今天学到的新单词:
assign v分派,分配
profile n侧面,轮廓
valid adj 有效的
invalid adj 无效的
syntax n语法
increment n增长,增量
下面的代码执行顺序是从右往左运行:
A = 12
生成对象
编程中特别消耗内存的操作是:
死循环,死锁,深层递归
蓝屏错误一般是硬件错误,原因如下:
1、内存条有问题。 检查内存条,如果坏了,更换内存条
2、双内存不兼容的问题。 使用同品牌的内存或只用一条内存
3、机箱内部散热的问题。 加强机箱内部的散热
4、硬盘有问题。 更换硬盘
5、驱动的问题。 重装驱动
6、软件之间有冲突。 如果最近安装了什么新软件,卸载了试试
7、病毒的问题。 杀毒
8、杀毒软件与系统或软件冲突。 卸载了试试
笔记本尽可能不用冷启动:
尽量用热启动,快捷键是:ctrl+alt+home/ctrl+alt+del,热启动不需要进行硬件自检
热启动是在不关闭电源的前提下重新启动计算机
开机是冷启动。重启是热启动
复位启动是指在计算机已经开启的状态下,按下主机箱面板上的复位按钮重新启动。
一般在计算机的运行状态出现异常,而热启动无效时才使用
**********************************************
python程序的运行过程是,python解释器首先向操作系统申请内存,然后需要执行的py文件再向
python解释器申请内存,解释器申请内存是防止程序运行过程中大量的使用内存导致系统因为内
存不足而死机和崩溃
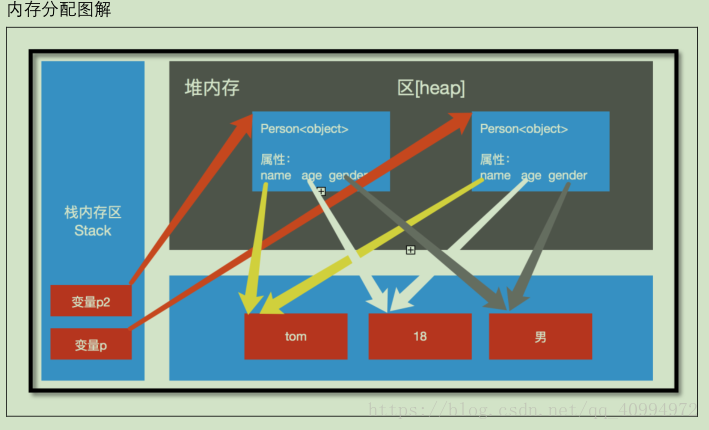
内存分析和处理:
为了提高内存的运行效率,解释器将内存分成了不同的分区,不同类型的
数据放在不同的分区中去运行,四个分区如下
stack:栈内存区
heap: 堆内存区 n堆,堆积
static:常量区/静态区
data:数据区/方法区
熟悉内存中的原理会增强程序员写代码时的第六感,会让你知道在写代码的时候怎么写更节省资源,python内内存分布如下:

*****************
PYTHON 中根据数据是否可以进行修改提供了两种不同的数据类型:
不可变数据类型:一般基本数据类型都是不可变数据类型
可变数据类型:一般组合数据类型或者自定义数据类都是可变数据类型
可变数据类型的特点:(组合数据类型的特点)
创建的对象内部的数据可以改变,但是指向的内存地址不会改变(1变是内部数据可以改变)
创建相同数据的可变数据类型对象,指向的地址是不一样的,因为创建的每一个可变数据类型的对象
都是独立的。(2变是具有相同数据的可变数据类型对象指向的内存地址是不一样的)
PYTHON 中的一切都是对象,可以通过 id()函数查询对象在内存中的地址数据
可变数据类型是在定义了数据之后,修改内部的数据,内存地址不会发生变化
不可变数据类型是在定义了数据之后,修改变量的数据,变量不会修改原来内存地址的数据
而是会指向新的地址,原有的数据保留,这样更加方便程序中基本数据的利用率
python对基本的数据类型进行了基本的优化操作:
-5-256之间的数据事先都已经存储在了常量区(static),也就是说无论把-5到256之间
的任何一个数赋给多个变量,这些变量指向的内存地址都是一样的,如果是超出该
范围的话变量会重新申请内存,所以超出该范围之后,赋相同的值给不同变量
这些变量指向的地址是不同的
如果是给一个变量赋一个字符串的话,该字符串会自动存储在常量区(static),如果再给其他
变量赋值相同的字符串的话,这些变量指向的内存地址也是一样的。
如果给一个变量定义一个字符串之后再删除该变量,用其他的变量继续定义该字符串,则变量指向
的字符串的地址是不会发生改变的。
代码和代码块:
PYTHON 中的最小运行单元是代码块,代码块的最小单元是一行代码
在实际开发过程中,需要注意的是 python 有两种操作方式
⚫ 交互模式
⚫ IDE 开发模式
在交互模式下,每行命令是一个独立运行的代码块,每个代码块运行会独立申请一次内存
IDE集成工具开发模式中,一个py文件是一个代码块,一个文件运行会申请一次内存,
所以在一个py文件中即使超出了-5到256这个范围,相同值赋给不同的变量,这些变量最后
指向的地址也是一样的
python提供了一个检测内存使用情况的模块memory_profiler:
同时python提供了一个比较强大的检测每一行代码对内存使用率的模块memory_profiler,是一个可视化的
能够比较直观的看到内存使用情况的工具模块,可在win终端通过pip工具直接安装即可:
pip install memory_profiler
#引入需要的模块
from memory_profile import profile
通过在测试的函数或者类型等前面添加@profile 注解,让内存分析模块可以直接进行代码
运行检测,然后通过列表的形式展示出来每行代码对内存的使用情况。
判断对象和对象的关系:
PYTHON 提供了对象判断符 is 和内容判断符==
A is B:判断对象 A 和对象 B 是否同一个内存地址,即是否同一个对象
A == B:判断 A 中的内容是否和 B 中的内容一致
isinstance(a, A)判断对象是否属于某一种类型
不论是基本类型的数据,还是内容复杂的对象,都可以通过对象判断符号 is 和内容判断操
作符号==来进行确定

可变数据类型的数据判断:

*****************
如果程序中多个不同的地方都要使用同一个对象怎么办?一共有三种解决方式:
1.对象的引用赋值
2.对象的浅拷贝
3.对象的深拷贝
1.首先对象的引用赋值是指:(只适用于可变的数据类型)
将对象的内存地址同时赋值给多个变量,多个变量指向的是同一个内存地址,
如果通过一个变量修改了对象内容,那么其他变量指向的对象内容也会同步发生改变,
多个变量指向的地址相同
*注意:PYTHON 中所谓对象的引用赋值,针对的是可变类型,不论是组合数据类型或者自定
义 class 类型,都具备引用赋值的操作;但是不适合不可变类型,不可变类型的引用赋值
操作有只读不写的特征,一旦通过变量重新赋值就会重新指向新的引用对象
自定义数据类型:就是自己写的类


2.对象的浅拷贝:
import copy
通过copy.copy()
a = ["a", "b"]
b = copy.copy(a) #将a变量的引用浅拷贝给b变量
浅拷贝的核心机制主要是复制对象内部数据的引用,多个变量指向的内容是相同的,但是指向的
地址是不同的,指向的是不同的对象,因为拷贝的是引用,所以a变量修改了对应的组合数据的值后,
b变量对应的对象的数据也会随着发生改变,修改基本数据类型的值后,b对象的值不随着发生改变。

3.对象的深拷贝:
import copy
a = ["a", "b"]
b = copy.deepcopy(a)
和对象的浅拷贝不同,对象的深拷贝,是对象数据的直接拷贝,而不是简单的引用拷贝
主要是通过 PYTHON 内建标准模块 copy 提供的 deepcopy 函数可以完成对象深拷贝
拷贝的是a变量对应的对象的所有数据,拷贝完之后是独立的一个对象,
所以a变量对象数据的改变不会影响b变量对象中的数据
