tesseract是一个基于C++编写的开源OCR(光学字符识别)库
本文简单介绍一下windows系统中编译和使用tesseract以及调用该库的C++ api进行开发
环境为win10+vs2015
源码下载
tesseract的编译有诸多依赖,tesseract依赖于leptonica,而leptonica又依赖于png,tiff,jpeg等基础库,所以需要下载这些依赖的源码,并且依次编译
考虑到某些图片格式的基础库源码较老并且久未更新难于编译,本文只编译了较新的libtiff,并作为示例,其他图片格式未测试
下载地址:
- libtiff 4.09,http://download.osgeo.org/libtiff/tiff-4.0.9.zip
- leptonica 1.76.0,http://www.leptonica.com/source/leptonica-1.76.0.tar.gz
- tesseract 3.05.01,https://github.com/tesseract-ocr/tesseract/archive/3.05.01.zip
下载完后解压缩到文件夹,这里将三个项目源码都放在codetest目录
编译
特别指定,本文中所有项目生成都是使用cmake-gui工具(首先要会用这个工具),C++编译使用vs2015,所有cmake编译目录都定为build_x64
所有的编译模式都是:vs2015 win64 release
由于tiff --> leptonica --> tesseract 三者之间层层递进,环环相扣,所以编译一定要注意顺序和设置
step1:编译tiff
常规cmake流程编译出 tiff.lib和tiff.dll,位置在 D:\codetest\tiff-4.0.9\build_x64\libtiff\Release
step2:编译leptonica
cmake配置,勾选Grouped和Advanced,会显示png和tiff等图片库的设置入口,要先将tiff的目录配置进去,使得支持tiff格式
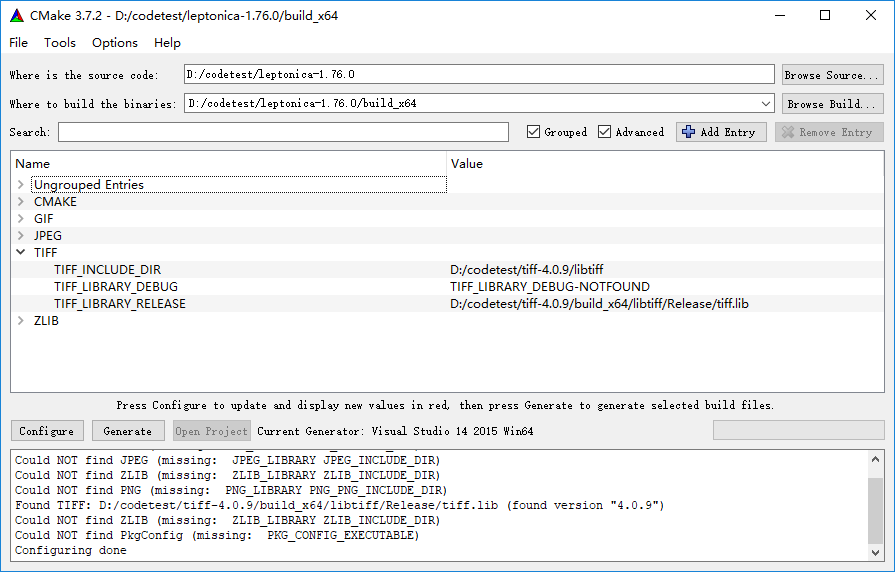
然后需要修改 libtiff目录下的两个头文件,将tiffconf.vc.h和tif_config.vc.h改名为tiffconf.h和tif_config.h

这样就能编译出leptonica的库文件了
- leptonica-1.76.0.lib,位置 D:\codetest\leptonica-1.76.0\build_x64\src\Release
- leptonica-1.76.0.dll,位置 D:\codetest\leptonica-1.76.0\build_x64\bin\Release
step3:编译tesseract
根目录的cmake配置文件在
if(NOT EXISTS ${PROJECT_SOURCE_DIR}/.cppan)这句话之前加上
set(Leptonica_DIR D:/codetest/leptonica-1.76.0/build_x64)
include_directories(
D:/codetest/leptonica-1.76.0/src
D:/codetest/leptonica-1.76.0/build_x64/src
)在configure的过程会出现如下日志,显示正在下载ICU的依赖,注意打开vpn,否则会因为网络问题不成功

之后,打开sln进行编译,一般情况下会出现一个字符编码的报错

此时不用惊慌,只需要将tesseract中equationdetect.cpp文件修改一下,再编译就好了
static const STRING kCharsToEx[] = {"'", "`", "\"", "\\", ",", ".",
"〈", "〉", "《", "》", "」", "「", ""}; 改为
static const STRING kCharsToEx[] = { "'", "`", "\"", "\\", ",", ".",
"<", ">", "<<", ">>", "" }; 然后顺利编译出tesseract项目的各种二进制工具exe,lib和dll
- tesseract305.lib,位置 D:\codetest\tesseract-3.05.01\build_x64\Release
- tesseract305.dll,位置 D:\codetest\tesseract-3.05.01\build_x64\bin\Release
- tesseract.exe,位置 D:\codetest\tesseract-3.05.01\build_x64\bin\Release
工具使用
在D:\codetest\tesseract-3.05.01\build_x64\bin\Release目录下,从源码目录将tessdata拷贝进去,并且提前下载好已训练语言包,另外,将用到的tiff和liptonica以及要识别的图片都拷贝进来
bmp格式原生支持,tif格式此时也是支持的,这里以tif图片为例

在这个目录输入命令行
tesseract eurotext.tif euro识别结果
euro.txt
The (quick) [brown] {fox} jumps!
Over the $43,456.78 <lazy> #90 dog
& duck/goose, as 12.5% of E-mail
from [email protected] is spam.
Der ,,schnelle” braune Fuchs springt
fiber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marrén répido salta sobre el perro
perezoso. A raposa marrom répida
salta sobre 0 C50 preguicoso.有些字符不是特别准确,还需要训练
编程使用
通过写代码调用tesseract的C++ api的形式
创建vs2015 C++工程
源码
main.cpp
#include "baseapi.h"
#include "allheaders.h"
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
// Initialize tesseract-ocr with English, without specifying tessdata path
if (api->Init(NULL, "eng"))
{
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
// Open input image with leptonica library
Pix *image = pixRead("./eurotext.tif");
api->SetImage(image);
// Get OCR result
outText = api->GetUTF8Text();
printf("---- OCR output:---- \n%s", outText);
// Destroy used object and release memory
api->End();
delete[] outText;
pixDestroy(&image);
return 0;
}配置
头文件包含目录
主要是leptonica和tesseract的src目录

附加库目录
需要配置leptonica和tesseract的lib路径

附加依赖项

运行
将项目依赖的tiff,leptonica,tesseract的dll全部拷贝到exe执行目录,并且拷贝tessdata和用到的图片到该目录

运行结果
---- OCR output:----
The (quick) [brown] {fox} jumps!
Over the $43,456.78 <lazy> #90 dog
& duck/goose, as 12.5% of E-mail
from [email protected] is spam.
Der ,,schnelle鈥?braune Fuchs springt
铿乥er den faulen Hund. Le renard brun
芦rapide禄 saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marr茅n r茅pido salta sobre el perro
perezoso. A raposa marrom r茅pida
salta sobre 0 C50 preguicoso.可以看出,api识别的结果还是有些不准确的,有待训练优化