创建。
pm.max_children = 10
//当pm设置为static的时候,此值表示随着服务的启动创建的子进程的数量;当pm设置为dynamic或者ondemand的时候,此值表示创建的子进程最多不能超过此数量
pm.start_servers = 2
//表示随着服务启动创建的子进程(注意这里是子进程而不是线程)的数量,此选项只有在pm 设置为dynamic的时候才有效。并且这个值默认设置为 min_spare_servers + (max_spare_servers – min_spare_servers)/2,并且如果此值设为0,那么创建的子进程的数量也是由上述公式决定。
pm.min_spare_servers = 1
//要求闲置的服务进程的数量的最小值
pm.max_spare_servers = 3
//闲置的服务进程的数量的最大值
pm.process_idle_timeout = 10s
//进程的闲置时间,以秒为单位,超过这个时间该进程将会被杀死
Fpm的应用
下面我们来看一下如何管理fastcgi服务,首先我们可以进入php安装目录
~]# cd /usr/local/php5
php5]# ./sbin/php-fpm
//开启fastcgi服务,开启服务以后会在/usr/local/php5/var/run/php-fpm.pid中有fastcgi主进程id
php5]# kill –INT `cat /usr/local/php5/var/run/php-fpm.pid`
//关闭fastcgi服务
php5]# kill –USR2 ` cat /usr/local/php5/var/run/php-fpm.pid`
//重启fastcgi服务
Fpm使用说明
在fpm简单配置中我们提到pm=dynamic和pm.start_servers =2。当开启fastcgi服务以后首先我们查看 php-fpm.pid
php5]# cat /usr/local/php5/var/run/php-fpm.pid //其结果为
32407
php5]# ps x | grep php-fpm //接着我们使用此命令查看其主进程情况
32407 ? Ss 0:00 php-fpm: master process (/usr/local/php5/etc/php-fpm.conf)
php5]# ps –ef | grep php-fpm //然后再使用该命令查看其所有进程情况
root 32407 1 0 13:46 ? 00:00:00 php-fpm: master process (/usr/local/php5/etc/php-fpm.conf)
nobody 32408 32407 0 13:46 ? 00:00:00 php-fpm: pool www
nobody 32409 32407 0 13:46 ? 00:00:00 php-fpm: pool www
在这里我们看到了三条信息,第一条是主进程,由系统创建,其id为32407,父进程id为1。剩余两条是其子进程,因为在pm.start_servers = 2 我们设置的为2,所以随着服务的启动会创建两个子进程。这两个子进程的用户都是nobody(user=nobody),其进程id分别是 32408、32409,第三项是这两个子进程的父进程的id 32407。
当然fpm至少会创建一个子进程,因为如果start_servers 设置为0 那么其会根据上面我们说的那个公式计算出子进程的数量。当然如果我们设置min_spare_servers 和max_spare_servers都为0,那子进程的数量为0,这样的话是不能启动服务的(这些设置有效的前提是pm设为dynamic)。因为fpm使用用户为nobody的子进程来处理请求的,那个由系统创建的主进程——id为32407,所属用户为root——是不能处理请求的。当然我们可以根据我们服务器的实际情况(例如:内存大小)来优化我们这里的进程数量。
启动php-fpm:
/usr/local/php/sbin/php-fpm
php 5.3.3 以后的php-fpm 不再支持 php-fpm 以前具有的 /usr/local/php/sbin/php-fpm (start|stop|reload)等命令,所以不要再看这种老掉牙的命令了,需要使用信号控制:
master进程可以理解以下信号
INT, TERM 立刻终止
QUIT 平滑终止
USR1 重新打开日志文件
USR2 平滑重载所有worker进程并重新载入配置和二进制模块
一个简单直接的重启方法:
先查看php-fpm的master进程号

# ps aux|grep php-fpm root 21891 0.0 0.0 112660 960 pts/3 R+ 16:18 0:00 grep --color=auto php-fpm root 42891 0.0 0.1 182796 1220 ? Ss 4月18 0:19 php-fpm: master process (/usr/local/php/etc/php-fpm.conf) nobody 42892 0.0 0.6 183000 6516 ? S 4月18 0:07 php-fpm: pool www nobody 42893 0.0 0.6 183000 6508 ? S 4月18 0:17 php-fpm: pool www
重启php-fpm:
kill -USR2 42891
OK了。
上面方案一般是没有生成php-fpm.pid文件时使用,如果要生成php-fpm.pid,使用下面这种方案:
上面master进程可以看到,matster使用的是/usr/local/php/etc/php-fpm.conf这个配置文件,cat /usr/local/php/etc/php-fpm.conf 发现:
[global] ; Pid file ; Note: the default prefix is /usr/local/php/var ; Default Value: none ;pid = run/php-fpm.pid
pid文件路径应该位于/usr/local/php/var/run/php-fpm.pid,由于注释掉,所以没有生成,我们把注释去除,再kill -USR2 42891 重启php-fpm,便会生成pid文件,下次就可以使用以下命令重启,关闭php-fpm了:
php-fpm 关闭:
kill -INT 'cat /usr/local/php/var/run/php-fpm.pid'
php-fpm 重启:
kill -USR2 'cat /usr/local/php/var/run/php-fpm.pid'
网上搜到Nginx和PHP-FPM的启动、重启、停止脚本:http://www.jb51.net/article/58796.htm
英语原文:Inversion of Control 中文翻译:控制反转 IOC的基本概念是:不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器负责将这些联系在一起。
简单的来讲,就是由容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在:控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转。
先从IOC说起,这个概念其实是从我们平常new一个对象的对立面来说的,我们平常使用对象的时候,一般都是直接使用关键字类new一个对象,那这样有什么坏处呢?其实很显然的,使用new那么就表示当前模块已经不知不觉的和new的对象耦合了,而我们通常都是更高层次的抽象模块调用底层的实现模块,这样也就产生了模块依赖于具体的实现,这样与我们JAVA中提倡的面向接口面向抽象编程是相冲突的,而且这样做也带来系统的模块架构问题。很简单的例子,我们在进行数据库操作的时候,总是业务层调用DAO层,当然我们的DAO一般都是会采用接口开发,这在一定程度上满足了松耦合,使业务逻辑层不依赖于具体的数据库DAO层。但是我们在使用的时候还是会new一个特定数据库的DAO层,这无形中也与特定的数据库绑定了,虽然我们可以使用抽象工厂模式来获取DAO实现类,但除非我们一次性把所有数据库的DAO写出来,否则在进行数据库迁移的时候我们还是得修改DAO工厂类。
那我们使用IOC能达到什么呢?IOC,就是DAO接口的实现不再是业务逻辑层调用工厂类去获取,而是通过容器(比如spring)来自动的为我们的业务层设置DAO的实现类。这样整个过程就反过来,以前是我们业务层主动去获取DAO,而现在是DAO主动被设置到业务逻辑层中来了,这也就是反转控制的由来。通过IOC,我们就可以在不修改任何代码的情况下,无缝的实现数据库的换库迁移,当然前提还是必须得写一个实现特定数据库的DAO。我们把DAO普遍到更多的情况下,那么IOC就为我们带来更大的方便性,比如一个接口的多个实现,我们只需要配置一下就ok了,而不需要再一个个的写工厂来来获取了。这就是IOC为我们带来的模块的松耦合和应用的便利性。
说白了其实就是由我们平常的new转成了使用反射来获取类的实例。
3、redis中的锁的实现方案有哪些?
1. redis加锁分类
- redis能用的的加锁命令分表是
INCR、SETNX、SET
2. 第一种锁命令INCR
这种加锁的思路是, key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加一。 然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1 ,说明这个锁正在被使用当中。
1、 客户端A请求服务器获取key的值为1表示获取了锁
2、 客户端B也去请求服务器获取key的值为2表示获取锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求的时候获取key的值为1表示获取锁成功
5、 客户端B执行代码完成,删除锁
$redis->incr($key);
$redis->expire($key, $ttl); //设置生成时间为1秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. 第二种锁SETNX
这种加锁的思路是,如果 key 不存在,将 key 设置为 value
如果 key 已存在,则 SETNX 不做任何动作
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
$redis->setNX($key, $value);
$redis->expire($key, $ttl);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4. 第三种锁SET
上面两种方法都有一个问题,会发现,都需要设置 key 过期。那么为什么要设置key过期呢?如果请求执行因为某些原因意外退出了,导致创建了锁但是没有删除锁,那么这个锁将一直存在,以至于以后缓存再也得不到更新。于是乎我们需要给锁加一个过期时间以防不测。
但是借助 Expire 来设置就不是原子性操作了。所以还可以通过事务来确保原子性,但是还是有些问题,所以官方就引用了另外一个,使用 SET 命令本身已经从版本 2.6.12 开始包含了设置过期时间的功能。
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
$redis->set($key, $value, array('nx', 'ex' => $ttl)); //ex表示秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5. 其它问题
虽然上面一步已经满足了我们的需求,但是还是要考虑其它问题?
1、 redis发现锁失败了要怎么办?中断请求还是循环请求?
2、 循环请求的话,如果有一个获取了锁,其它的在去获取锁的时候,是不是容易发生抢锁的可能?
3、 锁提前过期后,客户端A还没执行完,然后客户端B获取到了锁,这时候客户端A执行完了,会不会在删锁的时候把B的锁给删掉?
6. 解决办法
针对问题1:使用循环请求,循环请求去获取锁
针对问题2:针对第二个问题,在循环请求获取锁的时候,加入睡眠功能,等待几毫秒在执行循环
针对问题3:在加锁的时候存入的key是随机的。这样的话,每次在删除key的时候判断下存入的key里的value和自己存的是否一样
do { //针对问题1,使用循环
$timeout = 10;
$roomid = 10001;
$key = 'room_lock';
$value = 'room_'.$roomid; //分配一个随机的值针对问题3
$isLock = Redis::set($key, $value, 'ex', $timeout, 'nx');//ex 秒
if ($isLock) {
if (Redis::get($key) == $value) { //防止提前过期,误删其它请求创建的锁
//执行内部代码
Redis::del($key);
continue;//执行成功删除key并跳出循环
}
} else {
usleep(5000); //睡眠,降低抢锁频率,缓解redis压力,针对问题2
}
} while(!$isLock);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
7. 另外一个锁
以上的锁完全满足了需求,但是官方另外还提供了一套加锁的算法,这里以PHP为例
$servers = [
['127.0.0.1', 6379, 0.01],
['127.0.0.1', 6389, 0.01],
['127.0.0.1', 6399, 0.01],
];
$redLock = new RedLock($servers);
//加锁
$lock = $redLock->lock('my_resource_name', 1000);
//删除锁
$redLock->unlock($lock)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面是官方提供的一个加锁方法,就是和第6的大体方法一样,只不过官方写的更健壮。所以可以直接使用官方提供写好的类方法进行调用。官方提供了各种语言如何实现锁。
原文链接:Dennis`s blog
官方提供分布式redis锁说明
PHPreids分布式锁
谈谈Redis的SETNX
redis五种常见使用场景下PHP实现
4、如何设计一个秒杀系统?
什么是秒杀
秒杀场景一般会在电商网站举行一些活动或者节假日在12306网站上抢票时遇到。对于电商网站中一些稀缺或者特价商品,电商网站一般会在约定时间点对其进行限量销售,因为这些商品的特殊性,会吸引大量用户前来抢购,并且会在约定的时间点同时在秒杀页面进行抢购。
秒杀系统场景特点
- 秒杀时大量用户会在同一时间同时进行抢购,网站瞬时访问流量激增。
- 秒杀一般是访问请求数量远远大于库存数量,只有少部分用户能够秒杀成功。
- 秒杀业务流程比较简单,一般就是下订单减库存。
秒杀架构设计理念
限流: 鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。
削峰:对于秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会有很高的瞬间峰值。高峰值流量是压垮系统很重要的原因,所以如何把瞬间的高流量变成一段时间平稳的流量也是设计秒杀系统很重要的思路。实现削峰的常用的方法有利用缓存和消息中间件等技术。
异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。
内存缓存:秒杀系统最大的瓶颈一般都是数据库读写,由于数据库读写属于磁盘IO,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,效率会有极大地提升。
可拓展:当然如果我们想支持更多用户,更大的并发,最好就将系统设计成弹性可拓展的,如果流量来了,拓展机器就好了。像淘宝、京东等双十一活动时会增加大量机器应对交易高峰。
架构方案
一般秒杀系统架构
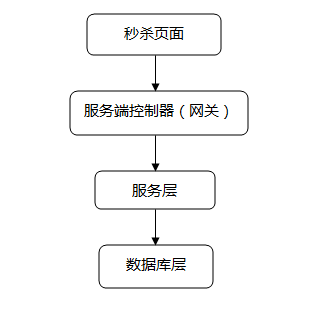
设计思路
将请求拦截在系统上游,降低下游压力:秒杀系统特点是并发量极大,但实际秒杀成功的请求数量却很少,所以如果不在前端拦截很可能造成数据库读写锁冲突,甚至导致死锁,最终请求超时。
充分利用缓存:利用缓存可极大提高系统读写速度。
消息队列:消息队列可以削峰,将拦截大量并发请求,这也是一个异步处理过程,后台业务根据自己的处理能力,从消息队列中主动的拉取请求消息进行业务处理。
前端方案
浏览器端(js):
页面静态化:将活动页面上的所有可以静态的元素全部静态化,并尽量减少动态元素。通过CDN来抗峰值。
禁止重复提交:用户提交之后按钮置灰,禁止重复提交
用户限流:在某一时间段内只允许用户提交一次请求,比如可以采取IP限流
后端方案
服务端控制器层(网关层)
限制uid(UserID)访问频率:我们上面拦截了浏览器访问的请求,但针对某些恶意攻击或其它插件,在服务端控制层需要针对同一个访问uid,限制访问频率。
服务层
上面只拦截了一部分访问请求,当秒杀的用户量很大时,即使每个用户只有一个请求,到服务层的请求数量还是很大。比如我们有100W用户同时抢100台手机,服务层并发请求压力至少为100W。
采用消息队列缓存请求:既然服务层知道库存只有100台手机,那完全没有必要把100W个请求都传递到数据库啊,那么可以先把这些请求都写到消息队列缓存一下,数据库层订阅消息减库存,减库存成功的请求返回秒杀成功,失败的返回秒杀结束。
利用缓存应对读请求:对类似于12306等购票业务,是典型的读多写少业务,大部分请求是查询请求,所以可以利用缓存分担数据库压力。
- 利用缓存应对写请求:缓存也是可以应对写请求的,比如我们就可以把数据库中的库存数据转移到Redis缓存中,所有减库存操作都在Redis中进行,然后再通过后台进程把Redis中的用户秒杀请求同步到数据库中。
数据库层
数据库层是最脆弱的一层,一般在应用设计时在上游就需要把请求拦截掉,数据库层只承担“能力范围内”的访问请求。所以,上面通过在服务层引入队列和缓存,让最底层的数据库高枕无忧。
案例:利用消息中间件和缓存实现简单的秒杀系统
Redis是一个分布式缓存系统,支持多种数据结构,我们可以利用Redis轻松实现一个强大的秒杀系统。
我们可以采用Redis 最简单的key-value数据结构,用一个原子类型的变量值(AtomicInteger)作为key,把用户id作为value,库存数量便是原子变量的最大值。对于每个用户的秒杀,我们使用 RPUSH key value插入秒杀请求, 当插入的秒杀请求数达到上限时,停止所有后续插入。
然后我们可以在台启动多个工作线程,使用 LPOP key 读取秒杀成功者的用户id,然后再操作数据库做最终的下订单减库存操作。
当然,上面Redis也可以替换成消息中间件如ActiveMQ、RabbitMQ等,也可以将缓存和消息中间件 组合起来,缓存系统负责接收记录用户请求,消息中间件负责将缓存中的请求同步到数据库。
参考文档:https://my.oschina.net/xianggao/blog/52494
5、如何理解swoole中的模型
并发之始
之前我们已经初步讨论的一个WebServer是怎样工作的,但之前的例子中,我们看到的服务都是一个客户端与一个服务端一问一答的场景,但事实上,绝大部分时候我们预期的服务并不是只向一个客户端提供服务,所以,作为一个成熟的Server,并发\并行问题是必须解决的。
其实,“并发”和“并行”两个概念在计算机中是相关但不同的,有兴趣的童鞋可以自己搜索一下,笔者今天仅讨论并发咯。
而软件开发中,最常见的并发问题解决方案,莫过于多线程/多进程两种模式了。
微软的体系中,除了线程,还有“纤程”;而最近非常火爆的“协程”,则又是另一个解决方案了。
在《计算机组成原理》中我们都学过,并发中最迫切需要解决的问题之一,就是数据的可靠性问题,而不同的并发模型,其并发数据可靠性的机制往往各有特点,因此,在使用Swoole Server\Client的过程中,其并发解决方案的模型是必须要了解的,否则使用上很容易出现不符合预期的结果。
简单说,就是防止脏读脏写
Swoole目前总共有三种运行模式,其中Base模式基本没有生产应用价值;协程模式暂时还处于预览阶段;因此,笔者在此想和大家讨论的,就是Swoole的多进程模式,也是官方目前最推荐用于生产环境的模式。
事实上,Swoole曾经还有多线程模式,但由于Zend在多线程模式本身的缺陷,在1.6版本后,多线程模式已经被关闭。
进程模型
首先,我们还是来简单回顾一下Swoole Server的构造函数,之前我们已经解决了Host、Port、Protocol的问题,这期我们来看最后一个参数的:
<?php
$server = new \swoole_server("127.0.0.1",8088,SWOOLE_PROCESS,SWOOLE_SOCK_TCP);
第三个参数mode中我们填入的PROCESS,即表示当前Server是运行于多进程模式的。
其他mode的可选参数可以参考手册
然后,我们简单实现一个没有任何内容的Server:
<?php
$server = new \swoole_server("127.0.0.1",8088,SWOOLE_PROCESS,SWOOLE_SOCK_TCP);
$server->on('connect', function ($serv, $fd){ });
$server->on('receive', function ($serv, $fd, $from_id, $data){ });
$server->on('close', function ($serv, $fd){ });
$server -> start();
在启动服务之后,我们继续在Shell中输入以下命令:
> php swoole_server_demo.php
> pstree -ap|grep swoole_server_demo
|-php,2829 swoole_server_demo.php
| |-php,2831 swoole_server_demo.php
| | `-php,2836 swoole_server_demo.php
pstree命令可以查看进程的树模型
从系统的输出中,我们可以很容看出server其实有3个进程,进程的pid分别是2829、2831、2836,其中2829是2831的父进程,而2831又是2836的父进程。
所以,其实我们虽然看起来只是启动了一个Server,其实最后产生的是三个进程。
这三个进程中,所有进程的根进程,也就是例子中的2829进程,就是所谓的Master进程;而2831进程,则是Manager进程;最后的2836进程,是Worker进程。
基于此,我们简单梳理一下,当执行的start方法之后,发生了什么:
- 守护进程模式下,当前进程fork出Master进程,然后退出,Master进程触发OnMasterStart事件。
- Master进程启动成功之后,fork出Manager进程,并触发OnManagerStart事件。
- Manager进程启动成功时候,fork出Worker进程,并触发OnWorkerStart事件。
非守护进程模式下,则当前进程直接作为Master进程工作。
所以,一个最基础的Swoole Server,至少需要有3个进程,分别是Master进程、Manager进程和Worker进程。
不要看到进程多就觉得麻烦咯,其实全赖它们各司其职,才有Swoole重新定义PHP的壮举。
事实上,一个多进程模式下的Swoole Server中,有且只有一个Master进程;有且只有一个Manager进程;却可以有n个Worker进程。
那么这几个进程之间是怎么协同工作的呢?我们先暂时考虑只有一个Worker的情况。
那么,我们又可以拉出之前写的最简单Server,来看看这个过程中,三种进程之间是怎么协作的。
- Client主动Connect的时候,Client实际上是与Master进程中的某个Reactor线程发生了连接。
- 当TCP的三次握手成功了以后,由这个Reactor线程将连接成功的消息告诉Manager进程,再由Manager进程转交给Worker进程。
- 在这个Worker进程中触发了OnConnect的方法。
- 当Client向Server发送了一个数据包的时候,首先收到数据包的是Reactor线程,同时Reactor线程会完成组包,再将组好的包交给Manager进程,由Manager进程转交给Worker。
- 此时Worker进程触发OnReceive事件。
- 如果在Worker进程中做了什么处理,然后再用Send方法将数据发回给客户端时,数据则会沿着这个路径逆流而上。
同样的故事,随着认识的加深,会发现不一样的精彩
首先,Master进程是一个多线程进程,其中有一组非常重要的线程,叫做Reactor线程(组),每当一个客户端连接上服务器的时候,都会由Master进程从已有的Reactor线程中,根据一定规则挑选一个,专门负责向这个客户端提供维持链接、处理网络IO与收发数据等服务。
以前我们提到的分包拆包等功能也是在这里完成的哦。
而Manager进程,某种意义上可以看做一个代理层,它本身并不直接处理业务,其主要工作是将Master进程中收到的数据转交给Worker进程,或者将Worker进程中希望发给客户端的数据转交给Master进程进行发送。
另外,Manager进程还负责监控Worker进程,如果Worker进程因为某些意外挂了,Manager进程会重新拉起新的Worker进程,有点像Supervisor的工作
而这个特性,也是最终实现热重载的核心机制。
最后就是Worker进程了,顾名思义,Worker进程其实就是处理各种业务工作的进程,Manager将数据包转交给Worker进程,然后Worker进程进行具体的处理,并根据实际情况将结果反馈给客户端。
如果要打个比方的话,Master进程就像业务窗口的,Reactor就是前台接待员,用户很多的时候,后边的用户就需要排队等待服务;Reactor负责与客户直接沟通,对客户的请求进行初步的整理(传输层级别的整理——组包);然后,Manager进程就是类似项目经理的角色,要负责将业务分配给合适的Worker(例如空闲的Worker);而Worker进程就是工人,负责实现具体的业务。
实际上,一对多投递这种模式总是在并发的程序设计非常常见:1个Master进程投递n个Reactor线程;1个Manager进程投递n个Worker进程。
现在,我们来看看一个简单的多进程Swoole Server的几个基本配置:
<?php
$server->set([
"daemonize"=>true,
"reactor_num"=>2,
"worker_num"=>4,
]);
$server -> start();
reactor_num:表示Master进程中,Reactor线程总共开多少个,注意,这个可不是越多越好,因为计算机的CPU是有限的,所以一般设置为与CPU核心数量相同,或者两倍即可。
worker_num:表示启动多少个Worker进程,同样,Worker进程数量不是越多越好,仍然设置为与CPU核心数量相同,或者两倍即可。
读书万卷不若自己亲手写一行,试验一下这个配置下,Server启动后,pstree的结构。
进程模型与数据共享
在以前的讨论中,我们最常接触到的回调方法如下:
- OnConnect
- OnReceive
- OnClose
如上一节所说,这三个回调其实都是在Worker进程中发生的,而了解了进程模型以后,我们可以认识一下更多的回调方法了:
// 以下回调发生在Master进程
$server->on("start", function (\swoole_server $server){
echo "On master start.";
});
$server->on('shutdown', function (\swoole_server $server){
echo "On master shutdown.";
});
// 以下回调发生在Manager进程
$server->on('ManagerStart', function (\swoole_server $server){
echo "On manager start.";
});
$server->on('ManagerStop', function (\swoole_server $server){
echo "On manager stop.";
});
// 以下回调也发生在Worker进程
$server->on('WorkerStart', function (\swoole_server $server, $worker_id){
echo "Worker start";
});
$server->on('WorkerStop', function(\swoole_server $server, $worker_id){
echo "Worker stop";
});
$server->on('WorkerError', function(\swoole_server $server, $worker_id, $worker_pid, $exit_code){
echo "Worker error";
});
OK,现在我们更新一下我们的测试代码,以展示不同进程之间,数据共享的特点和关系:
$server = new \swoole_server("127.0.0.1",8088,SWOOLE_PROCESS,SWOOLE_SOCK_TCP);
$server->on('connect', function ($serv, $fd){ });
$server->on('receive', function ($serv, $fd, $from_id, $data){ });
$server->on('close', function ($serv, $fd){ });
// 在交互进程中放入一个数据。
$server->BaseProcess = "I'm base process."
// 为了便于阅读,以下回调方法按照被起调的顺序组织
// 1. 首先启动Master进程
$server->on("start", function (\swoole_server $server){
echo "On master start.".PHP_EOL;
// 先打印在交互进程写入的数据
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
// 修改交互进程中写入的数据
$server->BaseProcess = "I'm changed by master.";
// 在Master进程中写入一些数据,以传递给Manager进程。
$server->MasterToManager = "Hello manager, I'm master.";
});
// 2. Master进程拉起Manager进程
$server->on('ManagerStart', function (\swoole_server $server){
echo "On manager start.".PHP_EOL;
// 打印,然后修改交互进程中写入的数据
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
$server->BaseProcess = "I'm changed by manager.";
// 打印,然后修改在Master进程中写入的数据
echo "server->MasterToManager = ".$server->MasterToManager.PHP_EOL;
$server->MasterToManager = "This value has changed in manager.";
// 写入传递给Worker进程的数据
$server->ManagerToWorker = "Hello worker, I'm manager.";
});
// 3. Manager进程拉起Worker进程
$server->on('WorkerStart', function (\swoole_server $server, $worker_id){
echo "Worker start".PHP_EOL;
// 打印在交互进程写入,然后在Master进程,又在Manager进程被修改的数据
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
// 打印,并修改Master写入给Manager的数据
echo "server->MasterToManager = ".$server->MasterToManager.PHP_EOL;
$server->MasterToManager = "This value has changed in worker.";
// 打印,并修改Manager传递给Worker进程的数据
echo "server->ManagerToWorker = ".$server->ManagerToWorker.PHP_EOL;
$server->ManagerToWorker = "This value is changed in worker.";
});
// 4. 正常结束Server的时候,首先结束Worker进程
$server->on('WorkerStop', function(\swoole_server $server, $worker_id){
echo "Worker stop".PHP_EOL;
// 分别打印之前的数据
echo "server->ManagerToWorker = ".$server->ManagerToWorker.PHP_EOL;
echo "server->MasterToManager = ".$server->MasterToManager.PHP_EOL;
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
});
// 5. 紧接着结束Manager进程
$server->on('ManagerStop', function (\swoole_server $server){
echo "Manager stop.".PHP_EOL;
// 分别打印之前的数据
echo "server->ManagerToWorker = ".$server->ManagerToWorker.PHP_EOL;
echo "server->MasterToManager = ".$server->MasterToManager.PHP_EOL;
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
});
// 6. 最后回收Master进程
$server->on('shutdown', function (\swoole_server $server){
echo "Master shutdown.".PHP_EOL;
// 分别打印之前的数据
echo "server->ManagerToWorker = ".$server->ManagerToWorker.PHP_EOL;
echo "server->MasterToManager = ".$server->MasterToManager.PHP_EOL;
echo "server->BaseProcess = ".$server->BaseProcess.PHP_EOL;
});
$server -> start();
这段程序测试的时候,我们需要开两个会话,第一个会话用于执行并打印输出;第二个会话用于使用kill命令通知Server执行一些工作,然后我们看看输出的结果:
# 在会话一中
> php swoole_server_demo.php
On master start.
server->BaseProcess = I'm base process.
On manager start.
server->BaseProcess = I'm base process.
server->MasterToManager =
Worker start
server->BaseProcess = I'm base process.
server->MasterToManager =
server->ManagerToWorker =
从Manager start和Worker start中的输出,我们发现BaseProcess、MasterToManager、ManagerToWorker并没有分别在Master、Manager中被修改,并在子进程中打印出被修改后的结果,这是为什么呢?别急,我们继续做个实验。
打开会话二,先执行pstree -ap|grep php找到刚刚启动的Server的Master进程的PID,然后向该进程发送-10信号,然后再次实行pstree命令看看:
> pstree -ap|grep php
| | `-php,5512 swoole_server_demo.php
| | |-php,5513 swoole_server_demo.php
| | | `-php,5515 swoole_server_demo.php
> kill -10 5512
> pstree -ap|grep php
| | `-php,5512 swoole_server_demo.php
| | |-php,5513 swoole_server_demo.php
| | | `-php,5522 swoole_server_demo.php
-10信号的作用是,要求Swoole重启Worker服务,我们会发现原来的Worker[5515]被干掉了,而产生了一个新的Worker[5522],此时如果我们切换回会话一,会发现增加了以下的输出:
[2016-10-03 02:00:26 $5513.0] NOTICE Server is reloading now.
Worker stop
server->ManagerToWorker = This value is changed in worker.
server->MasterToManager = This value has changed in worker.
server->BaseProcess = I'm base process.
Worker start
server->BaseProcess = I'm changed by manager.
server->MasterToManager = This value has changed in manager.
server->ManagerToWorker = Hello worker, I'm manager.
首先是Swoole自己打印的日志信息,Server正在被reloading,然后Worker[5515]被终止,执行了WorkerStop的方法,此时WorkerStop输出的值我们可以看出,在WorkerStart中的赋值都是生效了的;然后,新的Worker[5522]被启动了,重新触发WorkerStart方法,这时我们发现,BaseProcess、MasterToManager和ManagerToWorker都分别被打印了出来?这是什么原因呢?
原因在方法被执行的顺序上,我们前文中的进程起调顺序并没有问题,但有些地方我们要做一点小小的细化:
- Master进程被启动。
- Manager进程Master进程fork出来。
- Worker进程被Manager进程fork出来。
- MasterStart被回调。
- ManangerStart被回调。
- WorkerStart被回调。
也就是说,三种进程的OnStart方法被回调的时候都有一定的延迟,底层事实上已经完工了fork的行为,才回调的,因此,默认启动的时候,我们在OnMasterStart、OnManagerStart中写入的数据并不能按预期被fork到Manager进程或者Worker进程。
然后,我们执行了kill -10重新拉起Worker进程的时候,此时Worker进程仍然是由Mananger进程fork出来的,但此时ManangerStart已经被执行过了,所以我们会发现在OnWorkerStart的时候,输出变成了ManagerStart中修改过的内容。
OK,现在我们回到Shell会话二,向Master进程发送kill -15命令
> kill -15 5512
然后回到会话一,我们发现输出增加了如下的内容:
[2016-10-03 02:17:35 #5512.0] NOTICE Server is shutdown now.
Worker stop
server->ManagerToWorker = This value is changed in worker.
server->MasterToManager = This value has changed in worker.
server->BaseProcess = I'm changed by manager.
Manager stop.
server->ManagerToWorker = Hello worker, I'm manager.
server->MasterToManager = This value has changed in manager.
server->BaseProcess = I'm changed by manager.
Master shutdown.
server->ManagerToWorker =
server->MasterToManager = Hello manager, I'm master.
server->BaseProcess = I'm changed by master.
kill -15命令是通知Swoole正常终止服务,首先停止Worker进程,触发OnWorkerStop回调,此时我们输出的内容懂事我们在WorkerStart中修改过的版本。
然后停止Manager进程,这时候要留意,我们在Worker中做的所有操作并没有反应在Manager进程上,OnManagerStop的输出仍然是在OnManagerStart中赋值的内容。
最后停止Master进程,也会有相同的事情发生。
通过以上实验,展示了多进程Server的两个重要特性:
- 父进程fork出子进程的时候,子进程会拷贝一份父进程的所有数据。
- 各个进程之间的数据一般情况下是不共享内存的。
所以,学习Swoole的进一步需求就是,要弄清楚各个回调方法分别是在哪个进程中发生的,且发生的顺序是什么。
这两个特性会引起什么问题呢?如果没有弄清楚当前的代码是在哪个进程执行的,很有可能就会引起数据的错误,而多个进程之间进行协作的话,不能像以往的PHP开发一样,通过共享变量实现。
6、当我们查询redis的中的大量的数据出现查询慢的问题,分析可能有哪些原因?Redis的事件循环在一个线程中处理,作为一个单线程程序,重要的是要保证事件处理的时延短,这样,事件循环中的后续任务才不会阻塞;
当redis的数据量达到一定级别后(比如20G),阻塞操作对性能的影响尤为严重;
下面我们总结下在redis中有哪些耗时的场景及应对方法;
耗时长的命令造成阻塞
keys、sort等命令
keys命令用于查找所有符合给定模式 pattern 的 key,时间复杂度为O(N), N 为数据库中 key 的数量。当数据库中的个数达到千万时,这个命令会造成读写线程阻塞数秒;
类似的命令有sunion sort等操作;
如果业务需求中一定要使用keys、sort等操作怎么办?
解决方案:

在架构设计中,有“分流”一招,说的是将处理快的请求和处理慢的请求分离来开,否则,慢的影响到了快的,让快的也快不起来;这在redis的设计中体现的非常明显,redis的纯内存操作,epoll非阻塞IO事件处理,这些快的放在一个线程中搞定,而持久化,AOF重写、Master-slave同步数据这些耗时的操作就单开一个进程来处理,不要慢的影响到快的;
同样,既然需要使用keys这些耗时的操作,那么我们就将它们剥离出去,比如单开一个redis slave结点,专门用于keys、sort等耗时的操作,这些查询一般不会是线上的实时业务,查询慢点就慢点,主要是能完成任务,而对于线上的耗时快的任务没有影响;
smembers命令
smembers命令用于获取集合全集,时间复杂度为O(N),N为集合中的数量;
如果一个集合中保存了千万量级的数据,一次取回也会造成事件处理线程的长时间阻塞;
解决方案:
和sort,keys等命令不一样,smembers可能是线上实时应用场景中使用频率非常高的一个命令,这里分流一招并不适合,我们更多的需要从设计层面来考虑;
在设计时,我们可以控制集合的数量,将集合数一般保持在500个以内;
比如原来使用一个键来存储一年的记录,数据量大,我们可以使用12个键来分别保存12个月的记录,或者365个键来保存每一天的记录,将集合的规模控制在可接受的范围;
如果不容易将集合划分为多个子集合,而坚持用一个大集合来存储,那么在取集合的时候可以考虑使用SRANDMEMBER key [count];随机返回集合中的指定数量,当然,如果要遍历集合中的所有元素,这个命令就不适合了;
save命令
save命令使用事件处理线程进行数据的持久化;当数据量大的时候,会造成线程长时间阻塞(我们的生产上,reids内存中1个G保存需要12s左右),整个redis被block;
save阻塞了事件处理的线程,我们甚至无法使用redis-cli查看当前的系统状态,造成“何时保存结束,目前保存了多少”这样的信息都无从得知;
解决方案:
我没有想到需要用到save命令的场景,任何时候需要持久化的时候使用bgsave都是合理的选择(当然,这个命令也会带来问题,后面聊到);
fork产生的阻塞
在redis需要执行耗时的操作时,会新建一个进程来做,比如数据持久化bgsave:
开启RDB持久化后,当达到持久化的阈值,redis会fork一个新的进程来做持久化,采用了操作系统的copy-on-wirte写时复制策略,子进程与父进程共享Page。如果父进程的Page(每页4K)有修改,父进程自己创建那个Page的副本,不会影响到子进程;
fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,如果内存空间有40G(考虑每个页表条目消耗 8 个字节),那么页表大小就有80M,这个复制是需要时间的,如果使用虚拟机,特别是Xen虚拟服务器,耗时会更长;
在我们有的服务器结点上测试,35G的数据bgsave瞬间会阻塞200ms以上;
类似的,以下这些操作都有进程fork;
Master向slave首次同步数据:当master结点收到slave结点来的syn同步请求,会生成一个新的进程,将内存数据dump到文件上,然后再同步到slave结点中;
AOF日志重写:使用AOF持久化方式,做AOF文件重写操作会创建新的进程做重写;(重写并不会去读已有的文件,而是直接使用内存中的数据写成归档日志);
解决方案:
为了应对大内存页表复制时带来的影响,有些可用的措施:
控制每个redis实例的最大内存量;
不让fork带来的限制太多,可以从内存量上控制fork的时延;
一般建议不超过20G,可根据自己服务器的性能来确定(内存越大,持久化的时间越长,复制页表的时间越长,对事件循环的阻塞就延长)
新浪微博给的建议是不超过20G,而我们虚机上的测试,要想保证应用毛刺不明显,可能得在10G以下;
使用大内存页,默认内存页使用4KB,这样,当使用40G的内存时,页表就有80M;而将每个内存页扩大到4M,页表就只有80K;这样复制页表几乎没有阻塞,同时也会提高快速页表缓冲TLB(translation lookaside buffer)的命中率;但大内存页也有问题,在写时复制时,只要一个页快中任何一个元素被修改,这个页块都需要复制一份(COW机制的粒度是页面),这样在写时复制期间,会耗用更多的内存空间;
使用物理机;
如果有的选,物理机当然是最佳方案,比上面都要省事;
当然,虚拟化实现也有多种,除了Xen系统外,现代的硬件大部分都可以快速的复制页表;
但公司的虚拟化一般是成套上线的,不会因为我们个别服务器的原因而变更,如果面对的只有Xen,只能想想如何用好它;
杜绝新进程的产生,不使用持久化,不在主结点上提供查询;实现起来有以下方案:
1) 只用单机,不开持久化,不挂slave结点。这样最简单,不会有新进程的产生;但这样的方案只适合缓存;
如何来做这个方案的高可用?
要做高可用,可以在写redis的前端挂上一个消息队列,在消息队列中使用pub-sub来做分发,保证每个写操作至少落到2个结点上;因为所有结点的数据相同,只需要用一个结点做持久化,这个结点对外不提供查询;

2) master-slave:在主结点上开持久化,主结点不对外提供查询,查询由slave结点提供,从结点不提供持久化;这样,所有的fork耗时的操作都在主结点上,而查询请求由slave结点提供;
这个方案的问题是主结点坏了之后如何处理?
简单的实现方案是主不具有可替代性,坏了之后,redis集群对外就只能提供读,而无法更新;待主结点启动后,再继续更新操作;对于之前的更新操作,可以用MQ缓存起来,等主结点起来之后消化掉故障期间的写请求;

如果使用官方的Sentinel将从升级为主,整体实现就相对复杂了;需要更改可用从的ip配置,将其从可查询结点中剔除,让前端的查询负载不再落在新主上;然后,才能放开sentinel的切换操作,这个前后关系需要保证;
持久化造成的阻塞
执行持久化(AOF / RDB snapshot)对系统性能有较大影响,特别是服务器结点上还有其它读写磁盘的操作时(比如,应用服务和redis服务部署在相同结点上,应用服务实时记录进出报日志);应尽可能避免在IO已经繁重的结点上开Redis持久化;
子进程持久化时,子进程的write和主进程的fsync冲突造成阻塞
在开启了AOF持久化的结点上,当子进程执行AOF重写或者RDB持久化时,出现了Redis查询卡顿甚至长时间阻塞的问题, 此时, Redis无法提供任何读写操作;
原因分析:
Redis 服务设置了 appendfsync everysec, 主进程每秒钟便会调用 fsync(), 要求内核将数据”确实”写到存储硬件里. 但由于服务器正在进行大量IO操作, 导致主进程 fsync()/操作被阻塞, 最终导致 Redis 主进程阻塞.
redis.conf中是这么说的:
When the AOF fsync policy is set to always or everysec, and a background
saving process (a background save or AOF log background rewriting) is
performing a lot of I/O against the disk, in some Linux configurations
Redis may block too long on the fsync() call. Note that there is no fix for
this currently, as even performing fsync in a different thread will block
our synchronous write(2) call.
当执行AOF重写时会有大量IO,这在某些Linux配置下会造成主进程fsync阻塞;
解决方案:
设置 no-appendfsync-on-rewrite yes, 在子进程执行AOF重写时, 主进程不调用fsync()操作;注意, 即使进程不调用 fsync(), 系统内核也会根据自己的算法在适当的时机将数据写到硬盘(Linux 默认最长不超过 30 秒).
这个设置带来的问题是当出现故障时,最长可能丢失超过30秒的数据,而不再是1秒;
子进程AOF重写时,系统的sync造成主进程的write阻塞
我们来梳理下:
1) 起因:有大量IO操作write(2) 但未主动调用同步操作
2) 造成kernel buffer中有大量脏数据
3) 系统同步时,sync的同步时间过长
4) 造成redis的写aof日志write(2)操作阻塞;
5) 造成单线程的redis的下一个事件无法处理,整个redis阻塞(redis的事件处理是在一个线程中进行,其中写aof日志的write(2)是同步阻塞模式调用,与网络的非阻塞write(2)要区分开来)
产生1)的原因:这是redis2.6.12之前的问题,AOF rewrite时一直埋头的调用write(2),由系统自己去触发sync。
另外的原因:系统IO繁忙,比如有别的应用在写盘;
解决方案:
控制系统sync调用的时间;需要同步的数据多时,耗时就长;缩小这个耗时,控制每次同步的数据量;通过配置按比例(vm.dirty_background_ratio)或按值(vm.dirty_bytes)设置sync的调用阈值;(一般设置为32M同步一次)
2.6.12以后,AOF rewrite 32M时会主动调用fdatasync;
另外,Redis当发现当前正在写的文件有在执行fdatasync(2)时,就先不调用write(2),只存在cache里,免得被block。但如果已经超过两秒都还是这个样子,则会强行执行write(2),即使redis会被block住。
AOF重写完成后合并数据时造成的阻塞
在bgrewriteaof过程中,所有新来的写入请求依然会被写入旧的AOF文件,同时放到AOF buffer中,当rewrite完成后,会在主线程把这部分内容合并到临时文件中之后才rename成新的AOF文件,所以rewrite过程中会不断打印"Background AOF buffer size: 80 MB, Background AOF buffer size: 180 MB",要监控这部分的日志。这个合并的过程是阻塞的,如果产生了280MB的buffer,在100MB/s的传统硬盘上,Redis就要阻塞2.8秒;
解决方案:
将硬盘设置的足够大,将AOF重写的阈值调高,保证高峰期间不会触发重写操作;在闲时使用crontab 调用AOF重写命令;
当数据库某表中数据量较大时,查询会变得比较慢。在此情况下可以考虑BETWEEN查询替换LIMIT查询
实测:app_log大约2000000条数据,从第1500000开始取出10条数据
每次执行SQL语句之前进行数据库查询缓存操作
- reset query cache;
1、select * from app_log limit 1500000,10
[SQL]select * from app_log limit 1500000,10
受影响的行: 0
时间: 1.071s
2、select * from app_log where LOG_ID between 1500000 and 1500009
[SQL]select * from app_log where LOG_ID between 1500000 and 1500009
受影响的行: 0
时间: 0.002s
由于CSDN图片上传失败,截图就省去了,我直接复制的查询结果。时间对比还是很明显的,但是当表中ID出现断行情况的话,between查询得到的结果集就会少于查询条数。
其实也可以在进行查询时判断如果是比较靠后的数据,进行desc排序反向查找,保证limit基数较小。
当然具体使用还要根据项目需求。
8、在mysql中为什么要使用索引?使用索引有什么利与弊建立索引的优缺点:
为什么要创建索引呢?
这是因为,创建索引可以大大提高系统的性能。
第一、通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二、可以大大加快 数据的检索速度,这也是创建索引的最主要的原因。
第三、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四、在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五、通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点, 但是,为表中的每一个列都增加索引,是非常不明智的。
这是因为,增加索引也有许多不利的一个方面:
第一、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二、索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
第三、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
什么样的字段适合创建索引:
索引是建立在数据库表中的某些列的上面。因此,在创建索引的时候,应该仔细考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引,例如:
第一、在经常需要搜索的列上,可以加快搜索的速度;
第二、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
第三、在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
第四、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
第五、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
第六、在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
建立索引,一般按照select的where条件来建立,比如: select的条件是where f1 and f2,那么如果我们在字段f1或字段f2上简历索引是没有用的,只有在字段f1和f2上同时建立索引才有用等。
什么样的字段不适合创建索引:
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,
并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,
在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。
增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索 引。这是因为,修改性能和检索性能是互相矛盾的。
当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。
因此,当修改性能远远大于检索性能时,不应该创建索引。
创建索引的方法::
1、创建索引,例如 create index <索引的名字> on table_name (列的列表);
2、修改表,例如 alter table table_name add index[索引的名字] (列的列表);
3、创建表的时候指定索引,例如create table table_name ( [...], INDEX [索引的名字] (列的列表) );
查看表中索引的方法:
show index from table_name; 查看索引
索引的类型及创建例子::
1.PRIMARY KEY (主键索引)
MySQL> alter table table_name add primary key ( `column` )
2.UNIQUE 或 UNIQUE KEY (唯一索引)
mysql> alter table table_name add unique (`column`)
3.FULLTEXT (全文索引)
mysql> alter table table_name add fulltext (`column` )
4.INDEX (普通索引)
mysql> alter table table_name add index index_name ( `column` )
5.多列索引 (聚簇索引)
mysql> alter table `table_name` add index index_name ( `column1`, `column2`, `column3` )
1.选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。如果使用姓名的话,可能存在同名现象,从而降低查询速度。
2.为经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
3.为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
4.限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
5.尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。例如,对一个CHAR(100)类型的字段进行全文检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
6.尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
7.删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
8 . 最左前缀匹配原则,非常重要的原则。
MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a 1=”” and=”” b=”2” c=”“> 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
9 .=和in可以乱序。
比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
10 . 尽量选择区分度高的列作为索引。
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就 是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条 记录
11 .索引列不能参与计算,保持列“干净”。
比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本 太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
12 .尽量的扩展索引,不要新建索引。
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
注意:选择索引的最终目的是为了使查询的速度变快。上面给出的原则是最基本的准则,但不能拘泥于上面的准则。读者要在以后的学习和工作中进行不断的实践。根据应用的实际情况进行分析和判断,选择最合适的索引方式。
9、你如何理解larvel框架中的是中间件?1、中间件简介
Laravel中可以把HTTP中间件看做“装饰器”,在请求到达最终动作之前对请求进行过滤和处理。中间件在Laravel中有着广泛的应用,比如用户认证、日志、维护模式、开启Session、从Session中获取错误信息,CSRF验证,等等。
中间件类默认存放在app/Http/Middleware目录下。
2、中间件使用
自定义中间件类只需要定义一个handle方法即可,然后我们将主要业务逻辑定义在该方法中,如果我们想在请求处理前执行业务逻辑,则在$next闭包执行前执行业务逻辑操作:
<?php
namespace App\Http\Middleware;
use Closure;
class BeforeMiddleware
{
public function handle($request, Closure $next)
{
// 执行业务逻辑操作
return $next($request);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
如果想要在请求处理后执行中间件业务逻辑,则在$next闭包执行后执行操作:
<?php
namespace App\Http\Middleware;
use Closure;
class AfterMiddleware
{
public function handle($request, Closure $next)
{
$response = $next($request);
// 执行动作
return $response;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们处理的大部分操作都是第一种场景,即在请求处理前执行操作,比如用户认证、CSRF验证、维护模式等都是这样,但也有用到第二种场景的时候,比如StartSession中间件,该中间件在请求处理前后都有操作,其handle方法如下:
public function handle($request, Closure $next)
{
$this->sessionHandled = true;
//如果session驱动已配置,那么我们需要开启session以便为应用准备好数据
//注意Laravel session并没有使用原生的PHP session相关方法,因为它们显得那样蹩脚
if ($this->sessionConfigured()) {
$session = $this->startSession($request);
$request->setSession($session);
}
$response = $next($request);
// 同样,如果session经过配置那么我们需要关闭session以便将session数据持久化到某些存储介质中
// 我们还会添加session id到响应头cookie中
if ($this->sessionConfigured()) {
$this->storeCurrentUrl($request, $session);
$this->collectGarbage($session);
$this->addCookieToResponse($response, $session);
}
return $response;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
此外,定义好中间件后,需要在app/Http/Kernel.php文件中注册该中间件,如果我们定义的中间件想要在全局有效,即每次请求都会调用,则将该中间件追加到middleware∗属性数组;否则如果中间件只是在某些特定的路由中使用,则将其追加到∗middleware∗属性数组;否则如果中间件只是在某些特定的路由中使用,则将其追加到∗routeMiddleware属性数组,并在路由定义时使用middleware选项指定。
3、中间件参数
除了请求实例request和闭包request和闭包next之外,中间件还可以接收额外参数,我们还是以TestMiddleware为例,现在要求年龄在18岁以上的男性才能访问指定页面,handle方法定义如下:
public function handle($request, Closure $next, $gender)
{
if($request->input('age')>=18 && $gender==$request->input('gender')){
return $next($request);
}else{
return redirect()->route('refuse');
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、定义可终止的中间件
可终止的中间件是指定义了terminate方法的中间件,terminate方法会在一次请求生命周期的末尾执行一些操作。比如StartSession中间件定义了该方法,在响应数据发送到浏览器之后将session数据保存起来。
可终止的中间件需要追加到app/Http/Kernel.php类的全局中间件列表即$middleware属性数组中。
调用中间件的terminate方法时,Laravel会从服务容器中取出新的中间件实例,所以如果想要调用handle方法和terminate方法时使用的是同一个中间件实例,需要使用singleton方法将该中间件注册到服务容器。
10、php如何使用redis实现一个异步消息队列?
个人理解在项目中使用消息队列一般是有如下几个原因:
把瞬间服务器的请求处理换成异步处理,缓解服务器的压力
实现数据顺序排列获取
redis实现消息队列步骤如下:
1).redis函数rpush,lpop
2).建议定时任务入队列
3)创建定时任务出队列
文件:demo.php插入数据到redis队列
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<?php
$redis
=
new
Redis();
$redis
->connect(
'127.0.0.1'
,6379);
$password
=
'123456'
;
$redis
->auth(
$password
);
$arr
=
array
(
'h'
,
'e'
,
'l'
,
'l'
,
'o'
,
'w'
,
'o'
,
'r'
,
'l'
,
'd'
);
foreach
(
$arr
as
$k
=>
$v
){
$redis
->rpush(
"mylist"
,
$v
);
}
|
执行后结果如下
?>
文件:index.php定时扫描出队列
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<?php
$redis
=
new
Redis();
$redis
->connect(
'127.0.0.1'
,6379);
$password
=
'123456'
;
$redis
->auth(
$password
);
//list类型出队操作
$value
=
$redis
->lpop(
'mylist'
);
if
(
$value
){
echo
"出队的值"
.
$value
;
}
else
{
echo
"出队完成"
;
}
?>
|
建立定时任务
*/1 * * * * root php /wwwroot/workplace/redis/index.php
*/3 * * * * root php /wwwroot/workplace/redis/demo.php
tail -f /var/log/cron 查看定时任务执行情况
Nov 7 00:30:01 dongzi CROND[6888]: (root) CMD (php /wwwroot/workplace/redis/demo.php)
Nov 7 00:30:01 dongzi CROND[6890]: (root) CMD (php /wwwroot/workplace/redis/index.php )
定时任务执行队列写入结果如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
127.0.0.1:6379> lrange mylist 0 -1
1)
"h"
2)
"e"
3)
"l"
4)
"l"
5)
"o"
6)
"w"
7)
"o"
8)
"r"
9)
"l"
10)
"d"
|
定时任务执行出队列后:
127.0.0.1:6379> lrange mylist 0 -1 1) "e" 2) "l" 3) "l" 4) "o" 5) "w" 6) "o" 7) "r" 8) "l" 9) "d"
AOP: (Aspect Oriented Programming) 面向切面编程。是目前软件开发中的一个热点,也是Spring框架中容。利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。主要的功能是:日志记录,性能统计,安全控制,事务处理,异常处理等等。
AOP、OOP在字面上虽然非常类似,但却是面向不同领域的两种设计思想。OOP(面向对象编程)针对业务处理过程的实体及其属性和行为进行抽象封装,以获得更加清晰高效的逻辑单元划分。 而AOP则是针对业务处理过程中的切面进行提取,它所面对的是处理过程中的某个步骤或阶段,以获得逻辑过程中各部分之间低耦合性的隔离效果。这两种设计思想在目标上有着本质的差异。
总之,AOP可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术,把散落在程序中的公共部分提取出来,做成切面类,这样的好处在于,代码的可重用,一旦涉及到该功能的需求发生变化,只要修改该代码就行,否则,你要到处修改,如果只要修改1、2处那还可以接受,万一有1000处呢。
最常用的AOP应用在数据库连接以及事务处理上。
实现模式可能为:代理模式+工厂模式
列出权限管理系统有关的概念:
1. 权限
系统的所有权限信息。权限具有上下级关系,是一个树状的结构。下面来看一个例子
系统管理
用户管理
查看用户
新增用户
修改用户
删除用户
对于上面的每个权限,又存在两种情况,一个是只是可访问,另一种是可授权,例如对于“查看用户”这个权限,如果用户只被授予“可访问”,那么他就不能将他所具有的这个权限分配给其他人。
2. 用户
应用系统的具体操作者,用户可以自己拥有权限信息,可以归属于0~n个角色,可属于0~n个组。他的权限集是自身具有的权限、所属的各角色具有的权限、所属的各组具有的权限的合集。它与权限、角色、组之间的关系都是n对n的关系。
3. 角色
为了对许多拥有相似权限的用户进行分类管理,定义了角色的概念,例如系统管理员、管理员、用户、访客等角色。角色具有上下级关系,可以形成树状视图,父级角色的权限是自身及它的所有子角色的权限的综合。父级角色的用户、父级角色的组同理可推。
4. 组
为了更好地管理用户,对用户进行分组归类,简称为用户分组。组也具有上下级关系,可以形成树状视图。在实际情况中,我们知道,组也可以具有自己的角色信息、权限信息。这让我想到我们的QQ用户群,一个群可以有多个用户,一个用户也可以加入多个群。每个群具有自己的权限信息。例如查看群共享。QQ群也可以具有自己的角色信息,例如普通群、高级群等。
针对上面提出的四种类型的对象,让我们通过图来看看他们之间的关系。
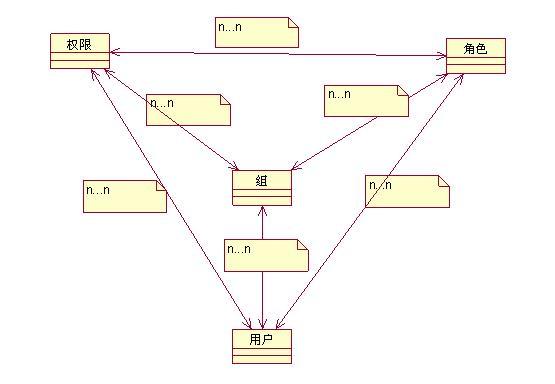
有上图中可以看出,这四者的关系很复杂,而实际的情况比这个图还要复杂,权限、角色、组都具有上下级关系,权限管理是应用系统中比较棘手的问题,要设计一个通用的权限管理系统,工作量也着实不小。
当然对于有些项目,权限问题并不是那么复杂。有的只需要牵涉到权限和用户两种类型的对象,只需要给用户分配权限即可。
在另一些情况中,引入了角色对象,例如基于角色的权限系统, 只需要给角色分配权限,用户都隶属于角色,不需要单独为用户分配角色信息。
通用权限管理设计篇(二)——数据库设计
国庆前整的通用权限设计的数据库初步设计部分,现在贴上来。
理清了对象关系之后,让我们接着来进行数据库的设计。在数据库建模时,对于N对N的
关系,一般需要加入一个关联表来表示关联的两者的关系。初步估计一下,本系统至少需要十张表,分别为:权限表、用户表、角色表、组表、用户权限关联表、用
户角色关联表、角色权限关联表、组权限关联表、组角色关联表、用户属组关联表。当然还可能引出一些相关的表。下面让我们在PowerDesigner中画出各表吧。
各表及其关系如下:
1. 用户表
用户表(TUser) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tu_id |
bigint |
pk, not null |
所属组织 |
to_id |
bigint |
fk, not null |
登录帐号 |
login_name |
varchar(64) |
not null |
用户密码 |
password |
varchar(64) |
not null |
用户姓名 |
vsername |
varchar(64) |
not null |
手机号 |
mobile |
varchar(20) |
|
电子邮箱 |
varchar(64) |
||
创建时间 |
gen_time |
datetime |
not null |
登录时间 |
login_time |
datetime |
|
上次登录时间 |
last_login_time |
datetime |
|
登录次数 |
count |
bigint |
not null |
2. 角色表
角色表(TRole) |
|||
字段名称 |
字段 |
类型 |
备注 |
角色ID |
tr_id |
bigint |
pk, not null |
父级角色ID |
parent_tr_id |
bigint |
not null |
角色名称 |
role_name |
varchar(64) |
not null |
创建时间 |
gen_time |
datetime |
not null |
角色描述 |
description |
varchar(200) |
|
3. 权限表
权限表(TRight) |
|||
字段名称 |
字段 |
类型 |
备注 |
权限ID |
tr_id |
bigint |
pk, not null |
父权限 |
parent_tr_id |
bigint |
not null |
权限名称 |
right_name |
varchar(64) |
not null |
权限描述 |
description |
varchar(200) |
|
4. 组表
组表(TGroup) |
|||
字段名称 |
字段 |
类型 |
备注 |
组ID |
tg_id |
bigint |
pk, not null |
组名称 |
group_name |
varchar(64) |
not null |
父组 |
parent_tg_id |
bigint |
not null |
创建时间 |
gen_time |
datetime |
not null |
组描述 |
description |
varchar(200) |
|
5. 角色权限表
角色权限表(TRoleRightRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
trr_id |
bigint |
pk, not null |
角色 |
Role_id |
bigint |
fk, not null |
权限 |
right_id |
bigint |
fk, not null |
权限类型 |
right_type |
int |
not null(0:可访问,1:可授权) |
6. 组权限表
组权限表(TGroupRightRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tgr_id |
bigint |
pk, not null |
组 |
tg_id |
bigint |
fk, not null |
权限 |
tr_id |
bigint |
fk, not null |
权限类型 |
right_type |
int |
not null(0:可访问,1:可授权) |
7. 组角色表
组角色表(TGroupRoleRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tgr_id |
bigint |
pk, not null |
组 |
tg_id |
bigint |
fk, not null |
角色 |
tr_id |
bigint |
pk, not null |
8. 用户权限表
用户权限表(TUserRightRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tur_id |
bigint |
pk, not null |
用户 |
tu_id |
bigint |
fk, not null |
权限 |
tr_id |
bigint |
fk, not null |
权限类型 |
right_type |
int |
not null(0:可访问,1:可授权) |
9. 用户角色表
用户角色表(TUserRoleRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tur_id |
bigint |
pk, not null |
用户 |
tu_id |
bigint |
fk, not null |
角色 |
tr_id |
bigint |
fk, not null |
10. 用户组表
用户组表(TUserGroupRelation) |
|||
字段名称 |
字段 |
类型 |
备注 |
记录标识 |
tug_id |
bigint |
pk, not null |
用户 |
tu_id |
bigint |
fk, not null |
组 |
tg_id |
bigint |
fk, not null |
11. 组织表
组织表(TOrganization) |
|||
字段名称 |
字段 |
类型 |
备注 |
组织id |
to_id |
bigint |
pk, not null |
父组 |
parent_to_id |
bigint |
not null |
组织名称 |
org_name |
varchar(64) |
not null |
创建时间 |
gen_time |
datetime |
not null |
组织描述 |
description |
varchar(200) |
|
12. 操作日志表
操作日志表(TLog) |
|||
字段名称 |
字段 |
类型 |
备注 |
日志ID |
log_id |
bigint |
pk, not null |
操作类型 |
op_type |
int |
not null |
操作内容 |
content |
varchar(200) |
not null |
操作人 |
tu_id |
bigint |
fk, not null |
操作时间 |
gen_time |
datetime |
not null |