1、背景知识
先看下HBase的组成:
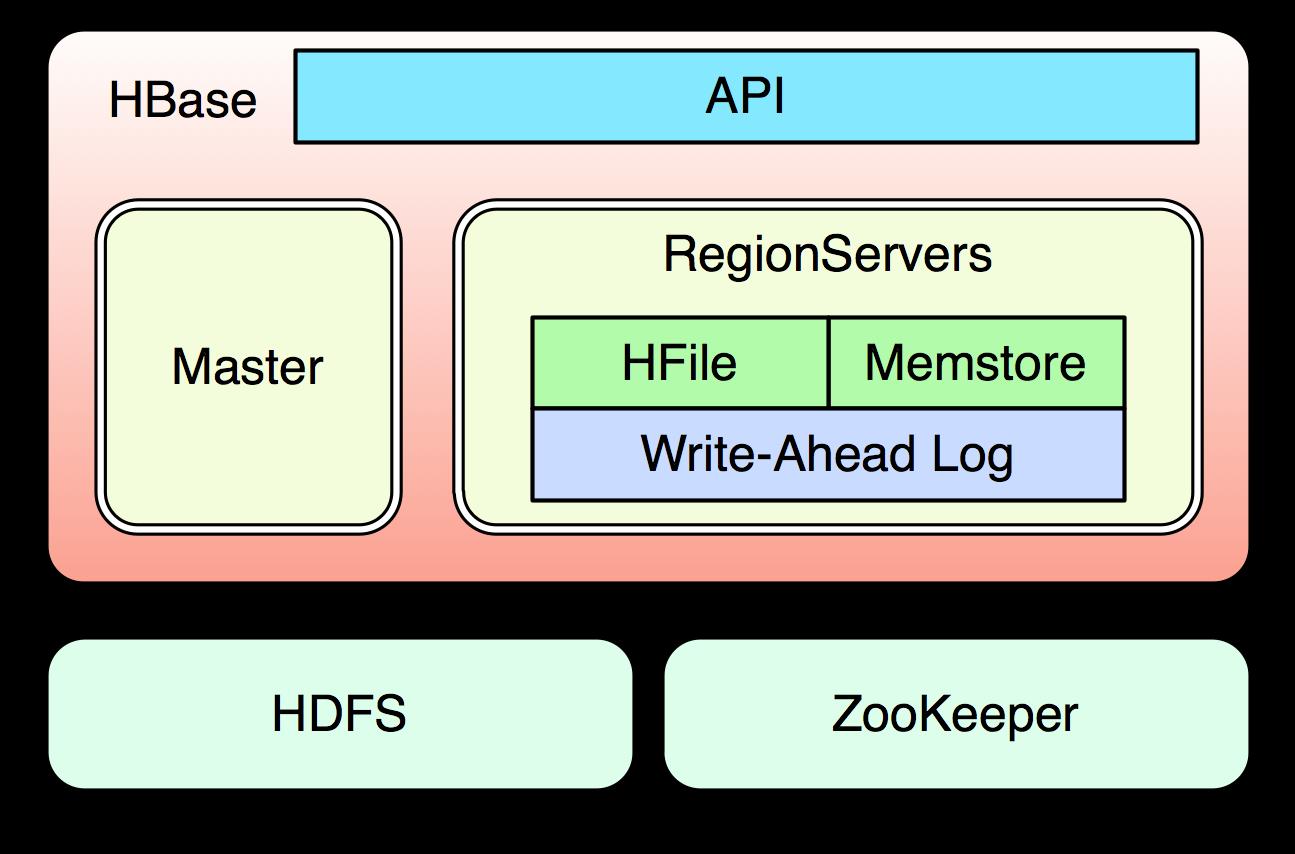
Master:Master主要负责管理RegionServer集群,如负载均衡及资源分配等,它本身也可以以集群方式运行,但同一时刻只有一个master处于激活状态。当工作中的master宕掉后,zookeeper会切换到其它备选的master上。
RegionServer:负责具体数据块的读写操作。
ZooKeeper:负责集群元数据的维护并监控集群的状态以防止单点故障。部署HBase时可以使用自带的ZooKeeper也可以使用独立的集群,是HBase跑起来的先决条件。
HDFS:写入HBase中的数据最终都持久化到了HDFS中,也是HBase运行的先决条件。
2、HDFS集群部署
HDFS由namenode和datanode组成,我们这里使用公有镜像,当然你也可以从DockerHub上pull合适的镜像再push到自己的私有仓库中。
然后创建如下hdfs.yaml文件:
apiVersion: v1
kind: Service
metadata:
name: hdfs-namenode-service # 设置服务名
namespace: cloudai-2 # 设置命名空间
spec:
selector:
app: hdfs-namenode # 根据label选择pod
type: ClusterIP # 表示只有集群内可以访问,只能通过集群ip访问
clusterIP: "10.233.8.10" # 固定集群ip,datanode链接时要用这个集群ip,所以要保障这个ip在集群ip范围内,并且没有被占用
ports:
- name: rpc
port: 4231 # # 设置namenode的端口号
targetPort: 8020
- name: p1
port: 50020
- name: p2
port: 50090
- name: p3
port: 50070
- name: p4
port: 50010
- name: p5
port: 50075
- name: p6
port: 8031
- name: p7
port: 8032
- name: p8
port: 8033
- name: p9
port: 8040
- name: p10
port: 8042
- name: p11
port: 49707
- name: p12
port: 22
- name: p13
port: 8088
- name: p14
port: 8030
---
apiVersion: v1
kind: ReplicationController # 复制控制器,和deployment一样的
metadata:
name: hdfs-namenode-1
namespace: cloudai-2
spec:
replicas: 1
template:
metadata:
labels:
app: hdfs-namenode # 设置pod的标签label
spec:
containers:
- name: hdfs-namenode # 设置容器名
image: bioshrek/hadoop-hdfs-namenode:cdh5 # 直接拉取公共镜像,也可以自己先拉下来传到私有仓库中
volumeMounts:
- name: data1
mountPath: /var/lib/hadoop-hdfs/cache/hdfs/dfs/name # 挂载,本地机器目录,存储namenode的信息,主要为datenode中数据库的位置信息。
- name: data2
mountPath: /cloudai2/hdfs/data/shared_with_docker_container/cdh5/namenode # nn为name
ports:
- containerPort: 50020
- containerPort: 50090
- containerPort: 50070
- containerPort: 50010
- containerPort: 50075
- containerPort: 8031
- containerPort: 8032
- containerPort: 8033
- containerPort: 8040
- containerPort: 8042
- containerPort: 49707
- containerPort: 22
- containerPort: 8088
- containerPort: 8030
- containerPort: 8020
nodeSelector:
kubernetes.io/hostname: node1 # 根据node的label标签选择主机。
volumes:
- hostPath:
path: /data1/kubernetes/hdfs-namenode/data1
name: data1
- hostPath:
path: /data1/kubernetes/hdfs-namenode/data2
name: data2
---
apiVersion: v1
kind: ReplicationController
metadata:
name: hdfs-datanode-1
namespace: cloudai-2
spec:
replicas: 1
template:
metadata:
labels:
app: hdfs-datanode
server-id: "1"
spec:
containers:
- name: hdfs-datanode-1
image: bioshrek/hadoop-hdfs-datanode:cdh5 # 直接拉取公共镜像,也可以自己先拉下来传到私有仓库中
volumeMounts:
- name: data1
mountPath: /var/lib/hadoop-hdfs/cache/hdfs/dfs/name # 设置name数据存储路径在本地的路径
- name: data2
mountPath: /cloudai2/hdfs/data/shared_with_docker_container/cdh5/datanode # 设置hdfs数据存储路径在本机的路径
env:
- name: HDFSNAMENODERPC_SERVICE_HOST
value: "10.233.8.10" # 设置namenode的ip
- name: HDFSNAMENODERPC_SERVICE_PORT
value: "4231" # 设置namenode的端口号
ports:
- containerPort: 50020
- containerPort: 50090
- containerPort: 50070
- containerPort: 50010
- containerPort: 50075
- containerPort: 8031
- containerPort: 8032
- containerPort: 8033
- containerPort: 8040
- containerPort: 8042
- containerPort: 49707
- containerPort: 22
- containerPort: 8088
- containerPort: 8030
- containerPort: 8020
nodeSelector:
kubernetes.io/hostname: node1 # 固定到指定节点上
volumes:
- hostPath:
path: /data1/kubernetes/hdfs-datanode1/data1
name: data1
- hostPath:
path: /data1/kubernetes/hdfs-datanode1/data2
name: data2
---
apiVersion: v1
kind: ReplicationController
metadata:
name: hdfs-datanode-2
namespace: cloudai-2
spec:
replicas: 1
template:
metadata:
labels:
app: hdfs-datanode # 设置pod的标签
server-id: "2"
spec:
containers:
- name: hdfs-datanode-2
image: bioshrek/hadoop-hdfs-datanode:cdh5
volumeMounts:
- name: data1
mountPath: /var/lib/hadoop-hdfs/cache/hdfs/dfs/name # 设置name数据存储路径在本地的路径
- name: data2
mountPath: /cloudai2/hdfs/data/shared_with_docker_container/cdh5/datanode # 设置hdfs数据存储路径在本机的路径
env:
- name: HDFSNAMENODERPC_SERVICE_HOST
value: "10.233.8.10" # 设置namenode的ip
- name: HDFSNAMENODERPC_SERVICE_PORT
value: "4231" # 设置namenode的端口号
ports:
- containerPort: 50020
- containerPort: 50090
- containerPort: 50070
- containerPort: 50010
- containerPort: 50075
- containerPort: 8031
- containerPort: 8032
- containerPort: 8033
- containerPort: 8040
- containerPort: 8042
- containerPort: 49707
- containerPort: 22
- containerPort: 8088
- containerPort: 8030
nodeSelector:
kubernetes.io/hostname: node1 # 固定到指定节点上
volumes:
- name: data1
hostPath:
path: /data2/kubernetes/hdfs-datanode2/data1
- name: data2
hostPath:
path: /data2/kubernetes/hdfs-datanode2/data2
---
apiVersion: v1
kind: ReplicationController
metadata:
name: hdfs-datanode-3
namespace: cloudai-2
spec:
replicas: 1
template:
metadata:
labels:
app: hdfs-datanode
server-id: "3"
spec:
containers:
- name: hdfs-datanode-3
image: bioshrek/hadoop-hdfs-datanode:cdh5
volumeMounts:
- name: data1
mountPath: /var/lib/hadoop-hdfs/cache/hdfs/dfs/name
- name: data2
mountPath: /cloudai2/hdfs/data/shared_with_docker_container/cdh5/datanode # 设置hdfs数据存储路径在本机的路径
env:
- name: HDFSNAMENODERPC_SERVICE_HOST
value: "10.233.8.10" # 设置namenode的ip
- name: HDFSNAMENODERPC_SERVICE_PORT
value: "4231" # 设置namenode的端口号
ports:
- containerPort: 50020
- containerPort: 50090
- containerPort: 50070
- containerPort: 50010
- containerPort: 50075
- containerPort: 8031
- containerPort: 8032
- containerPort: 8033
- containerPort: 8040
- containerPort: 8042
- containerPort: 49707
- containerPort: 22
- containerPort: 8088
- containerPort: 8030
nodeSelector:
kubernetes.io/hostname: node1 # 固定到指定节点上
volumes:
- name: data1
hostPath:
path: /data3/kubernetes/hdfs-datanode3/data1
- name: data2
hostPath:
path: /data3/kubernetes/hdfs-datanode3/data2通过 kubectl create -f hdfs.yaml 即创建一个名为hdfs-namenode-service的service,四个分别名为hdfs-namenode-1、hdfs-datanode-1、hdfs-datanode-2、hdfs-datanode-3的RC。通过 kubectl get services/rc/pods 可以看到对应的service和pod都已经正常启动了。
datanode的镜像中包含hdfs用户,并且只有该用户有操作hdfs分布式存储的权限。所以如果要向hdfs资源管理器中添加文件必须使用hdfs用户。但是由于hdfs用户在容器资源管理器中的权限不足,所以有时在本地创建文件,可能会权限不足。
下面对HDFS进行测试是否可以正常使用:
# 查看HDFS pods
kubectl get pods
# 通过describe查看pods跑在哪个k8s node上
kubectl describe pod hdfs-datanode-3-h4jvt
# 进入容器内部
docker ps | grep hdfs-datanode-3
docker exec -it 2e2c4df0c0a9 /bin/bash
# 创建本地文件
echo "Hello" > hello
设置777权限
chown 777 hello
# 切换至 hdfs 用户
su hdfs
# 创建hdfs文件系统中的目录
hadoop fs -mkdir /test
# 将本地文件复制到HDFS文件系统中
hadoop fs -put hello /test
# 查看HDFS中的文件信息
hadoop fs -ls /test
# 你已经在一个datanode里面想hdfs文件系统中加入了一个目录和文件,hdfs文件系统是分布式的。所以在其他的datanode的pod里面应该也能访问到,所以你可以 docker exec 到其它datanode中查看文件信息,如:
root@hdfs-datanode-1-nek2l:/# hadoop fs -ls /test
Found 1 items
-rw-r--r-- 2 hdfs hadoop 6 2015-11-27 08:36 /test/hello
删除hdfs目录
hadoop fs -rm -r /test
zookeeper集群部署
首先要知道zookeeper的配置文件
配置-zoo.cfg
这是zookeeper的主要配置文件,因为Zookeeper是一个集群服务,集群的每个节点都需要这个配置文件。为了避免出差错,zoo.cfg这个配置文件里没有跟特定节点相关的配置,所以每个节点上的这个zoo.cfg都是一模一样的配置。这样就非常便于管理了,比如我们可以把这个文件提交到版本控制里管理起来。其实这给我们设计集群系统的时候也是个提示:集群系统一般有很多配置,应该尽量将通用的配置和特定每个服务的配置(比如服务标识)分离,这样通用的配置在不同服务之间copy就ok了。ok,下面来介绍一些配置点:
clientPort=2181
client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。
dataDir=/data
dataLogDir=/datalog
dataLogDir如果没提供的话使用的则是dataDir。zookeeper的持久化都存储在这两个目录里。dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。
下面是集群中服务的列表
server.1=127.0.0.1:20881:30881
server.2=127.0.0.1:20882:30882
server.3=127.0.0.1:20883:30883
在上面的例子中,我把三个zookeeper服务放到同一台机器上。上面的配置中有两个TCP port。后面一个是用于Zookeeper选举用的,而前一个是Leader和Follower或Observer交换数据使用的。我们还注意到server.后面的数字。这个就是myid(关于myid是什么下一节会介绍)。
上面这几个是一些基本配置。
还有像 tickTime,这是个时间单位定量。比如tickTime=1000,这就表示在zookeeper里1 tick表示1000 ms,所有其他用到时间的地方都会用多少tick来表示。
比如 syncLimit = 2 就表示fowller与leader的心跳时间是2 tick。
maxClientCnxns – 对于一个客户端的连接数限制,默认是60,这在大部分时候是足够了。但是在我们实际使用中发现,在测试环境经常超过这个数,经过调查发现有的团队将几十个应用全部部署到一台机器上,以方便测试,于是这个数字就超过了。
minSessionTimeout, maxSessionTimeout – 一般,客户端连接zookeeper的时候,都会设置一个session timeout,如果超过这个时间client没有与zookeeper server有联系,则这个session会被设置为过期(如果这个session上有临时节点,则会被全部删除,这就是实现集群感知的基础,后面的文章会介绍这一点)。但是这个时间不是客户端可以无限制设置的,服务器可以设置这两个参数来限制客户端设置的范围。
autopurge.snapRetainCount,autopurge.purgeInterval – 客户端在与zookeeper交互过程中会产生非常多的日志,而且zookeeper也会将内存中的数据作为snapshot保存下来,这些数据是不会被自动删除的,这样磁盘中这样的数据就会越来越多。不过可以通过这两个参数来设置,让zookeeper自动删除数据。autopurge.purgeInterval就是设置多少小时清理一次。而autopurge.snapRetainCount是设置保留多少个snapshot,之前的则删除。
不过如果你的集群是一个非常繁忙的集群,然后又碰上这个删除操作,可能会影响zookeeper集群的性能,所以一般会让这个过程在访问低谷的时候进行,但是遗憾的是zookeeper并没有设置在哪个时间点运行的设置,所以有的时候我们会禁用这个自动删除的功能,而在服务器上配置一个cron,然后在凌晨来干这件事。
以上就是zoo.cfg里的一些配置了。下面就来介绍myid。
配置-myid
在dataDir里会放置一个myid文件,里面就一个数字,用来唯一标识这个服务。这个id是很重要的,一定要保证整个集群中唯一。zookeeper会根据这个id来取出server.x上的配置。比如当前id为1,则对应着zoo.cfg里的server.1的配置。
- 而且在后面我们介绍leader选举的时候,这个id的大小也是有意义的。
OK,上面就是配置的讲解了,现在我们可以启动zookeeper集群了。进入到bin目录,执行 ./zkServer.sh start即可。
这里使用的zoo.cfg 文件内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/opt/zookeeper/data
#This option will direct the machine to write the transaction log to the dataLogDir rather than the dataDir. This allows a dedicated log device to be used, and helps avoid competition between logging and snaphots.
dataLogDir=/opt/zookeeper/log
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1config-and-run.sh是zookeeper的启动脚本。是我们进入容器要运行的脚本。
config-and-run.sh 文件内容如下:
#!/bin/bash
echo "$SERVER_ID / $MAX_SERVERS"
if [ ! -z "$SERVER_ID" ] && [ ! -z "$MAX_SERVERS" ]; then
echo "Starting up in clustered mode"
echo "" >> /opt/zookeeper/conf/zoo.cfg
echo "#Server List" >> /opt/zookeeper/conf/zoo.cfg
for i in $( eval echo {1..$MAX_SERVERS});do
HostEnv="ZOOKEEPER_${i}_SERVICE_HOST"
HOST=${!HostEnv}
FollowerPortEnv="ZOOKEEPER_${i}_SERVICE_PORT_FOLLOWERS"
FOLLOWERPORT=${!FollowerPortEnv}
ElectionPortEnv="ZOOKEEPER_${i}_SERVICE_PORT_ELECTION"
ELECTIONPORT=${!ElectionPortEnv}
if [ "$SERVER_ID" = "$i" ];then
echo "server.$i=0.0.0.0:$FOLLOWERPORT:$ELECTIONPORT" >> /opt/zookeeper/conf/zoo.cfg
else
echo "server.$i=$HOST:$FOLLOWERPORT:$ELECTIONPORT" >> /opt/zookeeper/conf/zoo.cfg
fi
done
cat /opt/zookeeper/conf/zoo.cfg
# Persists the ID of the current instance of Zookeeper
echo ${SERVER_ID} > /opt/zookeeper/data/myid
else
echo "Starting up in standalone mode"
fi
exec /opt/zookeeper/bin/zkServer.sh start-foreground有了配置文件,我们就可以在zookeeper镜像的基础上将我们的配置文件添加进去。这样就是我们自定义的zookeeper镜像了。
在 fabric8/zookeeper 的image基础上进行修改,修改后Dockerfile文件内容如下:
这里遇到的主要问题是要修改zookeeper的下载地址,是的在国内可以安装。可以去http://mirror.bit.edu.cn/apache/zookeeper/上查看支持什么版本。
FROM jboss/base-jdk:7
USER root
ENV ZOOKEEPER_VERSION 3.4.10
EXPOSE 2181 2888 3888
RUN yum -y install wget bind-utils && yum clean all \
&& wget -q -O - http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-${ZOOKEEPER_VERSION}/zookeeper-${ZOOKEEPER_VERSION}.tar.gz | tar -xzf - -C /opt \
&& mv /opt/zookeeper-${ZOOKEEPER_VERSION} /opt/zookeeper \
&& cp /opt/zookeeper/conf/zoo_sample.cfg /opt/zookeeper/conf/zoo.cfg \
&& mkdir -p /opt/zookeeper/{data,log}
WORKDIR /opt/zookeeper
VOLUME ["/opt/zookeeper/conf", "/opt/zookeeper/data", "/opt/zookeeper/log"]
COPY config-and-run.sh ./bin/
COPY zoo.cfg ./conf/
CMD ["/opt/zookeeper/bin/config-and-run.sh"]修改完后创建镜像并push到私有仓库中,我这里推送到了在dockerhub上申请的私有仓库。
创建zookeeper.yaml文件在k8s上创建zookeeper集群:
apiVersion: v1
kind: Service
metadata:
name: zookeeper-1
namespace: cloudai-2 # 设置命名空间
labels:
name: zookeeper-1
spec:
ports:
- name: client
port: 2181
targetPort: 2181
- name: followers
port: 2888
targetPort: 2888
- name: election
port: 3888
targetPort: 3888
selector:
name: zookeeper
server-id: "1"
type: ClusterIP # 只能集群内部访问
clusterIP: 10.233.9.1 # 指定服务的集群ip,必须保障可用并且没有被占用
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-2
namespace: cloudai-2 # 设置命名空间
labels:
name: zookeeper-2
spec:
ports:
- name: client
port: 2181
targetPort: 2181
- name: followers
port: 2888
targetPort: 2888
- name: election
port: 3888
targetPort: 3888
selector:
name: zookeeper
server-id: "2"
type: ClusterIP
clusterIP: 10.233.9.2 # 指定服务的集群ip,必须保障可用并且没有被占用
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-3
namespace: cloudai-2 # 设置命名空间
labels:
name: zookeeper-3
spec:
ports:
- name: client
port: 2181
targetPort: 2181
- name: followers
port: 2888
targetPort: 2888
- name: election
port: 3888
targetPort: 3888
selector:
name: zookeeper
server-id: "3"
type: ClusterIP
clusterIP: 10.233.9.3 # 指定服务的集群ip,必须保障可用并且没有被占用
---
apiVersion: v1
kind: ReplicationController
metadata:
name: zookeeper-1
namespace: cloudai-2 # 设置命名空间
spec:
replicas: 1
template:
metadata:
labels:
name: zookeeper
server-id: "1"
spec:
volumes:
- hostPath:
path: /data1/kubernetes/zookeeper/data1
name: data
- hostPath:
path: /data1/kubernetes/zookeeper/log1
name: log
imagePullSecrets:
- name: hubsecret
containers:
- name: server
image: mldp/cloud:hbase-zookeeper-1.0.0
env:
- name: SERVER_ID
value: "1"
- name: MAX_SERVERS
value: "3"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: /opt/zookeeper/data
name: data
- mountPath: /opt/zookeeper/log
name: log
nodeSelector:
kubernetes.io/hostname: node1 # 根据node的label标签选择主机。
---
apiVersion: v1
kind: ReplicationController
metadata:
name: zookeeper-2
namespace: cloudai-2 # 设置命名空间
spec:
replicas: 1
template:
metadata:
labels:
name: zookeeper
server-id: "2"
spec:
volumes:
- hostPath:
path: /data1/kubernetes/zookeeper/data2
name: data
- hostPath:
path: /data1/kubernetes/zookeeper/log2
name: log
imagePullSecrets:
- name: hubsecret
containers:
- name: server
image: mldp/cloud:hbase-zookeeper-1.0.0
env:
- name: SERVER_ID
value: "2"
- name: MAX_SERVERS
value: "3"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: /opt/zookeeper/data
name: data
- mountPath: /opt/zookeeper/log
name: log
nodeSelector:
kubernetes.io/hostname: node1 # 根据node的label标签选择主机。
---
apiVersion: v1
kind: ReplicationController
metadata:
name: zookeeper-3
namespace: cloudai-2 # 设置命名空间
spec:
replicas: 1
template:
metadata:
labels:
name: zookeeper
server-id: "3"
spec:
volumes:
- hostPath:
path: /data1/kubernetes/zookeeper/data3
name: data
- hostPath:
path: /data1/kubernetes/zookeeper/log3
name: log
imagePullSecrets:
- name: hubsecret
containers:
- name: server
image: mldp/cloud:hbase-zookeeper-1.0.0
env:
- name: SERVER_ID
value: "3"
- name: MAX_SERVERS
value: "3"
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- mountPath: /opt/zookeeper/data
name: data
- mountPath: /opt/zookeeper/log
name: log
nodeSelector:
kubernetes.io/hostname: node1 # 根据node的label标签选择主机。通过 kubectl create -f zookeeper.yaml 创建三个service和对应的RC。注意container中已经把ZooKeeper的data和log目录映射到了主机的对应目录上用于持久化存储。
创建完之后即可进行测试:
# 进入zookeeper对应的容器后找到zkCli.sh,用该客户端进行测试
/opt/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0]
# 连接到k8s创建的zookeeper service (三个service任意一个都行)
[zk: localhost:2181(CONNECTED) 0] connect 172.16.11.2:2181
[zk: 10.233.9.2:2181(CONNECTED) 1]
# 查看目录信息
[zk: 10.233.9.2:2181(CONNECTED) 1] ls /
[zookeeper]
[zk: 10.233.9.2:2181(CONNECTED) 2] get /zookeeper
cZxid = 0x0
ctime = Thu Jan 01 00:00:00 UTC 1970
mZxid = 0x0
mtime = Thu Jan 01 00:00:00 UTC 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
[zk: 10.233.9.2:2181(CONNECTED) 3]HBASE集群部署
以上准备工作做好后,下面部署具有两个master和两个regionserver的HBase集群,其中两个master分别位于两个节点上,两个regionserver也分别位于两个节点上;使用独立的HDFS和ZooKeeper服务。
首先需要创建HBase的镜像,先去去https://mirrors.tuna.tsinghua.edu.cn/apache/hbase看看有什么版本的。这里我们用的是1.2.6.1
先编写配置文件hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>@HBASE_MASTER_PORT@</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>@HBASE_MASTER_INFO_PORT@</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>@HBASE_REGION_PORT@</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>@HBASE_REGION_INFO_PORT@</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://@HDFS_PATH@/@ZNODE_PARENT@</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>@ZOOKEEPER_IP_LIST@</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>@ZOOKEEPER_PORT@</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/@ZNODE_PARENT@</value>
</property>
</configuration>在编写配置文件start-k8s-hbase.sh
#!/bin/bash
export HBASE_CONF_FILE=/opt/hbase/conf/hbase-site.xml
export HADOOP_USER_NAME=hdfs
export HBASE_MANAGES_ZK=false
sed -i "s/@HBASE_MASTER_PORT@/$HBASE_MASTER_PORT/g" $HBASE_CONF_FILE
sed -i "s/@HBASE_MASTER_INFO_PORT@/$HBASE_MASTER_INFO_PORT/g" $HBASE_CONF_FILE
sed -i "s/@HBASE_REGION_PORT@/$HBASE_REGION_PORT/g" $HBASE_CONF_FILE
sed -i "s/@HBASE_REGION_INFO_PORT@/$HBASE_REGION_INFO_PORT/g" $HBASE_CONF_FILE
sed -i "s/@HDFS_PATH@/$HDFS_SERVICE:$HDFS_PORT\/$ZNODE_PARENT/g" $HBASE_CONF_FILE
sed -i "s/@ZOOKEEPER_IP_LIST@/$ZOOKEEPER_SERVICE_LIST/g" $HBASE_CONF_FILE
sed -i "s/@ZOOKEEPER_PORT@/$ZOOKEEPER_PORT/g" $HBASE_CONF_FILE
sed -i "s/@ZNODE_PARENT@/$ZNODE_PARENT/g" $HBASE_CONF_FILE
for i in ${HBASE_MASTER_LIST[@]}
do
arr=(${i//:/ })
echo "${arr[0]} ${arr[1]}" >> /etc/hosts
done
for i in ${HBASE_REGION_LIST[@]}
do
arr=(${i//:/ })
echo "${arr[0]} ${arr[1]}" >> /etc/hosts
done
if [ "$HBASE_SERVER_TYPE" = "master" ]; then
/opt/hbase/bin/hbase master start > logmaster.log 2>&1
elif [ "$HBASE_SERVER_TYPE" = "regionserver" ]; then
/opt/hbase/bin/hbase regionserver start > logregion.log 2>&1
fi其中导出HADOOP_USER_NAME为hdfs用户,否则会报Permission Denied的错误;HBASE_MANAGES_ZK=false表示不使用HBase自带的ZooKeeper;HBASE_MASTER_LIST为HBase集群中除当前master外的其余master的服务地址和pod名的对应关系;HBASE_REGION_LIST为HBase集群中除当前regionserver外的其余regionserver的服务地址和pod名的对应关系;最后根据 HBASE_SERVER_TYPE 的取值来确定是启master还是regionserver。
最后编写Dockerfile
FROM java:7
# 这里要去https://mirrors.tuna.tsinghua.edu.cn/apache/hbase看看有什么版本的
ENV HBASE_VERSION 1.2.6.1
ENV HBASE_INSTALL_DIR /opt/hbase
# 配置环境变量
ENV JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
# 下载解压hbase到指定目录
RUN mkdir -p ${HBASE_INSTALL_DIR} && \
curl -L https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/${HBASE_VERSION}/hbase-${HBASE_VERSION}-bin.tar.gz | tar -xz --strip=1 -C ${HBASE_INSTALL_DIR}
# 复制配置文件进入
ADD hbase-site.xml /opt/hbase/conf/hbase-site.xml
ADD start-k8s-hbase.sh /opt/hbase/bin/start-k8s-hbase.sh
RUN chmod +x /opt/hbase/bin/start-k8s-hbase.sh
WORKDIR /opt/hbase/bin
ENV PATH=$PATH:/opt/hbase/bin
CMD /opt/hbase/bin/start-k8s-hbase.sh镜像生成后将镜像上传到私有仓库,我这里直接上传到自己的dockerhub
docker build -t hbase:1.0.0 .
docker tag hbase:1.0.0 mldp/cloud:hbase-1.0.0
docker push mldp/cloud:hbase-1.0.0编写yaml文件。在k8s上部署
apiVersion: v1
kind: Service
metadata:
name: hbase-master-1
namespace: cloudai-2 # 设置命名空间
spec:
selector:
app: hbase-master
server-id: "1"
type: ClusterIP
clusterIP: "10.233.9.11" # 指定集群ip,固定ip为了能在后面更好的绑定上
ports:
- name: rpc
port: 60000
targetPort: 60000
- name: info
port: 60001
targetPort: 60001
---
apiVersion: v1
kind: Service
metadata:
name: hbase-master-2
namespace: cloudai-2 # 设置命名空间
spec:
selector:
app: hbase-master
server-id: "2"
type: ClusterIP
clusterIP: "10.233.9.12" # 指定集群ip,固定ip为了能在后面更好的绑定上
ports:
- name: rpc
port: 60000
targetPort: 60000
- name: info
port: 60001
targetPort: 60001
---
apiVersion: v1
kind: Service
metadata:
name: hbase-region-1
namespace: cloudai-2 # 设置命名空间
spec:
selector:
app: hbase-region
server-id: "1"
type: ClusterIP
clusterIP: "10.233.9.13" # 指定集群ip,固定ip为了能在后面更好的绑定上
ports:
- name: rpc
port: 60010
targetPort: 60010
- name: info
port: 60011
targetPort: 60011
---
apiVersion: v1
kind: Service
metadata:
name: hbase-region-2
namespace: cloudai-2 # 设置命名空间
spec:
selector:
app: hbase-region
server-id: "2"
type: ClusterIP
clusterIP: "10.233.9.14" # 指定集群ip,固定ip为了能在后面更好的绑定上
ports:
- name: rpc
port: 60010
targetPort: 60010
- name: info
port: 60011
targetPort: 60011
---
apiVersion: v1
kind: Pod
metadata:
namespace: cloudai-2 # 设置命名空间
name: hbase-master-1
labels:
app: hbase-master
server-id: "1"
spec:
imagePullSecrets:
- name: hubsecret # 镜像拉取秘钥
containers:
- name: hbase-master-1
image: mldp/cloud:hbase-1.0.0
ports:
- containerPort: 60000
- containerPort: 60001
env:
- name: HBASE_SERVER_TYPE # hbase角色类型。根据 HBASE_SERVER_TYPE 的取值来确定是启master还是regionserver
value: master
- name: HBASE_MASTER_PORT # hbase的master端口号
value: "60000"
- name: HBASE_MASTER_INFO_PORT # hbase的master信息端口号
value: "60001"
- name: HBASE_REGION_PORT # hbase的region端口号
value: "60010"
- name: HBASE_REGION_INFO_PORT # hbase的region的信息端口号
value: "60011"
- name: HDFS_SERVICE # hdfs服务,HDFS_SERVICE为HDFS服务经过skyDNS之后的对应域名,若未设置skyDNS则此处值设为HDFS服务对应的IP地址
value: "10.233.8.10" # hdfs的集群ip
- name: HDFS_PORT # hdfs端口号
value: "4231"
- name: ZOOKEEPER_SERVICE_LIST # zookeeper列表,域名,同HDFS_SERVICE意义
value: "10.233.9.1,10.233.9.2,10.233.9.3" # zookeeper集群ip
- name: ZOOKEEPER_PORT # zookeeper端口号
value: "2181"
- name: ZNODE_PARENT # znode_parent
value: hbase
- name: HBASE_MASTER_LIST # 为HBase集群中除当前master外的其余master的服务地址和pod名的对应关系。格式为 <master服务IP地址>:<master对应Pod名>,多个项之间以空格分隔
value: "10.233.9.12:hbase-master-2"
- name: HBASE_REGION_LIST # 为HBase集群中除当前regionserver外的其余regionserver的服务地址和pod名的对应关系
value: "10.233.9.13:hbase-region-1 10.233.9.14:hbase-region-2"
restartPolicy: Always # 表示如果该Pod挂掉的话将一直尝试重新启动它
nodeSelector:
kubernetes.io/hostname: node1 # 选择部署的主机,两个master的pod部署在不同的机器上。才能防止宕机
---
apiVersion: v1
kind: Pod
metadata:
namespace: cloudai-2 # 设置命名空间
name: hbase-master-2
labels:
app: hbase-master
server-id: "2"
spec:
imagePullSecrets:
- name: hubsecret
containers:
- name: hbase-master-1
image: mldp/cloud:hbase-1.0.0
ports:
- containerPort: 60000
- containerPort: 60001
env:
- name: HBASE_SERVER_TYPE
value: master
- name: HBASE_MASTER_PORT
value: "60000"
- name: HBASE_MASTER_INFO_PORT
value: "60001"
- name: HBASE_REGION_PORT
value: "60010"
- name: HBASE_REGION_INFO_PORT
value: "60011"
- name: HDFS_SERVICE
value: "10.233.8.10"
- name: HDFS_PORT
value: "4231"
- name: ZOOKEEPER_SERVICE_LIST
value: "10.233.9.1,10.233.9.2,10.233.9.3"
- name: ZOOKEEPER_PORT
value: "2181"
- name: ZNODE_PARENT
value: hbase
- name: HBASE_MASTER_LIST
value: "10.233.9.11:hbase-master-1"
- name: HBASE_REGION_LIST
value: "10.233.9.13:hbase-region-1 10.233.9.14:hbase-region-2"
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: node2 # 选择部署的主机,两个master的pod部署在不同的机器上。才能防止宕机
---
apiVersion: v1
kind: Pod
metadata:
namespace: cloudai-2 # 设置命名空间
name: hbase-region-1
labels:
app: hbase-region-1
server-id: "1"
spec:
imagePullSecrets:
- name: hubsecret
containers:
- name: hbase-region-1
image: mldp/cloud:hbase-1.0.0
ports:
- containerPort: 60010
- containerPort: 60011
env:
- name: HBASE_SERVER_TYPE
value: regionserver
- name: HBASE_MASTER_PORT
value: "60000"
- name: HBASE_MASTER_INFO_PORT
value: "60001"
- name: HBASE_REGION_PORT
value: "60010"
- name: HBASE_REGION_INFO_PORT
value: "60011"
- name: HDFS_SERVICE
value: "10.233.8.10"
- name: HDFS_PORT
value: "4231"
- name: ZOOKEEPER_SERVICE_LIST
value: "10.233.9.1,10.233.9.2,10.233.9.3"
- name: ZOOKEEPER_PORT
value: "2181"
- name: ZNODE_PARENT
value: hbase
- name: HBASE_MASTER_LIST
value: "10.233.9.11:hbase-master-1 10.233.9.12:hbase-master-2"
- name: HBASE_REGION_LIST
value: "10.233.9.14:hbase-region-2"
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: node1 # 选择部署的主机,两个region的pod部署在不同的机器上。才能防止宕机
---
apiVersion: v1
kind: Pod
metadata:
namespace: cloudai-2 # 设置命名空间
name: hbase-region-2
labels:
app: hbase-region-2
server-id: "2"
spec:
imagePullSecrets:
- name: hubsecret
containers:
- name: hbase-region-2
image: mldp/cloud:hbase-1.0.0
ports:
- containerPort: 60010
- containerPort: 60011
env:
- name: HBASE_SERVER_TYPE
value: regionserver
- name: HBASE_MASTER_PORT
value: "60000"
- name: HBASE_MASTER_INFO_PORT
value: "60001"
- name: HBASE_REGION_PORT
value: "60010"
- name: HBASE_REGION_INFO_PORT
value: "60011"
- name: HDFS_SERVICE
value: "10.233.8.10"
- name: HDFS_PORT
value: "4231"
- name: ZOOKEEPER_SERVICE_LIST
value: "10.233.9.1,10.233.9.2,10.233.9.3"
- name: ZOOKEEPER_PORT
value: "2181"
- name: ZNODE_PARENT
value: hbase
- name: HBASE_MASTER_LIST
value: "10.233.9.11:hbase-master-1 10.233.9.12:hbase-master-2"
- name: HBASE_REGION_LIST
value: "10.233.9.13:hbase-region-1"
restartPolicy: Always
nodeSelector:
kubernetes.io/hostname: node2 # 选择部署的主机,两个region的pod部署在不同的机器上。才能防止宕机选择使用单Pod而不是ReplicationController,是因为k8s会在RC中Container的hostname后面加上随机字符以区分彼此,而单Pod的Pod name和hostname是一致的;restartPolicy设为Always算是为单Pod方式鲁棒性提供点小小的补偿吧;如果将Pod name设置为对应service的IP或域名怎样?然而hostname并不允许带点号;写入 /etc/hosts 中的IP选择了service的而非Pod的,因为Pod中的IP在运行前并不能获取到,而且在重启Pod后也会发生改变,而service的IP是不变的,因此选择了 serviceIP:PodName 这种对应关系。
说明:该yaml文件共创建了两个master服务、两个regionserver服务,以及对应的两个master Pods和两个regionserver Pods;Pod的restartPolicy设为Always表示如果该Pod挂掉的话将一直尝试重新启动它;以环境变量的形式将参数传递进Pod中,其中HDFS_SERVICE为HDFS服务经过skyDNS之后的对应域名,若未设置skyDNS则此处值设为HDFS服务对应的IP地址,ZOOKEEPER_SERVICE_LIST同理;HBASE_MASTER_LIST的值格式为
# 创建
$kubectl create -f hbase.yaml
service "hbase-master-1" created
service "hbase-master-2" created
service "hbase-region-1" created
service "hbase-region-2" created
pod "hbase-master-1" created
pod "hbase-master-2" created
pod "hbase-region-1" created
pod "hbase-region-2" created
# 查看pods
$kubectl get pods
。。。
# 查看service
$kubectl get service
。。。可以通过docker exec进入到HBase对应的容器中进行表操作以测试HBase的工作状态:
# 进入node2的hbase-master-2容器中
[@bx_42_198 /opt/scs/openxxs]# docker exec -it f131fcf15a72 /bin/bash
# 使用hbase shell对hbase进行操作
[root@hbase-master-2 bin]# hbase shell
2015-11-30 15:15:58,632 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.10.1-hadoop2, rd5014b47660a58485a6bdd0776dea52114c7041e, Tue Feb 10 11:34:09 PST 2015
# 通过status查看状态,这里显示的 2 dead 是之前测试时遗留的记录,无影响
hbase(main):001:0> status
2015-11-30 15:16:03,551 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
servers, 2 dead, 1.5000 average load
# 创建表
hbase(main):002:0> create 'test','id','name'
row(s) in 0.8330 seconds
=> Hbase::Table - test
# 查看表
hbase(main):003:0> list
TABLE
member
test
row(s) in 0.0240 seconds
=> ["member", "test"]
# 插入数据
hbase(main):004:0> put 'test','test1','id:5','addon'
row(s) in 0.1540 seconds
# 查看数据
hbase(main):005:0> get 'test','test1'
COLUMN CELL
id:5 timestamp=1448906130803, value=addon
row(s) in 0.0490 seconds
# 进入199的hbase-master-1容器中查看从198上插入的数据
hbase(main):001:0> get 'test','test1'
2015-11-30 18:01:23,944 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
COLUMN CELL
id:5 timestamp=1448906130803, value=addon
row(s) in 0.2430 seconds