前言
本文只涉及分类树,而不涉及回归树,本文大部分内容均来自于李航博士的《统计学习方法》,在此基础上增加一些个人理解
正文
分类树假设决策树是一棵二叉树
分类树其实与决策树差不多,不同之处在于特征选择以及树的剪枝
决策树利用信息增益选择最优特征,分类树利用基尼指数选择最优特征
决策树的剪枝是在所生成的决策树递归地进行剪枝,分类树利用 的不同取值范围对分类树进行剪枝生成一系列子树,从子树中选取最优解
特征选择
分类树用基尼指数选择最优特征,同时决定该特征的最优二值切分点
注:
最优二值切分点
假设一个训练数据集为 ,特征为 ,最优二值切分点就是找到一个特征值 ,使得当 时,数据集 能够很好的归类
基尼指数
分类问题中,假设有
个类,样本点属于第
类的概率为
则概率分布的基尼指数定义为
注:
对于给定的样本集合 ,其基尼指数为
是 中属于第 类的样本子集, 是类的个数
如果样本集合
根据特征
是否取某一可能值
被分割成
和
两部分,即
则在特征 的条件下,集合 的基尼指数定义为
基尼指数 表示集合 的不确定性,基尼指数 表示经 分割后集合 的不确定性. 基尼指数越大,集合的不确定性也越大
CART生成算法
从根节点开始,递归地对每个结点进行一下操作
对于当前集合 ,计算现有特征对该数据的基尼指数
注:
要计算所有特征的所有可能取值对该数据的基尼指数选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点. 依据最优特征及最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点当中去
- 对两个子结点递归地调用1,2;直至满足停止条件
分类树的剪枝
分类树利用 的不同取值范围对分类树进行剪枝生成一系列子树,从子树中选取最优解
注:
的值是根据计算得来的,而不是随机设定的区域
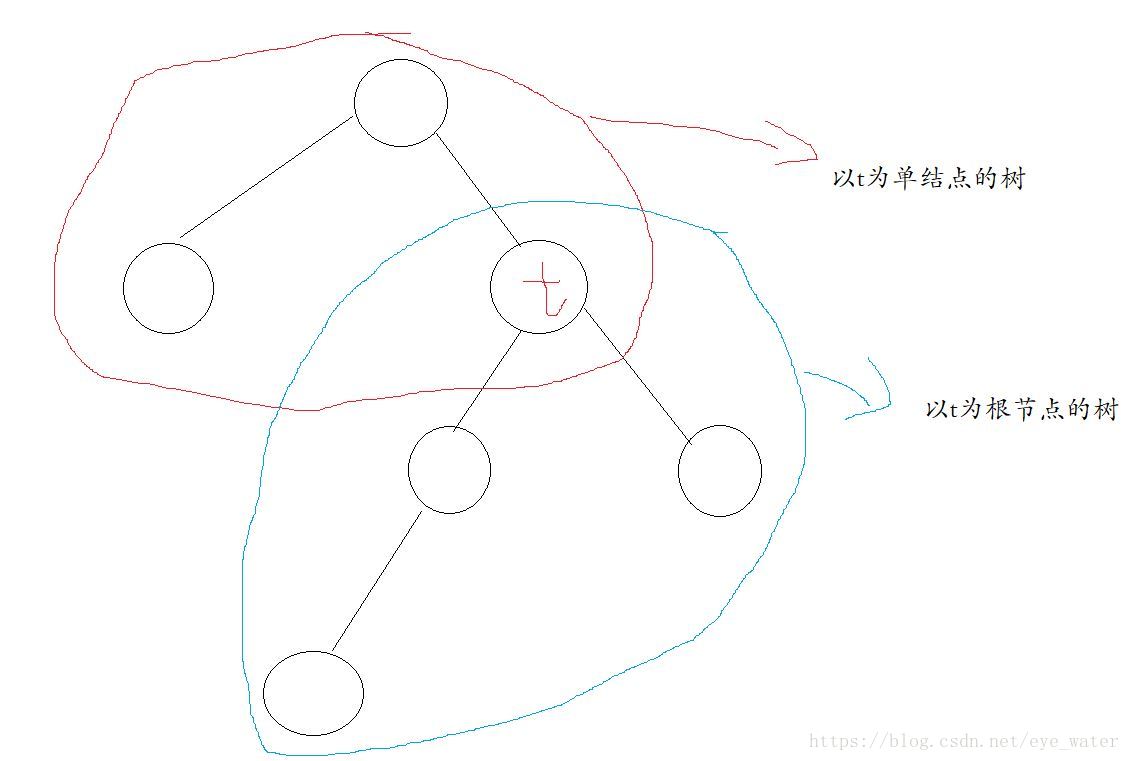
从整体数
开始剪枝,对
的内部任意结点
,以
为单结点的树的损失函数为
以 为根节点的子树 的损失函数是
当 或 很小时,有不等式
当 增大时,在某一 处有
当 继续增大时,有
这时,就可以进行剪枝操作
假设有一棵树
,对
中每一内部结点
, 计算
它表示剪枝后整体损失函数减少的程度. 在 中减去 最小的 ,得到的子树作为 ,同时将最小的 设为 . 为区间 的最优子树
对于子树 ,减去 最小的 ,得到的子树作为 ,同时将最小的 设为 , 为区间 的的最优子树
经过上面的操作我们能得到一个子树集合 ,即其对应的 值,这样就可以根据交叉验证选取最优子树
注:
当
的值增大时,为了得到更好的模型,模型的复杂度就会降低(复杂度降低就意味着剪枝),这样从剪枝后的子树集合中选择最好的模型就可以解决过度拟合问题
参考资料
[1]李航.决策树.统计学习方法.2012